 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtroversion or Introversion? Controlling The Personality of Your Large Language Models
Paper and Code
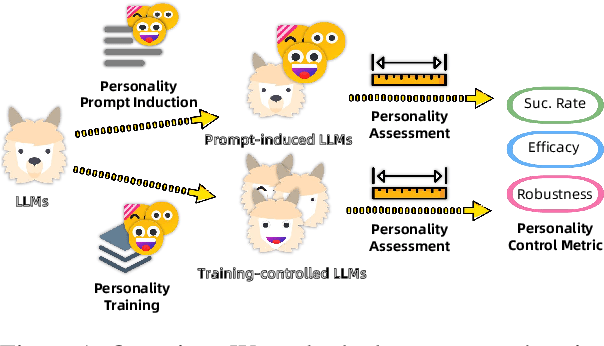
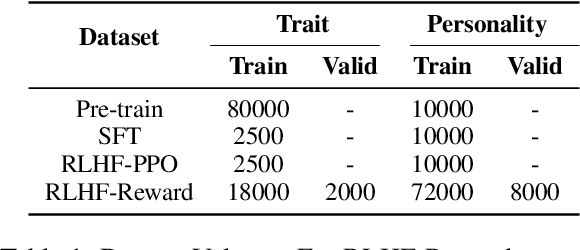
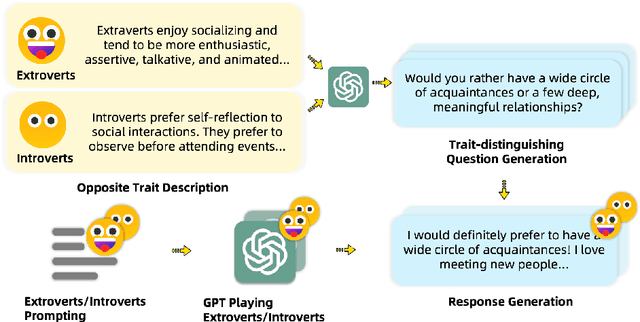

Large language models (LLMs) exhibit robust capabilities in text generation and comprehension, mimicking human behavior and exhibiting synthetic personalities. However, some LLMs have displayed offensive personality, propagating toxic discourse. Existing literature neglects the origin and evolution of LLM personalities, as well as the effective personality control. To fill these gaps, our study embarked on a comprehensive investigation into LLM personality control. We investigated several typical methods to influence LLMs, including three training methods: Continual Pre-training, Supervised Fine-Tuning (SFT), and Reinforcement Learning from Human Feedback (RLHF), along with inference phase considerations (prompts). Our investigation revealed a hierarchy of effectiveness in control: Prompt > SFT > RLHF > Continual Pre-train. Notably, SFT exhibits a higher control success rate compared to prompt induction. While prompts prove highly effective, we found that prompt-induced personalities are less robust than those trained, making them more prone to showing conflicting personalities under reverse personality prompt induction. Besides, harnessing the strengths of both SFT and prompt, we proposed $\underline{\text{P}}$rompt $\underline{\text{I}}$nduction post $\underline{\text{S}}$upervised $\underline{\text{F}}$ine-tuning (PISF), which emerges as the most effective and robust strategy for controlling LLMs' personality, displaying high efficacy, high success rates, and high robustness. Even under reverse personality prompt induction, LLMs controlled by PISF still exhibit stable and robust personalities.