 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Learning Control-Informed Reinforcement Learning for Batch Process Control
Mar 16, 2026A significant limitation of Deep Reinforcement Learning (DRL) is the stochastic uncertainty in actions generated during exploration-exploitation, which poses substantial safety risks during both training and deployment. In industrial process control, the lack of formal stability and convergence guarantees further inhibits adoption of DRL methods by practitioners. Conversely, Iterative Learning Control (ILC) represents a well-established autonomous control methodology for repetitive systems, particularly in batch process optimization. ILC achieves desired control performance through iterative refinement of control laws, either between consecutive batches or within individual batches, to compensate for both repetitive and non-repetitive disturbances. This study introduces an Iterative Learning Control-Informed Reinforcement Learning (IL-CIRL) framework for training DRL controllers in dual-layer batch-to-batch and within-batch control architectures for batch processes. The proposed method incorporates Kalman filter-based state estimation within the iterative learning structure to guide DRL agents toward control policies that satisfy operational constraints and ensure stability guarantees. This approach enables the systematic design of DRL controllers for batch processes operating under multiple disturbance conditions.
Robust Spatiotemporal Motion Planning for Multi-Agent Autonomous Racing via Topological Gap Identification and Accelerated MPC
Mar 10, 2026High-speed multi-agent autonomous racing demands robust spatiotemporal planning and precise control under strict computational limits. Current methods often oversimplify interactions or abandon strict kinematic constraints. We resolve this by proposing a Topological Gap Identification and Accelerated MPC framework. By predicting opponent behaviors via SGPs, our method constructs dynamic occupancy corridors to robustly select optimal overtaking gaps. We ensure strict kinematic feasibility using a Linear Time-Varying MPC powered by a customized Pseudo-Transient Continuation (PTC) solver for high-frequency execution. Experimental results on the F1TENTH platform show that our method significantly outperforms state-of-the-art baselines: it reduces total maneuver time by 51.6% in sequential scenarios, consistently maintains an overtaking success rate exceeding 81% in dense bottlenecks, and lowers average computational latency by 20.3%, pushing the boundaries of safe and high-speed autonomous racing.
Vision-Augmented On-Track System Identification for Autonomous Racing via Attention-Based Priors and Iterative Neural Correction
Mar 10, 2026Operating autonomous vehicles at the absolute limits of handling requires precise, real-time identification of highly non-linear tire dynamics. However, traditional online optimization methods suffer from "cold-start" initialization failures and struggle to model high-frequency transient dynamics. To address these bottlenecks, this paper proposes a novel vision-augmented, iterative system identification framework. First, a lightweight CNN (MobileNetV3) translates visual road textures into a continuous heuristic friction prior, providing a robust "warm-start" for parameter optimization. Next, a S4 model captures complex temporal dynamic residuals, circumventing the memory and latency limitations of traditional MLPs and RNNs. Finally, a derivative-free Nelder-Mead algorithm iteratively extracts physically interpretable Pacejka tire parameters via a hybrid virtual simulation. Co-simulation in CarSim demonstrates that the lightweight vision backbone reduces friction estimation error by 76.1 using 85 fewer FLOPs, accelerating cold-start convergence by 71.4. Furthermore, the S4-augmented framework improves parameter extraction accuracy and decreases lateral force RMSE by over 60 by effectively capturing complex vehicle dynamics, demonstrating superior performance compared to conventional neural architectures.
A Rapid Iterative Trajectory Planning Method for Automated Parking through Differential Flatness
Aug 23, 2025As autonomous driving continues to advance, automated parking is becoming increasingly essential. However, significant challenges arise when implementing path velocity decomposition (PVD) trajectory planning for automated parking. The primary challenge is ensuring rapid and precise collision-free trajectory planning, which is often in conflict. The secondary challenge involves maintaining sufficient control feasibility of the planned trajectory, particularly at gear shifting points (GSP). This paper proposes a PVD-based rapid iterative trajectory planning (RITP) method to solve the above challenges. The proposed method effectively balances the necessity for time efficiency and precise collision avoidance through a novel collision avoidance framework. Moreover, it enhances the overall control feasibility of the planned trajectory by incorporating the vehicle kinematics model and including terminal smoothing constraints (TSC) at GSP during path planning. Specifically, the proposed method leverages differential flatness to ensure the planned path adheres to the vehicle kinematic model. Additionally, it utilizes TSC to maintain curvature continuity at GSP, thereby enhancing the control feasibility of the overall trajectory. The simulation results demonstrate superior time efficiency and tracking errors compared to model-integrated and other iteration-based trajectory planning methods. In the real-world experiment, the proposed method was implemented and validated on a ROS-based vehicle, demonstrating the applicability of the RITP method for real vehicles.
* Published in the journal Robotics and Autonomous Systems
Multi-Mode Process Control Using Multi-Task Inverse Reinforcement Learning
May 27, 2025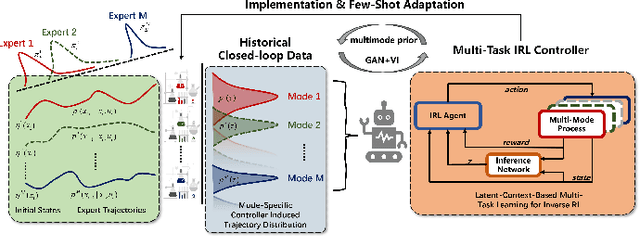

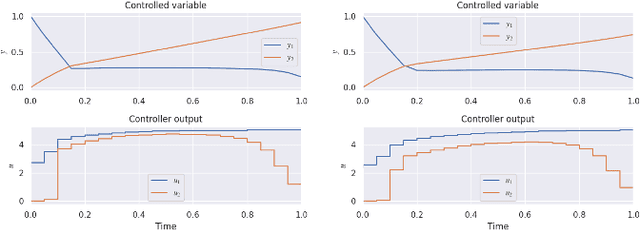
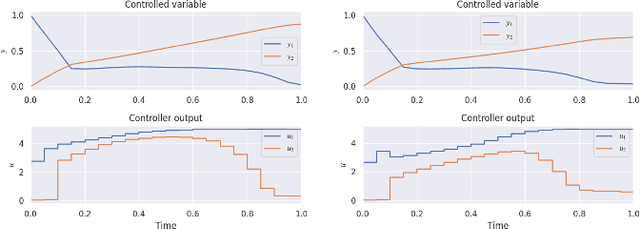
In the era of Industry 4.0 and smart manufacturing, process systems engineering must adapt to digital transformation. While reinforcement learning offers a model-free approach to process control, its applications are limited by the dependence on accurate digital twins and well-designed reward functions. To address these limitations, this paper introduces a novel framework that integrates inverse reinforcement learning (IRL) with multi-task learning for data-driven, multi-mode control design. Using historical closed-loop data as expert demonstrations, IRL extracts optimal reward functions and control policies. A latent-context variable is incorporated to distinguish modes, enabling the training of mode-specific controllers. Case studies on a continuous stirred tank reactor and a fed-batch bioreactor validate the effectiveness of this framework in handling multi-mode data and training adaptable controllers.
Adaptive Learning-based Model Predictive Control Strategy for Drift Vehicles
Feb 07, 2025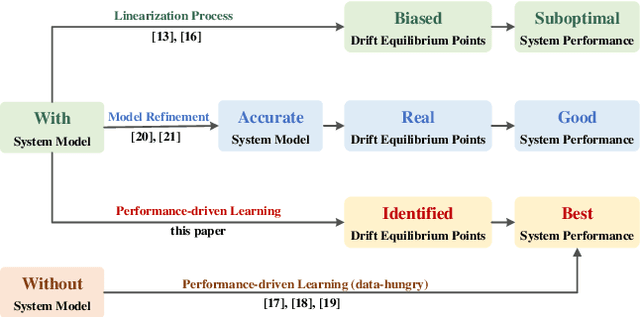
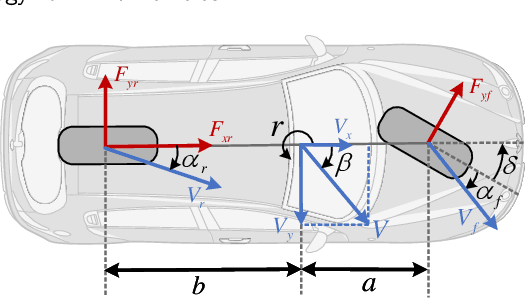
Drift vehicle control offers valuable insights to support safe autonomous driving in extreme conditions, which hinges on tracking a particular path while maintaining the vehicle states near the drift equilibrium points (DEP). However, conventional tracking methods are not adaptable for drift vehicles due to their opposite steering angle and yaw rate. In this paper, we propose an adaptive path tracking (APT) control method to dynamically adjust drift states to follow the reference path, improving the commonly utilized predictive path tracking methods with released computation burden. Furthermore, existing control strategies necessitate a precise system model to calculate the DEP, which can be more intractable due to the highly nonlinear drift dynamics and sensitive vehicle parameters. To tackle this problem, an adaptive learning-based model predictive control (ALMPC) strategy is proposed based on the APT method, where an upper-level Bayesian optimization is employed to learn the DEP and APT control law to instruct a lower-level MPC drift controller. This hierarchical system architecture can also resolve the inherent control conflict between path tracking and drifting by separating these objectives into different layers. The ALMPC strategy is verified on the Matlab-Carsim platform, and simulation results demonstrate its effectiveness in controlling the drift vehicle to follow a clothoid-based reference path even with the misidentified road friction parameter.
Reduce Lap Time for Autonomous Racing with Curvature-Integrated MPCC Local Trajectory Planning Method
Feb 06, 2025



The widespread application of autonomous driving technology has significantly advanced the field of autonomous racing. Model Predictive Contouring Control (MPCC) is a highly effective local trajectory planning method for autonomous racing. However, the traditional MPCC method struggles with racetracks that have significant curvature changes, limiting the performance of the vehicle during autonomous racing. To address this issue, we propose a curvature-integrated MPCC (CiMPCC) local trajectory planning method for autonomous racing. This method optimizes the velocity of the local trajectory based on the curvature of the racetrack centerline. The specific implementation involves mapping the curvature of the racetrack centerline to a reference velocity profile, which is then incorporated into the cost function for optimizing the velocity of the local trajectory. This reference velocity profile is created by normalizing and mapping the curvature of the racetrack centerline, thereby ensuring efficient and performance-oriented local trajectory planning in racetracks with significant curvature. The proposed CiMPCC method has been experimented on a self-built 1:10 scale F1TENTH racing vehicle deployed with ROS platform. The experimental results demonstrate that the proposed method achieves outstanding results on a challenging racetrack with sharp curvature, improving the overall lap time by 11.4%-12.5% compared to other autonomous racing trajectory planning methods. Our code is available at https://github.com/zhouhengli/CiMPCC.
Three-Dimensional Sparse Random Mode Decomposition for Mode Disentangling with Crossover Instantaneous Frequencies
Jan 25, 2025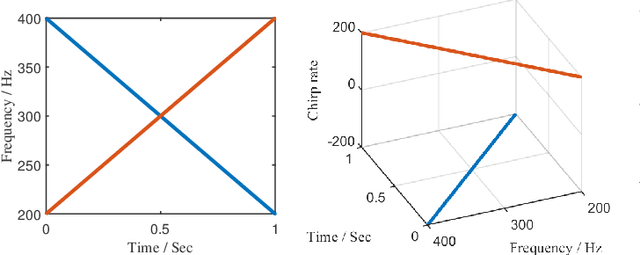
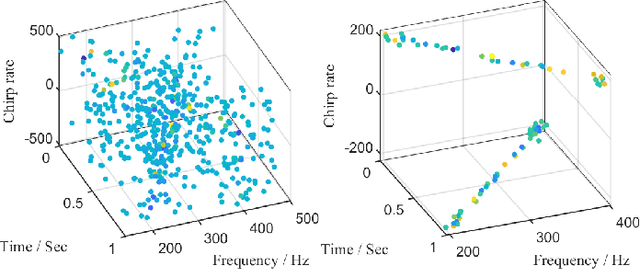
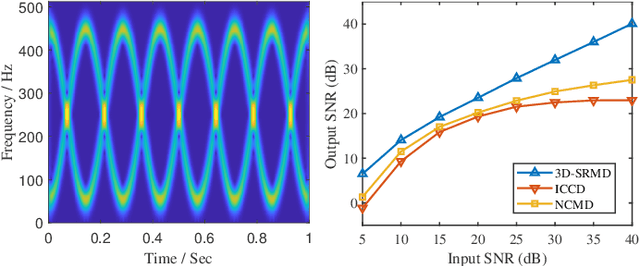
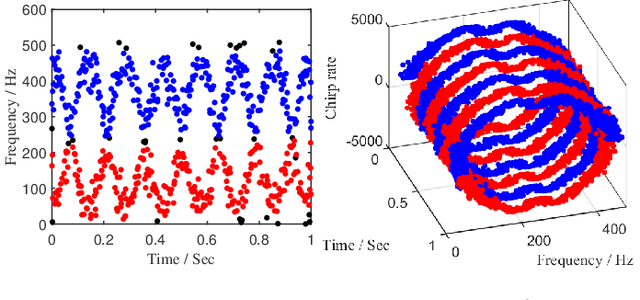
Sparse random mode decomposition (SRMD) is a novel algorithm that constructs a random time-frequency feature space to sparsely approximate spectrograms, effectively separating modes. However, it fails to distinguish adjacent or overlapped frequency components, especially, those with crossover instantaneous frequencies. To address this limitation, an enhanced version, termed three-dimensional SRMD (3D-SRMD), is proposed in this letter. In 3D-SRMD, the random features are lifted from a two-dimensional space to a three-dimensional (3D) space by introducing one extra chirp rate axis. This enhancement effectively disentangles the frequency components overlapped in the low dimension. Additionally, a novel random feature generation strategy is designed to improve the separation accuracy of 3D-SRMD by combining the 3D ridge detection method. Finally, numerical experiments on both simulated and real-world signals demonstrate the effectiveness of our method.
An Overtaking Trajectory Planning Framework Based on Spatio-temporal Topology and Reachable Set Analysis Ensuring Time Efficiency
Oct 30, 2024



Generating overtaking trajectories in high-speed scenarios presents significant challenges and is typically addressed through hierarchical planning methods. However, this method has two primary drawbacks. First, heuristic algorithms can only provide a single initial solution, which may lead to local optima and consequently diminish the quality of the solution. Second, the time efficiency of trajectory refinement based on numerical optimization is insufficient. To overcome these limitations, this paper proposes an overtaking trajectory planning framework based on spatio-temporal topology and reachable set analysis (SROP), to improve trajectory quality and time efficiency. Specifically, this paper introduces topological classes to describe trajectories representing different overtaking behaviors, which support the spatio-temporal topological search method employed by the upper-layer planner to identify diverse initial paths. This approach helps prevent getting stuck in local optima, enhancing the overall solution quality by considering multiple initial solutions from distinct topologies. Moreover, the reachable set method is integrated into the lower-layer planner for parallel trajectory evaluation. This method enhances planning efficiency by decoupling vehicle model constraints from the optimization process, enabling parallel computation while ensuring control feasibility. Simulation results show that the proposed method improves the smoothness of generated trajectories by 66.8% compared to state-of-the-art methods, highlighting its effectiveness in enhancing trajectory quality. Additionally, this method reduces computation time by 62.9%, demonstrating its efficiency.
A Data-Driven Aggressive Autonomous Racing Framework Utilizing Local Trajectory Planning with Velocity Prediction
Oct 15, 2024The development of autonomous driving has boosted the research on autonomous racing. However, existing local trajectory planning methods have difficulty planning trajectories with optimal velocity profiles at racetracks with sharp corners, thus weakening the performance of autonomous racing. To address this problem, we propose a local trajectory planning method that integrates Velocity Prediction based on Model Predictive Contour Control (VPMPCC). The optimal parameters of VPMPCC are learned through Bayesian Optimization (BO) based on a proposed novel Objective Function adapted to Racing (OFR). Specifically, VPMPCC achieves velocity prediction by encoding the racetrack as a reference velocity profile and incorporating it into the optimization problem. This method optimizes the velocity profile of local trajectories, especially at corners with significant curvature. The proposed OFR balances racing performance with vehicle safety, ensuring safe and efficient BO training. In the simulation, the number of training iterations for OFR-based BO is reduced by 42.86% compared to the state-of-the-art method. The optimal simulation-trained parameters are then applied to a real-world F1TENTH vehicle without retraining. During prolonged racing on a custom-built racetrack featuring significant sharp corners, the mean velocity of VPMPCC reaches 93.18% of the vehicle's handling limits. The released code is available at https://github.com/zhouhengli/VPMPCC.