 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Convergence Rate of Ray Search Optimization for Query-Efficient Hard-Label Attacks
Dec 24, 2025In hard-label black-box adversarial attacks, where only the top-1 predicted label is accessible, the prohibitive query complexity poses a major obstacle to practical deployment. In this paper, we focus on optimizing a representative class of attacks that search for the optimal ray direction yielding the minimum $\ell_2$-norm perturbation required to move a benign image into the adversarial region. Inspired by Nesterov's Accelerated Gradient (NAG), we propose a momentum-based algorithm, ARS-OPT, which proactively estimates the gradient with respect to a future ray direction inferred from accumulated momentum. We provide a theoretical analysis of its convergence behavior, showing that ARS-OPT enables more accurate directional updates and achieves faster, more stable optimization. To further accelerate convergence, we incorporate surrogate-model priors into ARS-OPT's gradient estimation, resulting in PARS-OPT with enhanced performance. The superiority of our approach is supported by theoretical guarantees under standard assumptions. Extensive experiments on ImageNet and CIFAR-10 demonstrate that our method surpasses 13 state-of-the-art approaches in query efficiency.
Boosting Ray Search Procedure of Hard-label Attacks with Transfer-based Priors
Jul 23, 2025One of the most practical and challenging types of black-box adversarial attacks is the hard-label attack, where only the top-1 predicted label is available. One effective approach is to search for the optimal ray direction from the benign image that minimizes the $\ell_p$-norm distance to the adversarial region. The unique advantage of this approach is that it transforms the hard-label attack into a continuous optimization problem. The objective function value is the ray's radius, which can be obtained via binary search at a high query cost. Existing methods use a "sign trick" in gradient estimation to reduce the number of queries. In this paper, we theoretically analyze the quality of this gradient estimation and propose a novel prior-guided approach to improve ray search efficiency both theoretically and empirically. Specifically, we utilize the transfer-based priors from surrogate models, and our gradient estimators appropriately integrate them by approximating the projection of the true gradient onto the subspace spanned by these priors and random directions, in a query-efficient manner. We theoretically derive the expected cosine similarities between the obtained gradient estimators and the true gradient, and demonstrate the improvement achieved by incorporating priors. Extensive experiments on the ImageNet and CIFAR-10 datasets show that our approach significantly outperforms 11 state-of-the-art methods in terms of query efficiency.
Efficient Black-box Adversarial Attacks via Bayesian Optimization Guided by a Function Prior
May 29, 2024This paper studies the challenging black-box adversarial attack that aims to generate adversarial examples against a black-box model by only using output feedback of the model to input queries. Some previous methods improve the query efficiency by incorporating the gradient of a surrogate white-box model into query-based attacks due to the adversarial transferability. However, the localized gradient is not informative enough, making these methods still query-intensive. In this paper, we propose a Prior-guided Bayesian Optimization (P-BO) algorithm that leverages the surrogate model as a global function prior in black-box adversarial attacks. As the surrogate model contains rich prior information of the black-box one, P-BO models the attack objective with a Gaussian process whose mean function is initialized as the surrogate model's loss. Our theoretical analysis on the regret bound indicates that the performance of P-BO may be affected by a bad prior. Therefore, we further propose an adaptive integration strategy to automatically adjust a coefficient on the function prior by minimizing the regret bound. Extensive experiments on image classifiers and large vision-language models demonstrate the superiority of the proposed algorithm in reducing queries and improving attack success rates compared with the state-of-the-art black-box attacks. Code is available at https://github.com/yibo-miao/PBO-Attack.
Query-Efficient Black-box Adversarial Attacks Guided by a Transfer-based Prior
Mar 13, 2022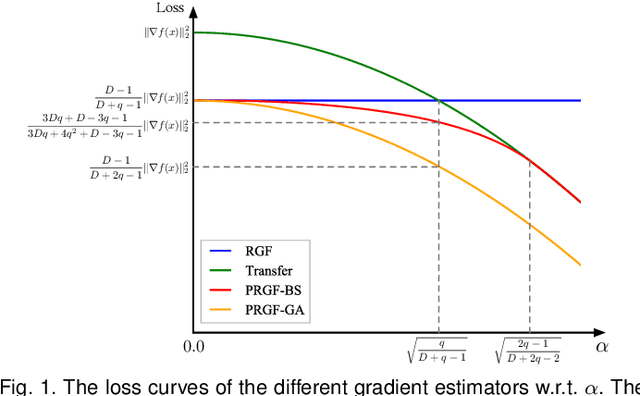
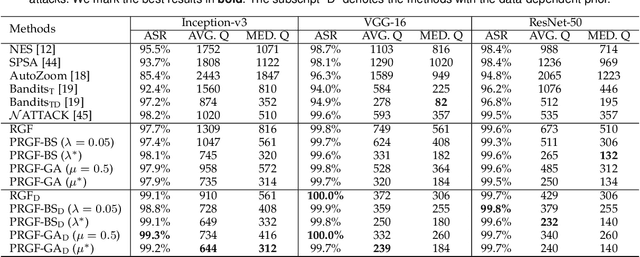
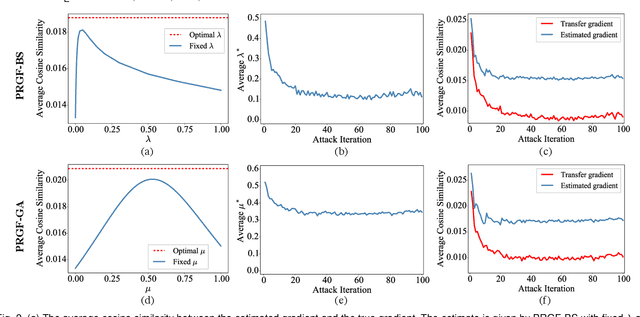
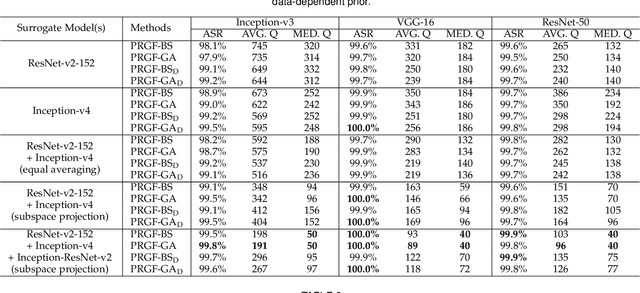
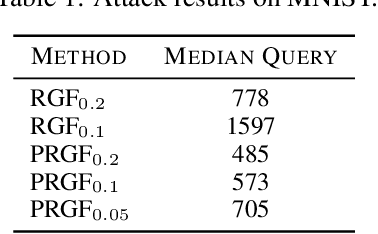
Adversarial attacks have been extensively studied in recent years since they can identify the vulnerability of deep learning models before deployed. In this paper, we consider the black-box adversarial setting, where the adversary needs to craft adversarial examples without access to the gradients of a target model. Previous methods attempted to approximate the true gradient either by using the transfer gradient of a surrogate white-box model or based on the feedback of model queries. However, the existing methods inevitably suffer from low attack success rates or poor query efficiency since it is difficult to estimate the gradient in a high-dimensional input space with limited information. To address these problems and improve black-box attacks, we propose two prior-guided random gradient-free (PRGF) algorithms based on biased sampling and gradient averaging, respectively. Our methods can take the advantage of a transfer-based prior given by the gradient of a surrogate model and the query information simultaneously. Through theoretical analyses, the transfer-based prior is appropriately integrated with model queries by an optimal coefficient in each method. Extensive experiments demonstrate that, in comparison with the alternative state-of-the-arts, both of our methods require much fewer queries to attack black-box models with higher success rates.
On the Convergence of Prior-Guided Zeroth-Order Optimization Algorithms
Jul 21, 2021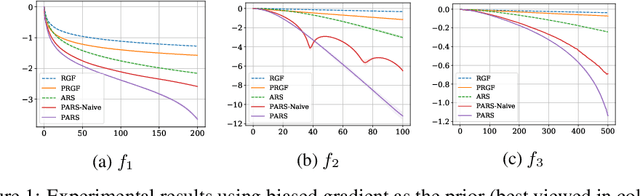
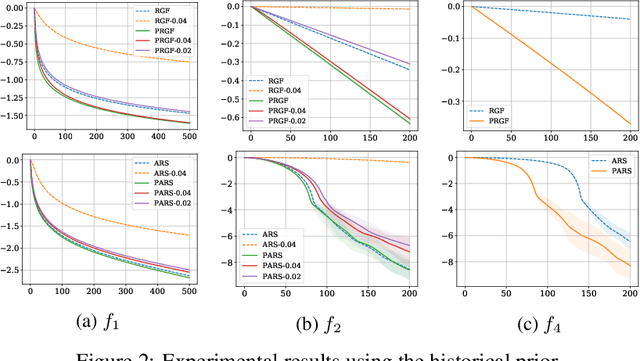
Zeroth-order (ZO) optimization is widely used to handle challenging tasks, such as query-based black-box adversarial attacks and reinforcement learning. Various attempts have been made to integrate prior information into the gradient estimation procedure based on finite differences, with promising empirical results. However, their convergence properties are not well understood. This paper makes an attempt to fill this gap by analyzing the convergence of prior-guided ZO algorithms under a greedy descent framework with various gradient estimators. We provide a convergence guarantee for the prior-guided random gradient-free (PRGF) algorithms. Moreover, to further accelerate over greedy descent methods, we present a new accelerated random search (ARS) algorithm that incorporates prior information, together with a convergence analysis. Finally, our theoretical results are confirmed by experiments on several numerical benchmarks as well as adversarial attacks.
Switching Gradient Directions for Query-Efficient Black-Box Adversarial Attacks
Sep 15, 2020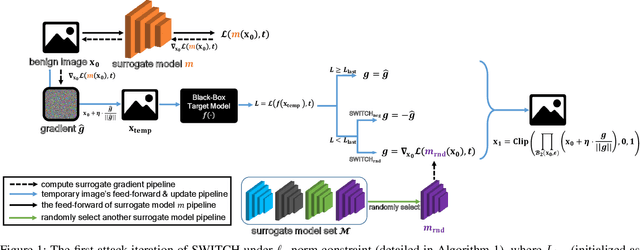
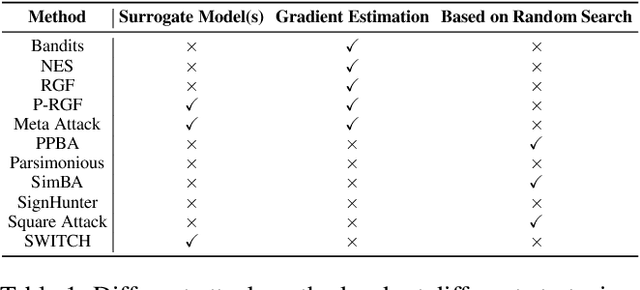
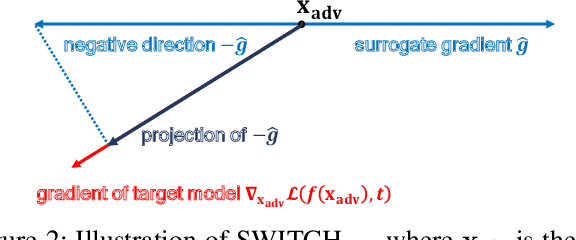
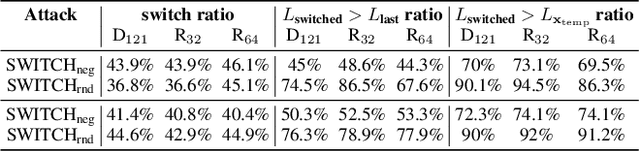
We propose a simple and highly query-efficient black-box adversarial attack named SWITCH, which has a state-of-the-art performance under $\ell_2$ and $\ell_\infty$ norms in the score-based setting. In the black box attack setting, designing query-efficient attacks remains an open problem. The high query efficiency of the proposed approach stems from the combination of transfer-based attacks and random-search-based ones. The surrogate model's gradient $\hat{\mathbf{g}}$ is exploited for the guidance, which is then switched if our algorithm detects that it does not point to the adversarial region by using a query, thereby keeping the objective loss function of the target model rising as much as possible. Two switch operations are available, i.e., SWITCH$_\text{neg}$ and SWITCH$_\text{rnd}$. SWITCH$_\text{neg}$ takes $-\hat{\mathbf{g}}$ as the new direction, which is reasonable under an approximate local linearity assumption. SWITCH$_\text{rnd}$ computes the gradient from another model, which is randomly selected from a large model set, to help bypass the potential obstacle in optimization. Experimental results show that these strategies boost the optimization process whereas following the original surrogate gradients does not work. In SWITCH, no query is used to estimate the gradient, and all the queries aim to determine whether to switch directions, resulting in unprecedented query efficiency. We demonstrate that our approach outperforms 10 state-of-the-art attacks on CIFAR-10, CIFAR-100 and TinyImageNet datasets. SWITCH can serve as a strong baseline for future black-box attacks. The PyTorch source code is released in https://github.com/machanic/SWITCH .
A Wasserstein Minimum Velocity Approach to Learning Unnormalized Models
Feb 18, 2020
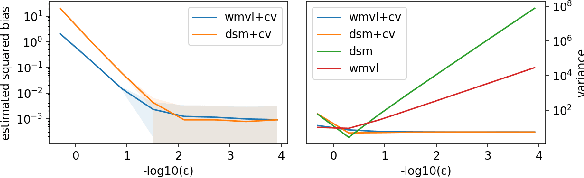
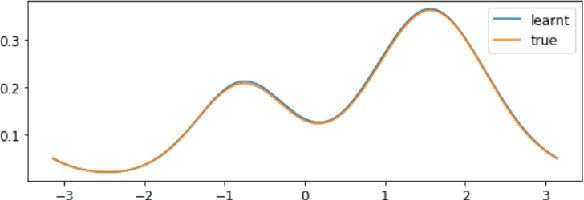
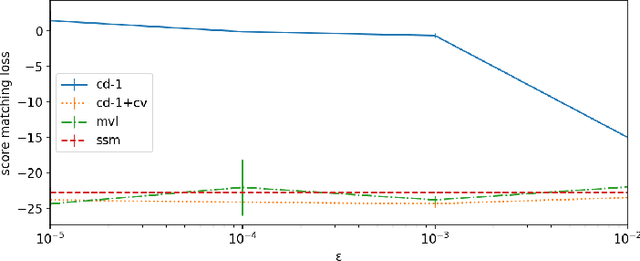
Score matching provides an effective approach to learning flexible unnormalized models, but its scalability is limited by the need to evaluate a second-order derivative. In this paper, we present a scalable approximation to a general family of learning objectives including score matching, by observing a new connection between these objectives and Wasserstein gradient flows. We present applications with promise in learning neural density estimators on manifolds, and training implicit variational and Wasserstein auto-encoders with a manifold-valued prior.
Improving Black-box Adversarial Attacks with a Transfer-based Prior
Jun 17, 2019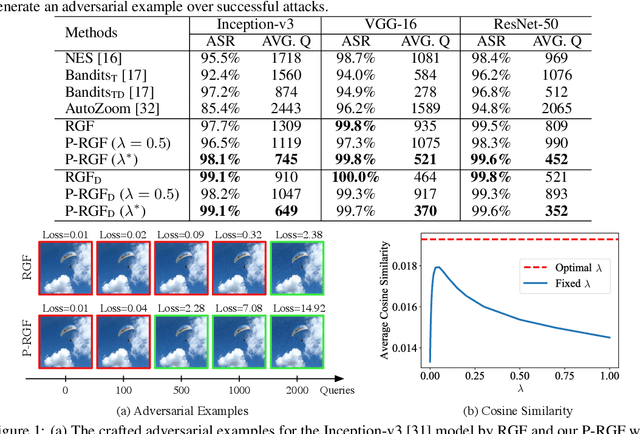
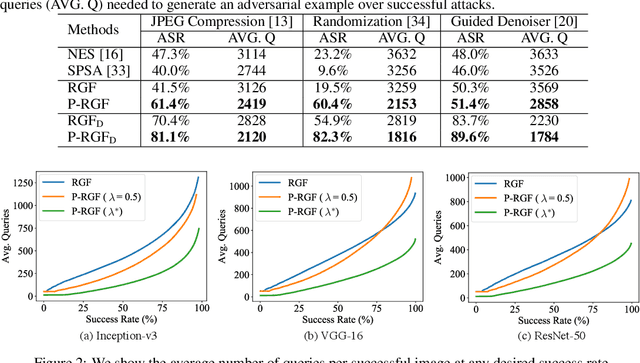
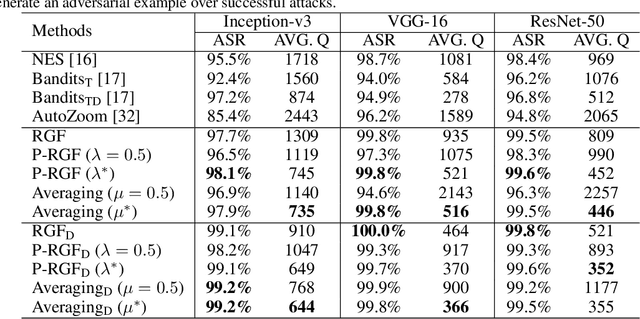
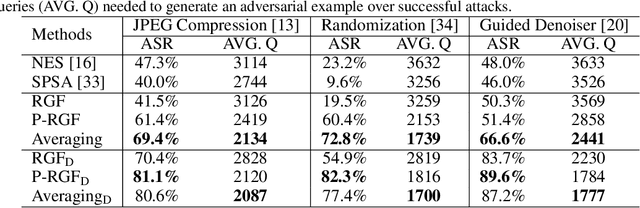
We consider the black-box adversarial setting, where the adversary has to generate adversarial perturbations without access to the target models to compute gradients. Previous methods tried to approximate the gradient either by using a transfer gradient of a surrogate white-box model, or based on the query feedback. However, these methods often suffer from low attack success rates or poor query efficiency since it is non-trivial to estimate the gradient in a high-dimensional space with limited information. To address these problems, we propose a prior-guided random gradient-free (P-RGF) method to improve black-box adversarial attacks, which takes the advantage of a transfer-based prior and the query information simultaneously. The transfer-based prior given by the gradient of a surrogate model is appropriately integrated into our algorithm by an optimal coefficient derived by a theoretical analysis. Extensive experiments demonstrate that our method requires much fewer queries to attack black-box models with higher success rates compared with the alternative state-of-the-art methods.