 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Hierarchical Implicit Flow Q-learning for Offline Goal-conditioned Reinforcement Learning
Apr 10, 2026Offline goal-conditioned reinforcement learning (GCRL) is a practical reinforcement learning paradigm that aims to learn goal-conditioned policies from reward-free offline data. Despite recent advances in hierarchical architectures such as HIQL, long-horizon control in offline GCRL remains challenging due to the limited expressiveness of Gaussian policies and the inability of high-level policies to generate effective subgoals. To address these limitations, we propose the goal-conditioned mean flow policy, which introduces an average velocity field into hierarchical policy modeling for offline GCRL. Specifically, the mean flow policy captures complex target distributions for both high-level and low-level policies through a learned average velocity field, enabling efficient action generation via one-step sampling. Furthermore, considering the insufficiency of goal representation, we introduce a LeJEPA loss that repels goal representation embeddings during training, thereby encouraging more discriminative representations and improving generalization. Experimental results show that our method achieves strong performance across both state-based and pixel-based tasks in the OGBench benchmark.
Value-Guidance MeanFlow for Offline Multi-Agent Reinforcement Learning
Apr 09, 2026Offline multi-agent reinforcement learning (MARL) aims to learn the optimal joint policy from pre-collected datasets, requiring a trade-off between maximizing global returns and mitigating distribution shift from offline data. Recent studies use diffusion or flow generative models to capture complex joint policy behaviors among agents; however, they typically rely on multi-step iterative sampling, thereby reducing training and inference efficiency. Although further research improves sampling efficiency through methods like distillation, it remains sensitive to the behavior regularization coefficient. To address the above-mentioned issues, we propose Value Guidance Multi-agent MeanFlow Policy (VGM$^2$P), a simple yet effective flow-based policy learning framework that enables efficient action generation with coefficient-insensitive conditional behavior cloning. Specifically, VGM$^2$P uses global advantage values to guide agent collaboration, treating optimal policy learning as conditional behavior cloning. Additionally, to improve policy expressiveness and inference efficiency in multi-agent scenarios, it leverages classifier-free guidance MeanFlow for both policy training and execution. Experiments on tasks with both discrete and continuous action spaces demonstrate that, even when trained solely via conditional behavior cloning, VGM$^2$P efficiently achieves performance comparable to state-of-the-art methods.
Equivariant Efficient Joint Discrete and Continuous MeanFlow for Molecular Graph Generation
Apr 09, 2026Graph-structured data jointly contain discrete topology and continuous geometry, which poses fundamental challenges for generative modeling due to heterogeneous distributions, incompatible noise dynamics, and the need for equivariant inductive biases. Existing flow-matching approaches for graph generation typically decouple structure from geometry, lack synchronized cross-domain dynamics, and rely on iterative sampling, often resulting in physically inconsistent molecular conformations and slow sampling. To address these limitations, we propose Equivariant MeanFlow (EQUIMF), a unified SE(3)-equivariant generative framework that jointly models discrete and continuous components through synchronized MeanFlow dynamics. EQUIMF introduces a unified time bridge and average-velocity updates with mutual conditioning between structure and geometry, enabling efficient few-step generation while preserving physical consistency. Moreover, we develop a novel discrete MeanFlow formulation with a simple yet effective parameterization to support efficient generation over discrete graph structures. Extensive experiments demonstrate that EQUIMF consistently outperforms prior diffusion and flow-matching methods in generation quality, physical validity, and sampling efficiency.
DPR: Diffusion Preference-based Reward for Offline Reinforcement Learning
Mar 03, 2025



Offline preference-based reinforcement learning (PbRL) mitigates the need for reward definition, aligning with human preferences via preference-driven reward feedback without interacting with the environment. However, the effectiveness of preference-driven reward functions depends on the modeling ability of the learning model, which current MLP-based and Transformer-based methods may fail to adequately provide. To alleviate the failure of the reward function caused by insufficient modeling, we propose a novel preference-based reward acquisition method: Diffusion Preference-based Reward (DPR). Unlike previous methods using Bradley-Terry models for trajectory preferences, we use diffusion models to directly model preference distributions for state-action pairs, allowing rewards to be discriminatively obtained from these distributions. In addition, considering the particularity of preference data that only know the internal relationships of paired trajectories, we further propose Conditional Diffusion Preference-based Reward (C-DPR), which leverages relative preference information to enhance the construction of the diffusion model. We apply the above methods to existing offline reinforcement learning algorithms and a series of experiment results demonstrate that the diffusion-based reward acquisition approach outperforms previous MLP-based and Transformer-based methods.
Sharper Concentration Inequalities for Multi-Graph Dependent Variables
Feb 25, 2025
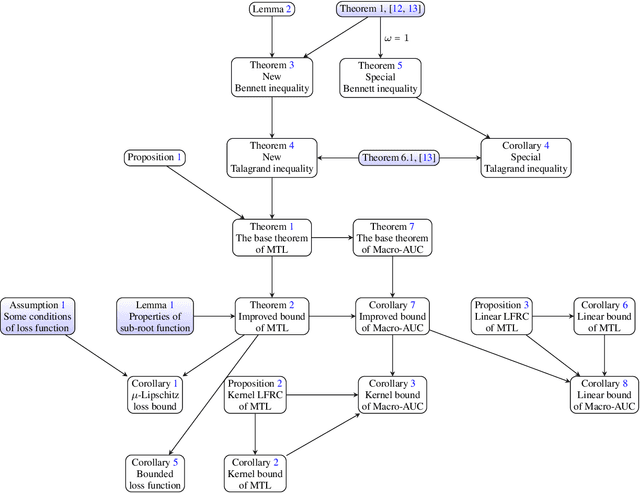
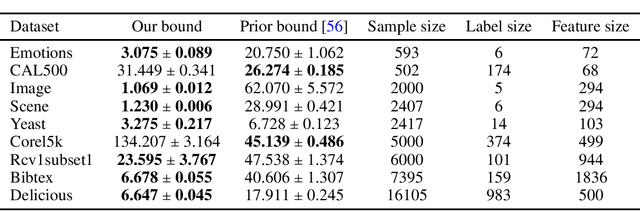
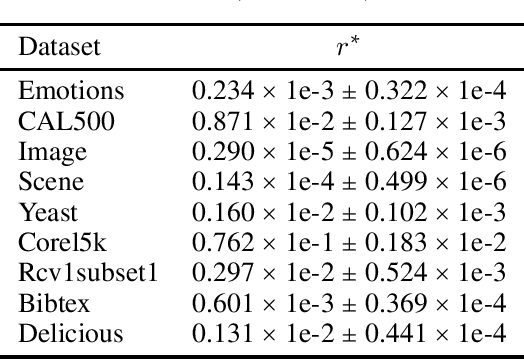
In multi-task learning (MTL) with each task involving graph-dependent data, generalization results of existing theoretical analyses yield a sub-optimal risk bound of $O(\frac{1}{\sqrt{n}})$, where $n$ is the number of training samples.This is attributed to the lack of a foundational sharper concentration inequality for multi-graph dependent random variables. To fill this gap, this paper proposes a new corresponding Bennett inequality, enabling the derivation of a sharper risk bound of $O(\frac{\log n}{n})$. Specifically, building on the proposed Bennett inequality, we propose a new corresponding Talagrand inequality for the empirical process and further develop an analytical framework of the local Rademacher complexity to enhance theoretical generalization analyses in MTL with multi-graph dependent data. Finally, we apply the theoretical advancements to applications such as Macro-AUC Optimization, demonstrating the superiority of our theoretical results over previous work, which is also corroborated by experimental results.
A Theory for Conditional Generative Modeling on Multiple Data Sources
Feb 20, 2025The success of large generative models has driven a paradigm shift, leveraging massive multi-source data to enhance model capabilities. However, the interaction among these sources remains theoretically underexplored. This paper takes the first step toward a rigorous analysis of multi-source training in conditional generative modeling, where each condition represents a distinct data source. Specifically, we establish a general distribution estimation error bound in average total variation distance for conditional maximum likelihood estimation based on the bracketing number. Our result shows that when source distributions share certain similarities and the model is expressive enough, multi-source training guarantees a sharper bound than single-source training. We further instantiate the general theory on conditional Gaussian estimation and deep generative models including autoregressive and flexible energy-based models, by characterizing their bracketing numbers. The results highlight that the number of sources and similarity among source distributions improve the advantage of multi-source training. Simulations and real-world experiments validate our theory. Code is available at: \url{https://github.com/ML-GSAI/Multi-Source-GM}.
Towards Macro-AUC oriented Imbalanced Multi-Label Continual Learning
Dec 24, 2024



In Continual Learning (CL), while existing work primarily focuses on the multi-class classification task, there has been limited research on Multi-Label Learning (MLL). In practice, MLL datasets are often class-imbalanced, making it inherently challenging, a problem that is even more acute in CL. Due to its sensitivity to imbalance, Macro-AUC is an appropriate and widely used measure in MLL. However, there is no research to optimize Macro-AUC in MLCL specifically. To fill this gap, in this paper, we propose a new memory replay-based method to tackle the imbalance issue for Macro-AUC-oriented MLCL. Specifically, inspired by recent theory work, we propose a new Reweighted Label-Distribution-Aware Margin (RLDAM) loss. Furthermore, to be compatible with the RLDAM loss, a new memory-updating strategy named Weight Retain Updating (WRU) is proposed to maintain the numbers of positive and negative instances of the original dataset in memory. Theoretically, we provide superior generalization analyses of the RLDAM-based algorithm in terms of Macro-AUC, separately in batch MLL and MLCL settings. This is the first work to offer theoretical generalization analyses in MLCL to our knowledge. Finally, a series of experimental results illustrate the effectiveness of our method over several baselines. Our codes are available at https://github.com/ML-Group-SDU/Macro-AUC-CL.
IPL: Leveraging Multimodal Large Language Models for Intelligent Product Listing
Oct 22, 2024



Unlike professional Business-to-Consumer (B2C) e-commerce platforms (e.g., Amazon), Consumer-to-Consumer (C2C) platforms (e.g., Facebook marketplace) are mainly targeting individual sellers who usually lack sufficient experience in e-commerce. Individual sellers often struggle to compose proper descriptions for selling products. With the recent advancement of Multimodal Large Language Models (MLLMs), we attempt to integrate such state-of-the-art generative AI technologies into the product listing process. To this end, we develop IPL, an Intelligent Product Listing tool tailored to generate descriptions using various product attributes such as category, brand, color, condition, etc. IPL enables users to compose product descriptions by merely uploading photos of the selling product. More importantly, it can imitate the content style of our C2C platform Xianyu. This is achieved by employing domain-specific instruction tuning on MLLMs and adopting the multi-modal Retrieval-Augmented Generation (RAG) process. A comprehensive empirical evaluation demonstrates that the underlying model of IPL significantly outperforms the base model in domain-specific tasks while producing less hallucination. IPL has been successfully deployed in our production system, where 72% of users have their published product listings based on the generated content, and those product listings are shown to have a quality score 5.6% higher than those without AI assistance.
Learning to Race in Extreme Turning Scene with Active Exploration and Gaussian Process Regression-based MPC
Oct 08, 2024
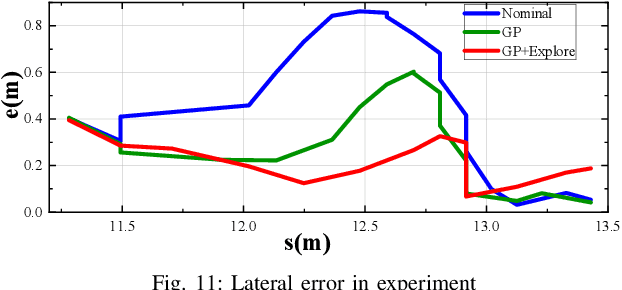
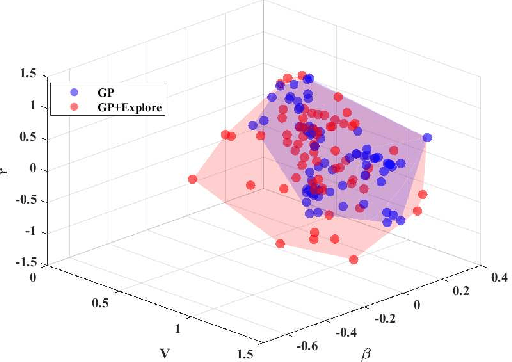
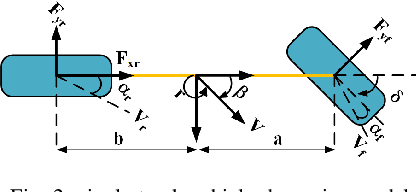
Extreme cornering in racing often induces large side-slip angles, presenting a formidable challenge in vehicle control. To tackle this issue, this paper introduces an Active Exploration with Double GPR (AEDGPR) system. The system initiates by planning a minimum-time trajectory with a Gaussian Process Regression(GPR) compensated model. The planning results show that in the cornering section, the yaw angular velocity and side-slip angle are in opposite directions, indicating that the vehicle is drifting. In response, we develop a drift controller based on Model Predictive Control (MPC) and incorporate Gaussian Process Regression to correct discrepancies in the vehicle dynamics model. Moreover, the covariance from the GPR is employed to actively explore various cornering states, aiming to minimize trajectory tracking errors. The proposed algorithm is validated through simulations on the Simulink-Carsim platform and experiments using a 1/10 scale RC vehicle.
On Mesa-Optimization in Autoregressively Trained Transformers: Emergence and Capability
May 27, 2024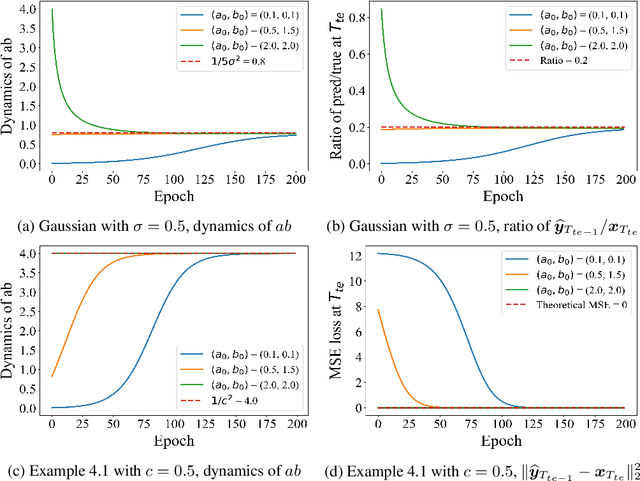
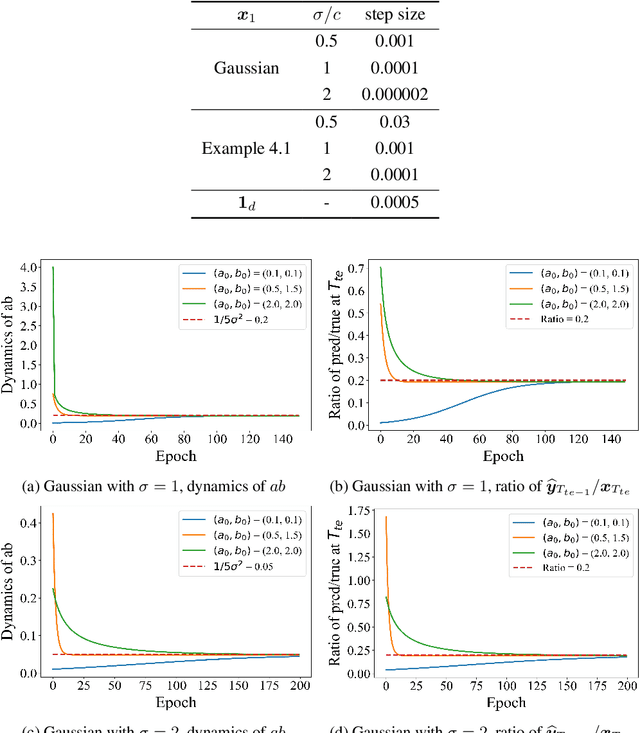
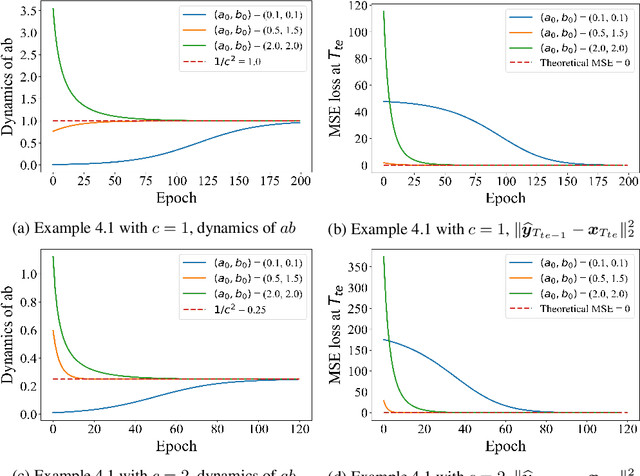
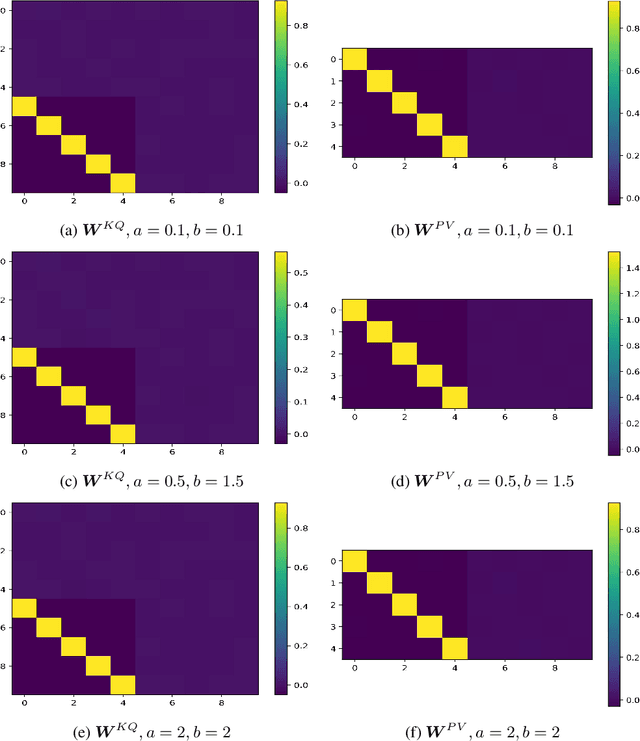
Autoregressively trained transformers have brought a profound revolution to the world, especially with their in-context learning (ICL) ability to address downstream tasks. Recently, several studies suggest that transformers learn a mesa-optimizer during autoregressive (AR) pretraining to implement ICL. Namely, the forward pass of the trained transformer is equivalent to optimizing an inner objective function in-context. However, whether the practical non-convex training dynamics will converge to the ideal mesa-optimizer is still unclear. Towards filling this gap, we investigate the non-convex dynamics of a one-layer linear causal self-attention model autoregressively trained by gradient flow, where the sequences are generated by an AR process $x_{t+1} = W x_t$. First, under a certain condition of data distribution, we prove that an autoregressively trained transformer learns $W$ by implementing one step of gradient descent to minimize an ordinary least squares (OLS) problem in-context. It then applies the learned $\widehat{W}$ for next-token prediction, thereby verifying the mesa-optimization hypothesis. Next, under the same data conditions, we explore the capability limitations of the obtained mesa-optimizer. We show that a stronger assumption related to the moments of data is the sufficient and necessary condition that the learned mesa-optimizer recovers the distribution. Besides, we conduct exploratory analyses beyond the first data condition and prove that generally, the trained transformer will not perform vanilla gradient descent for the OLS problem. Finally, our simulation results verify the theoretical results.