 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAU R-CNN: Encoding Expert Prior Knowledge into R-CNN for Action Unit Detection
Paper and Code
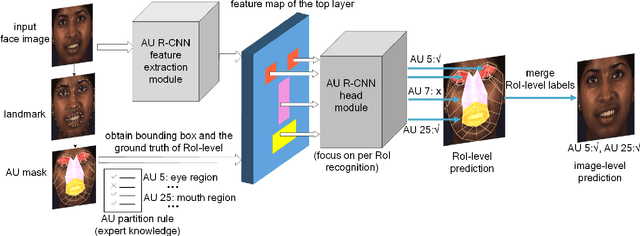
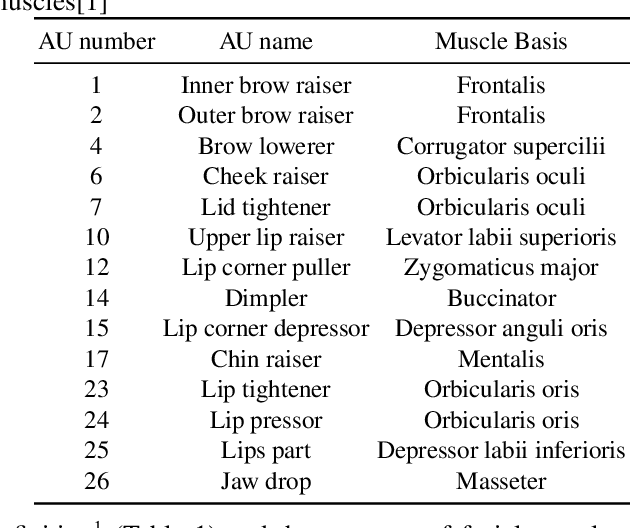
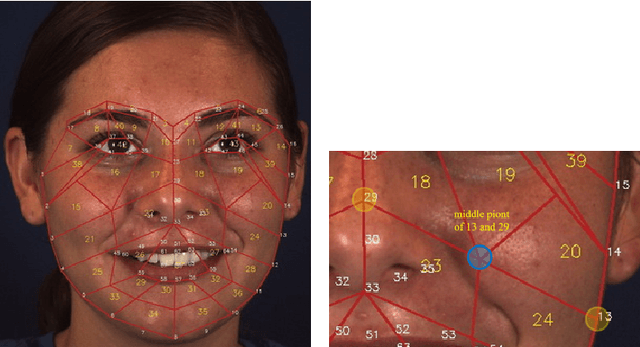
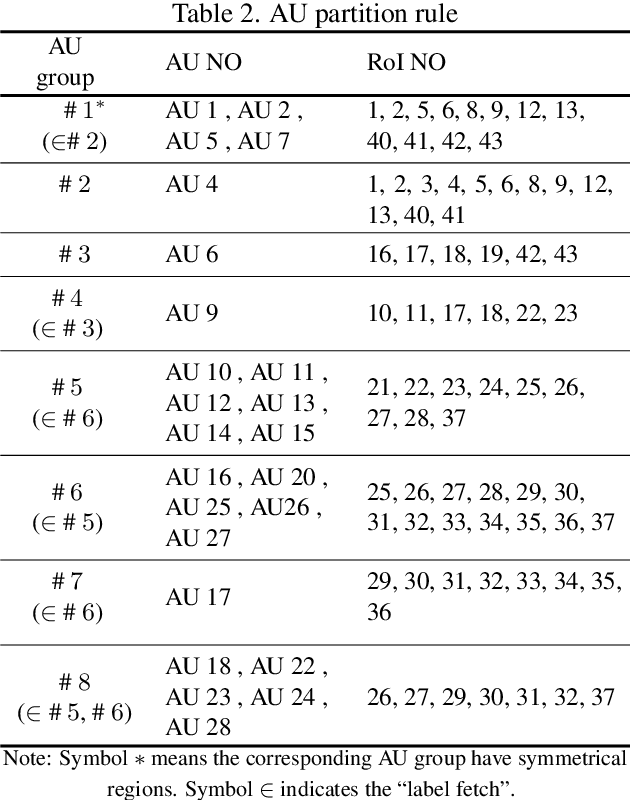
Modeling action units (AUs) on human faces is challenging because various AUs cause subtle facial appearance changes over various regions at different scales. Current works have attempted to recognize AUs by emphasizing important regions. However, the incorporation of prior knowledge into region definition remains under-exploited, and current AU detection systems do not use regional convolutional neural networks (R-CNN) with expert prior knowledge to directly focus on AU-related regions adaptively. By incorporating expert prior knowledge, we propose a novel R-CNN based model named AU R-CNN. The proposed solution offers two main contributions: (1) AU R-CNN directly observes different facial regions, where various AUs are located. Expert prior knowledge is encoded in the region and the RoI-level label definition. This design produces considerably better detection performance than do existing approaches. (2) We also integrate various dynamic models (including convolutional long short-term memory, two stream network, conditional random field, and temporal action localization network) into AU R-CNN and then investigate and analyze the reason behind the performance of dynamic models. Experiment results demonstrate that only static RGB image information and no optical flow-based AU R-CNN surpasses the one fused with dynamic models. AU R-CNN is also superior to traditional CNNs that use the same backbone on varying image resolutions. State-of-the-art recognition performance of AU detection is achieved. The complete network is end-to-end trainable. Experiments on BP4D and DISFA datasets show the effectiveness of our approach. Code will be made available.