 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPAT: Building Robust Deep Neural Networks against Textual Adversarial Attacks
Feb 29, 2024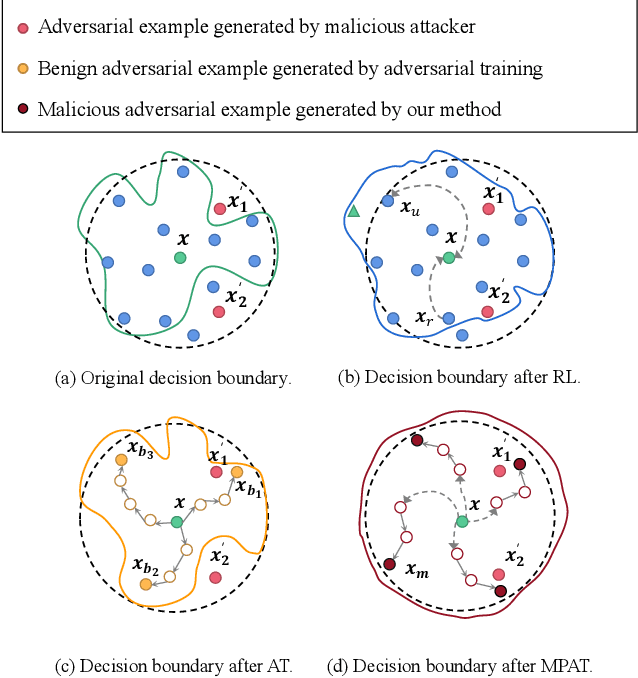
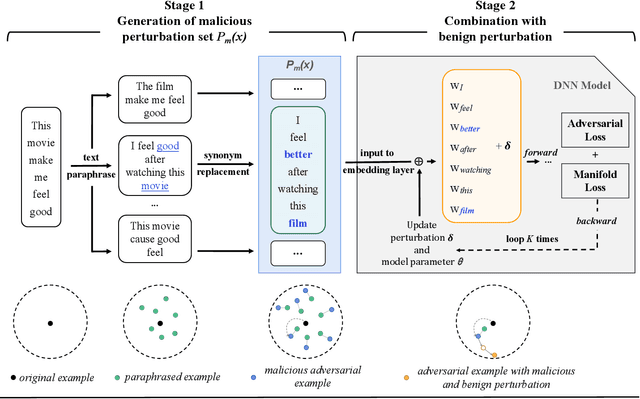
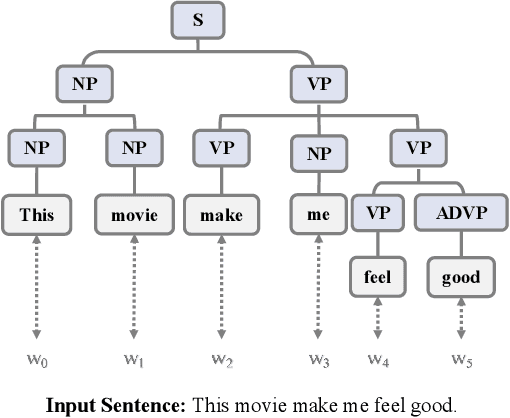
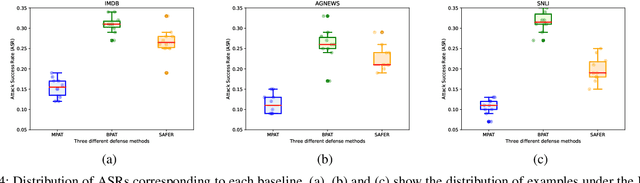
Deep neural networks have been proven to be vulnerable to adversarial examples and various methods have been proposed to defend against adversarial attacks for natural language processing tasks. However, previous defense methods have limitations in maintaining effective defense while ensuring the performance of the original task. In this paper, we propose a malicious perturbation based adversarial training method (MPAT) for building robust deep neural networks against textual adversarial attacks. Specifically, we construct a multi-level malicious example generation strategy to generate adversarial examples with malicious perturbations, which are used instead of original inputs for model training. Additionally, we employ a novel training objective function to ensure achieving the defense goal without compromising the performance on the original task. We conduct comprehensive experiments to evaluate our defense method by attacking five victim models on three benchmark datasets. The result demonstrates that our method is more effective against malicious adversarial attacks compared with previous defense methods while maintaining or further improving the performance on the original task.