 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffBench Meets DiffAgent: End-to-End LLM-Driven Diffusion Acceleration Code Generation
Jan 06, 2026Diffusion models have achieved remarkable success in image and video generation. However, their inherently multiple step inference process imposes substantial computational overhead, hindering real-world deployment. Accelerating diffusion models is therefore essential, yet determining how to combine multiple model acceleration techniques remains a significant challenge. To address this issue, we introduce a framework driven by large language models (LLMs) for automated acceleration code generation and evaluation. First, we present DiffBench, a comprehensive benchmark that implements a three stage automated evaluation pipeline across diverse diffusion architectures, optimization combinations and deployment scenarios. Second, we propose DiffAgent, an agent that generates optimal acceleration strategies and codes for arbitrary diffusion models. DiffAgent employs a closed-loop workflow in which a planning component and a debugging component iteratively refine the output of a code generation component, while a genetic algorithm extracts performance feedback from the execution environment to guide subsequent code refinements. We provide a detailed explanation of the DiffBench construction and the design principles underlying DiffAgent. Extensive experiments show that DiffBench offers a thorough evaluation of generated codes and that DiffAgent significantly outperforms existing LLMs in producing effective diffusion acceleration strategies.
Semantic Hierarchical Prompt Tuning for Parameter-Efficient Fine-Tuning
Dec 24, 2024



As the scale of vision models continues to grow, Visual Prompt Tuning (VPT) has emerged as a parameter-efficient transfer learning technique, noted for its superior performance compared to full fine-tuning. However, indiscriminately applying prompts to every layer without considering their inherent correlations, can cause significant disturbances, leading to suboptimal transferability. Additionally, VPT disrupts the original self-attention structure, affecting the aggregation of visual features, and lacks a mechanism for explicitly mining discriminative visual features, which are crucial for classification. To address these issues, we propose a Semantic Hierarchical Prompt (SHIP) fine-tuning strategy. We adaptively construct semantic hierarchies and use semantic-independent and semantic-shared prompts to learn hierarchical representations. We also integrate attribute prompts and a prompt matching loss to enhance feature discrimination and employ decoupled attention for robustness and reduced inference costs. SHIP significantly improves performance, achieving a 4.9% gain in accuracy over VPT with a ViT-B/16 backbone on VTAB-1k tasks. Our code is available at https://github.com/haoweiz23/SHIP.
Improving Robustness for Pose Estimation via Stable Heatmap Regression
May 08, 2021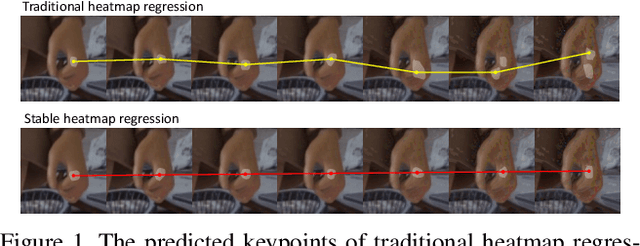

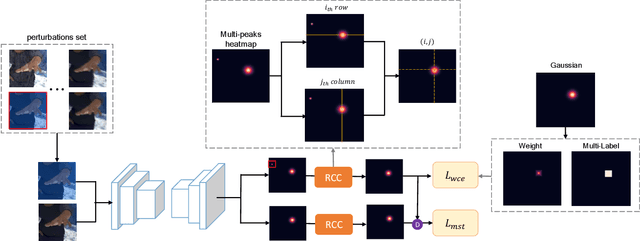

Deep learning methods have achieved excellent performance in pose estimation, but the lack of robustness causes the keypoints to change drastically between similar images. In view of this problem, a stable heatmap regression method is proposed to alleviate network vulnerability to small perturbations. We utilize the correlation between different rows and columns in a heatmap to alleviate the multi-peaks problem, and design a highly differentiated heatmap regression to make a keypoint discriminative from surrounding points. A maximum stability training loss is used to simplify the optimization difficulty when minimizing the prediction gap of two similar images. The proposed method achieves a significant advance in robustness over state-of-the-art approaches on two benchmark datasets and maintains high performance.
Switching Gradient Directions for Query-Efficient Black-Box Adversarial Attacks
Sep 15, 2020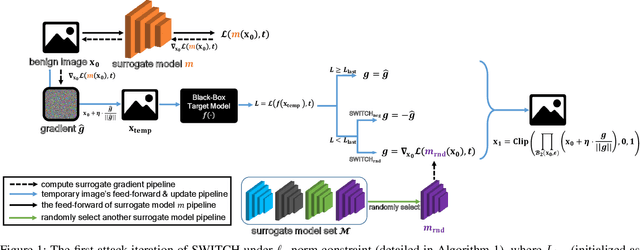
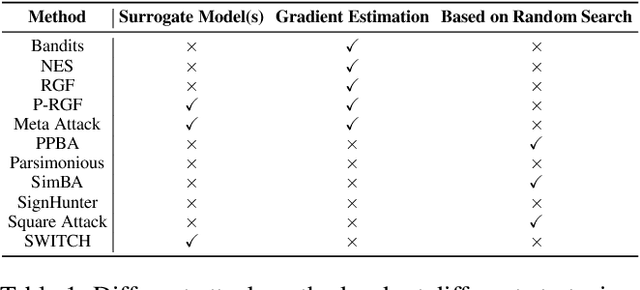
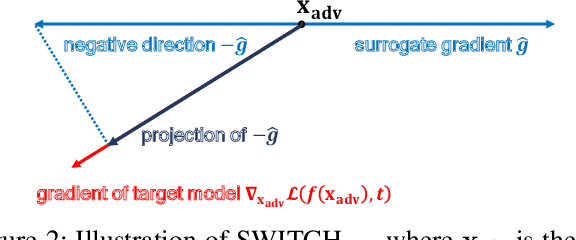
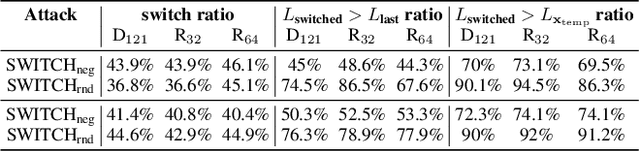
We propose a simple and highly query-efficient black-box adversarial attack named SWITCH, which has a state-of-the-art performance under $\ell_2$ and $\ell_\infty$ norms in the score-based setting. In the black box attack setting, designing query-efficient attacks remains an open problem. The high query efficiency of the proposed approach stems from the combination of transfer-based attacks and random-search-based ones. The surrogate model's gradient $\hat{\mathbf{g}}$ is exploited for the guidance, which is then switched if our algorithm detects that it does not point to the adversarial region by using a query, thereby keeping the objective loss function of the target model rising as much as possible. Two switch operations are available, i.e., SWITCH$_\text{neg}$ and SWITCH$_\text{rnd}$. SWITCH$_\text{neg}$ takes $-\hat{\mathbf{g}}$ as the new direction, which is reasonable under an approximate local linearity assumption. SWITCH$_\text{rnd}$ computes the gradient from another model, which is randomly selected from a large model set, to help bypass the potential obstacle in optimization. Experimental results show that these strategies boost the optimization process whereas following the original surrogate gradients does not work. In SWITCH, no query is used to estimate the gradient, and all the queries aim to determine whether to switch directions, resulting in unprecedented query efficiency. We demonstrate that our approach outperforms 10 state-of-the-art attacks on CIFAR-10, CIFAR-100 and TinyImageNet datasets. SWITCH can serve as a strong baseline for future black-box attacks. The PyTorch source code is released in https://github.com/machanic/SWITCH .
MetaSimulator: Simulating Unknown Target Models for Query-Efficient Black-box Attacks
Sep 02, 2020
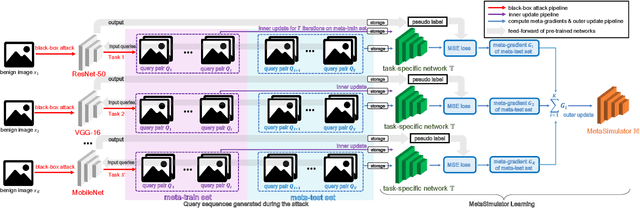

Many adversarial attacks have been proposed to investigate the security issues of deep neural networks. For the black-box setting, current model stealing attacks train a substitute model to counterfeit the functionality of the target model. However, the training requires querying the target model. Consequently, the query complexity remains high and such attacks can be defended easily by deploying the defense mechanism. In this study, we aim to learn a generalized substitute model called MetaSimulator that can mimic the functionality of the unknown target models. To this end, we build the training data with the form of multi-tasks by collecting query sequences generated in the attack of various existing networks. The learning consists of a double-network framework, including the task-specific network and MetaSimulator network, to learn the general simulation capability. Specifically, the task-specific network computes each task's meta-gradient, which is further accumulated from multiple tasks to update MetaSimulator to improve generalization. When attacking a target model that is unseen in training, the trained MetaSimulator can simulate its functionality accurately using its limited feedback. As a result, a large fraction of queries can be transferred to MetaSimulator in the attack, thereby reducing the high query complexity. Comprehensive experiments conducted on CIFAR-10, CIFAR-100, and TinyImageNet datasets demonstrate the proposed approach saves twice the number of queries on average compared with the baseline method. The source code is released on https://github.com/machanic/MetaSimulator .
Self-Paced Video Data Augmentation with Dynamic Images Generated by Generative Adversarial Networks
Sep 16, 2019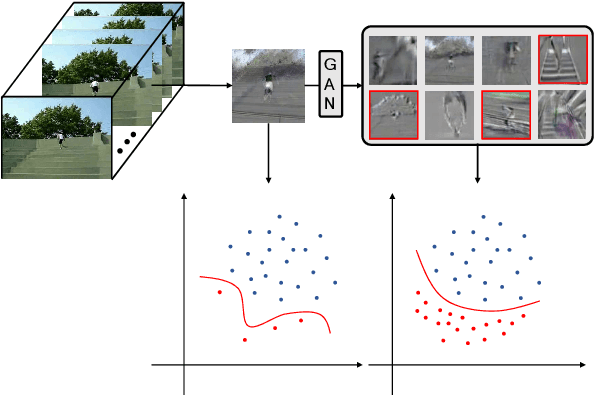

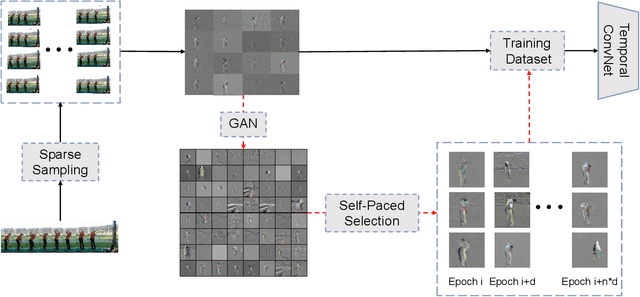
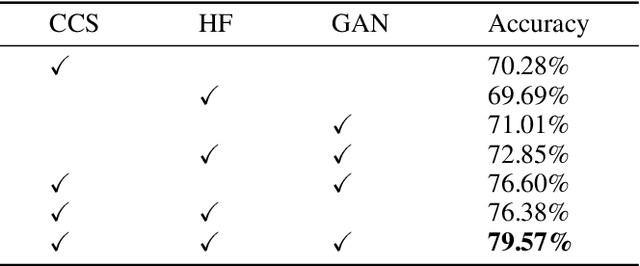
There is an urgent need for an effective video classification method by means of a small number of samples. The deficiency of samples could be effectively alleviated by generating samples through Generative Adversarial Networks (GAN), but the generation of videos on a typical category remains to be underexplored since the complex actions and the changeable viewpoints are difficult to simulate. In this paper, we propose a generative data augmentation method for temporal stream of the Temporal Segment Networks with the dynamic image. The dynamic image compresses the motion information of video into a still image, removing the interference factors such as the background. Thus it is easier to generate images with categorical motion information using GAN. We use the generated dynamic images to enhance the features, with regularization achieved as well, thereby to achieve the effect of video augmentation. In order to deal with the uneven quality of generated images, we propose a Self-Paced Selection (SPS) method, which automatically selects the high-quality generated samples to be added to the network training. Our method is verified on two benchmark datasets, HMDB51 and UCF101. The experimental results show that the method can improve the accuracy of video classification under the circumstance of sample insufficiency and sample imbalance.
Adaptive Wasserstein Hourglass for Weakly Supervised Hand Pose Estimation from Monocular RGB
Sep 11, 2019
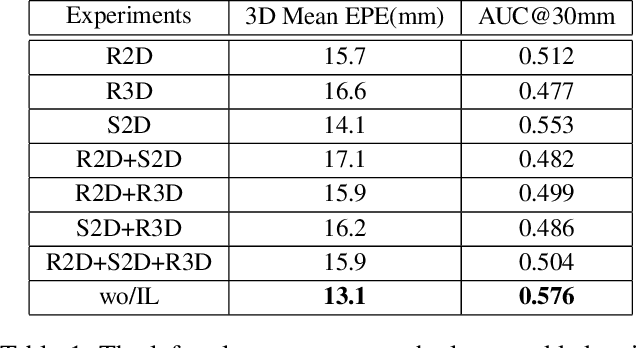
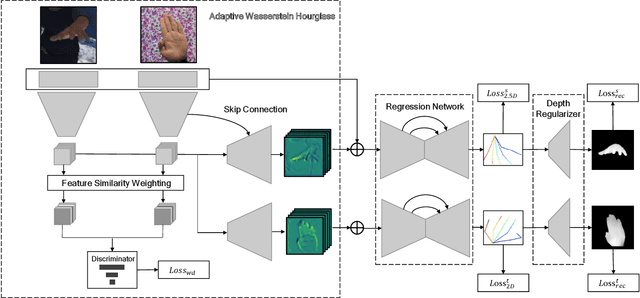

Insufficient labeled training datasets is one of the bottlenecks of 3D hand pose estimation from monocular RGB images. Synthetic datasets have a large number of images with precise annotations, but the obvious difference with real-world datasets impacts the generalization. Little work has been done to bridge the gap between two domains over their wide difference. In this paper, we propose a domain adaptation method called Adaptive Wasserstein Hourglass (AW Hourglass) for weakly-supervised 3D hand pose estimation, which aims to distinguish the difference and explore the common characteristics (e.g. hand structure) of synthetic and real-world datasets. Learning the common characteristics helps the network focus on pose-related information. The similarity of the characteristics makes it easier to enforce domain-invariant constraints. During training, based on the relation between these common characteristics and 3D pose learned from fully-annotated synthetic datasets, it is beneficial for the network to restore the 3D pose of weakly labeled real-world datasets with the aid of 2D annotations and depth images. While in testing, the network predicts the 3D pose with the input of RGB.
MetaAdvDet: Towards Robust Detection of Evolving Adversarial Attacks
Aug 06, 2019
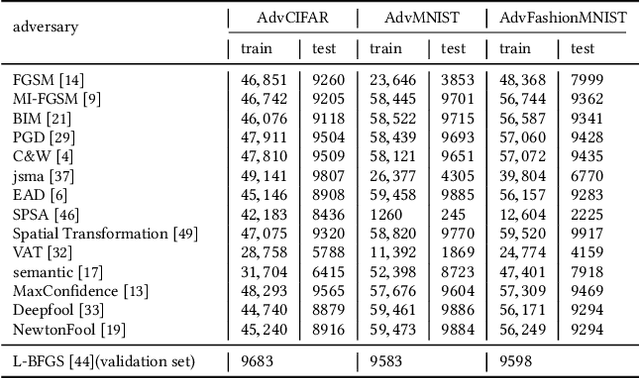


Deep neural networks (DNNs) are vulnerable to adversarial attack which is maliciously implemented by adding human-imperceptible perturbation to images and thus leads to incorrect prediction. Existing studies have proposed various methods to detect the new adversarial attacks. However, new attack methods keep evolving constantly and yield new adversarial examples to bypass the existing detectors. It needs to collect tens of thousands samples to train detectors, while the new attacks evolve much more frequently than the high-cost data collection. Thus, this situation leads the newly evolved attack samples to remain in small scales. To solve such few-shot problem with the evolving attack, we propose a meta-learning based robust detection method to detect new adversarial attacks with limited examples. Specifically, the learning consists of a double-network framework: a task-dedicated network and a master network which alternatively learn the detection capability for either seen attack or a new attack. To validate the effectiveness of our approach, we construct the benchmarks with few-shot-fashion protocols based on three conventional datasets, i.e. CIFAR-10, MNIST and Fashion-MNIST. Comprehensive experiments are conducted on them to verify the superiority of our approach with respect to the traditional adversarial attack detection methods.
DenseAttentionSeg: Segment Hands from Interacted Objects Using Depth Input
Apr 23, 2019

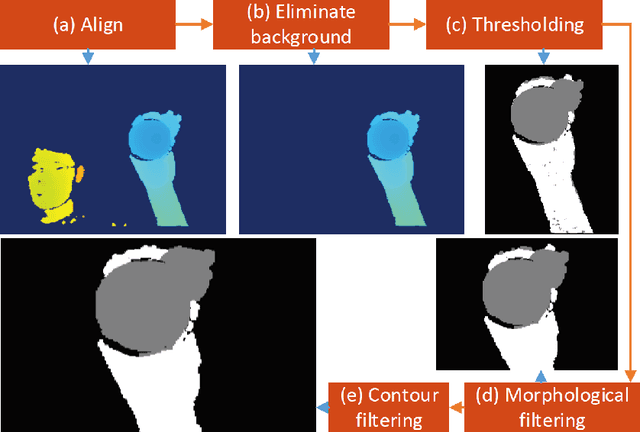

We propose a real-time DNN-based technique to segment hand and object of interacting motions from depth inputs. Our model is called DenseAttentionSeg, which contains a dense attention mechanism to fuse information in different scales and improves the results quality with skip-connections. Besides, we introduce a contour loss in model training, which helps to generate accurate hand and object boundaries. Finally, we propose and release our InterSegHands dataset, a fine-scale hand segmentation dataset containing about 52k depth maps of hand-object interactions. Our experiments evaluate the effectiveness of our techniques and datasets, and indicate that our method outperforms the current state-of-the-art deep segmentation methods on interaction segmentation.
AU R-CNN: Encoding Expert Prior Knowledge into R-CNN for Action Unit Detection
Dec 14, 2018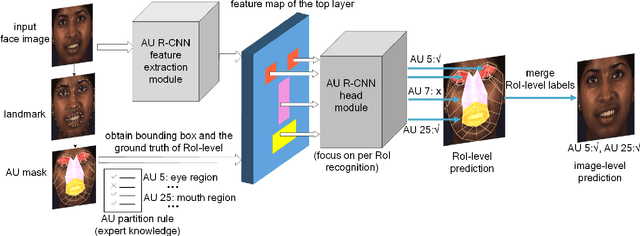
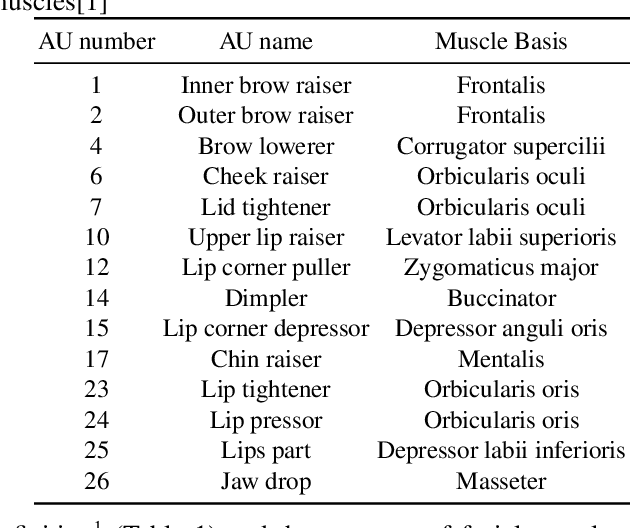
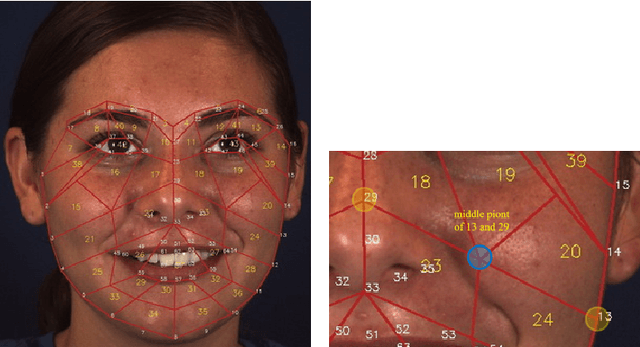
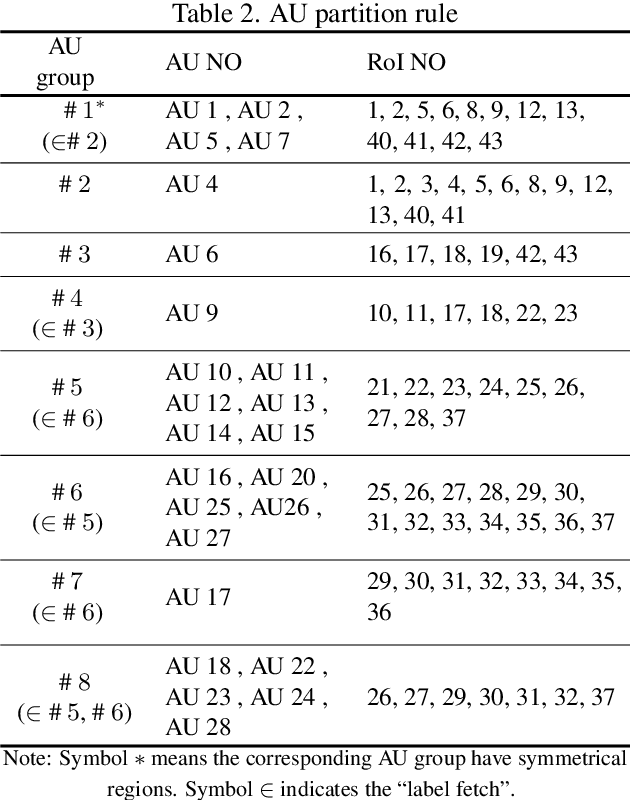
Modeling action units (AUs) on human faces is challenging because various AUs cause subtle facial appearance changes over various regions at different scales. Current works have attempted to recognize AUs by emphasizing important regions. However, the incorporation of prior knowledge into region definition remains under-exploited, and current AU detection systems do not use regional convolutional neural networks (R-CNN) with expert prior knowledge to directly focus on AU-related regions adaptively. By incorporating expert prior knowledge, we propose a novel R-CNN based model named AU R-CNN. The proposed solution offers two main contributions: (1) AU R-CNN directly observes different facial regions, where various AUs are located. Expert prior knowledge is encoded in the region and the RoI-level label definition. This design produces considerably better detection performance than do existing approaches. (2) We also integrate various dynamic models (including convolutional long short-term memory, two stream network, conditional random field, and temporal action localization network) into AU R-CNN and then investigate and analyze the reason behind the performance of dynamic models. Experiment results demonstrate that only static RGB image information and no optical flow-based AU R-CNN surpasses the one fused with dynamic models. AU R-CNN is also superior to traditional CNNs that use the same backbone on varying image resolutions. State-of-the-art recognition performance of AU detection is achieved. The complete network is end-to-end trainable. Experiments on BP4D and DISFA datasets show the effectiveness of our approach. Code will be made available.