 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTM-VQA: Efficient Video Quality Assessment Leveraging Diverse PreTrained Models from the Wild
May 28, 2024

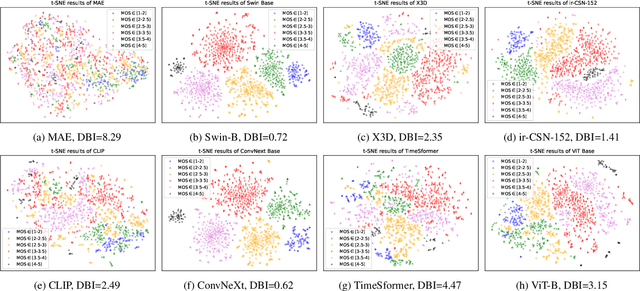

Video quality assessment (VQA) is a challenging problem due to the numerous factors that can affect the perceptual quality of a video, \eg, content attractiveness, distortion type, motion pattern, and level. However, annotating the Mean opinion score (MOS) for videos is expensive and time-consuming, which limits the scale of VQA datasets, and poses a significant obstacle for deep learning-based methods. In this paper, we propose a VQA method named PTM-VQA, which leverages PreTrained Models to transfer knowledge from models pretrained on various pre-tasks, enabling benefits for VQA from different aspects. Specifically, we extract features of videos from different pretrained models with frozen weights and integrate them to generate representation. Since these models possess various fields of knowledge and are often trained with labels irrelevant to quality, we propose an Intra-Consistency and Inter-Divisibility (ICID) loss to impose constraints on features extracted by multiple pretrained models. The intra-consistency constraint ensures that features extracted by different pretrained models are in the same unified quality-aware latent space, while the inter-divisibility introduces pseudo clusters based on the annotation of samples and tries to separate features of samples from different clusters. Furthermore, with a constantly growing number of pretrained models, it is crucial to determine which models to use and how to use them. To address this problem, we propose an efficient scheme to select suitable candidates. Models with better clustering performance on VQA datasets are chosen to be our candidates. Extensive experiments demonstrate the effectiveness of the proposed method.
Reconstructed Convolution Module Based Look-Up Tables for Efficient Image Super-Resolution
Jul 17, 2023Look-up table(LUT)-based methods have shown the great efficacy in single image super-resolution (SR) task. However, previous methods ignore the essential reason of restricted receptive field (RF) size in LUT, which is caused by the interaction of space and channel features in vanilla convolution. They can only increase the RF at the cost of linearly increasing LUT size. To enlarge RF with contained LUT sizes, we propose a novel Reconstructed Convolution(RC) module, which decouples channel-wise and spatial calculation. It can be formulated as $n^2$ 1D LUTs to maintain $n\times n$ receptive field, which is obviously smaller than $n\times n$D LUT formulated before. The LUT generated by our RC module reaches less than 1/10000 storage compared with SR-LUT baseline. The proposed Reconstructed Convolution module based LUT method, termed as RCLUT, can enlarge the RF size by 9 times than the state-of-the-art LUT-based SR method and achieve superior performance on five popular benchmark dataset. Moreover, the efficient and robust RC module can be used as a plugin to improve other LUT-based SR methods. The code is available at https://github.com/liuguandu/RC-LUT.
Quality-aware Pre-trained Models for Blind Image Quality Assessment
Mar 01, 2023



Blind image quality assessment (BIQA) aims to automatically evaluate the perceived quality of a single image, whose performance has been improved by deep learning-based methods in recent years. However, the paucity of labeled data somewhat restrains deep learning-based BIQA methods from unleashing their full potential. In this paper, we propose to solve the problem by a pretext task customized for BIQA in a self-supervised learning manner, which enables learning representations from orders of magnitude more data. To constrain the learning process, we propose a quality-aware contrastive loss based on a simple assumption: the quality of patches from a distorted image should be similar, but vary from patches from the same image with different degradations and patches from different images. Further, we improve the existing degradation process and form a degradation space with the size of roughly $2\times10^7$. After pre-trained on ImageNet using our method, models are more sensitive to image quality and perform significantly better on downstream BIQA tasks. Experimental results show that our method obtains remarkable improvements on popular BIQA datasets.
Aesthetic Photo Collage with Deep Reinforcement Learning
Oct 19, 2021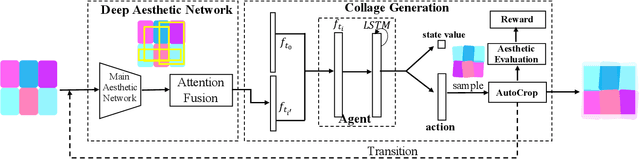



Photo collage aims to automatically arrange multiple photos on a given canvas with high aesthetic quality. Existing methods are based mainly on handcrafted feature optimization, which cannot adequately capture high-level human aesthetic senses. Deep learning provides a promising way, but owing to the complexity of collage and lack of training data, a solution has yet to be found. In this paper, we propose a novel pipeline for automatic generation of aspect ratio specified collage and the reinforcement learning technique is introduced in collage for the first time. Inspired by manual collages, we model the collage generation as sequential decision process to adjust spatial positions, orientation angles, placement order and the global layout. To instruct the agent to improve both the overall layout and local details, the reward function is specially designed for collage, considering subjective and objective factors. To overcome the lack of training data, we pretrain our deep aesthetic network on a large scale image aesthetic dataset (CPC) for general aesthetic feature extraction and propose an attention fusion module for structural collage feature representation. We test our model against competing methods on two movie datasets and our results outperform others in aesthetic quality evaluation. Further user study is also conducted to demonstrate the effectiveness.
Progressive Spatial Recurrent Neural Network for Intra Prediction
Jul 06, 2018
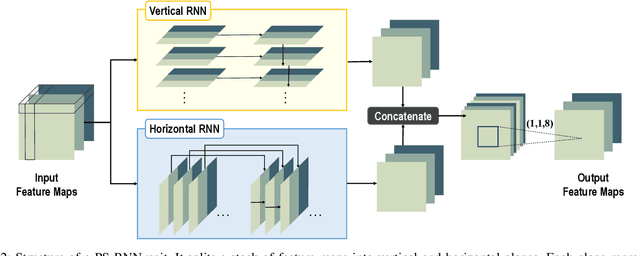

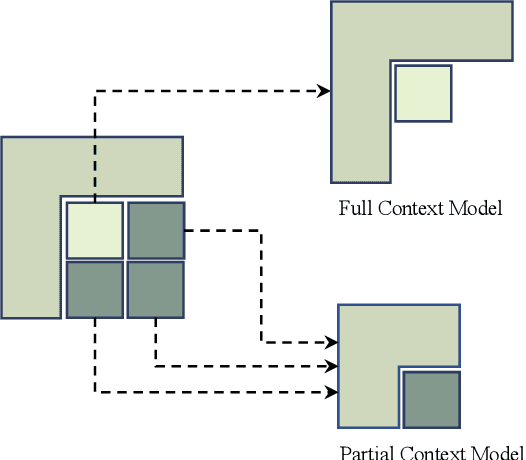
Intra prediction is an important component of modern video codecs, which is able to efficiently squeeze out the spatial redundancy in video frames. With preceding pixels as the context, traditional intra prediction schemes generate linear predictions based on several predefined directions (i.e. modes) for blocks to be encoded. However, these modes are relatively simple and their predictions may fail when facing blocks with complex textures, which leads to additional bits encoding the residue. In this paper, we design a Progressive Spatial Recurrent Neural Network (PS-RNN) that learns to conduct intra prediction. Specifically, our PS-RNN consists of three spatial recurrent units and progressively generates predictions by passing information along from preceding contents to blocks to be encoded. To make our network generate predictions considering both distortion and bit-rate, we propose to use Sum of Absolute Transformed Difference (SATD) as the loss function to train PS-RNN since SATD is able to measure rate-distortion cost of encoding a residue block. Moreover, our method supports variable-block-size for intra prediction, which is more practical in real coding conditions. The proposed intra prediction scheme achieves on average 2.4% bit-rate reduction on variable-block-size settings under the same reconstruction quality compared with HEVC.
Joint Enhancement and Denoising Method via Sequential Decomposition
Apr 28, 2018



Many low-light enhancement methods ignore intensive noise in original images. As a result, they often simultaneously enhance the noise as well. Furthermore, extra denoising procedures adopted by most methods ruin the details. In this paper, we introduce a joint low-light enhancement and denoising strategy, aimed at obtaining well-enhanced low-light images while getting rid of the inherent noise issue simultaneously. The proposed method performs Retinex model based decomposition in a successive sequence, which sequentially estimates a piece-wise smoothed illumination and a noise-suppressed reflectance. After getting the illumination and reflectance map, we adjust the illumination layer and generate our enhancement result. In this noise-suppressed sequential decomposition process we enforce the spatial smoothness on each component and skillfully make use of weight matrices to suppress the noise and improve the contrast. Results of extensive experiments demonstrate the effectiveness and practicability of our method. It performs well for a wide variety of images, and achieves better or comparable quality compared with the state-of-the-art methods.
MARLow: A Joint Multiplanar Autoregressive and Low-Rank Approach for Image Completion
Jun 16, 2016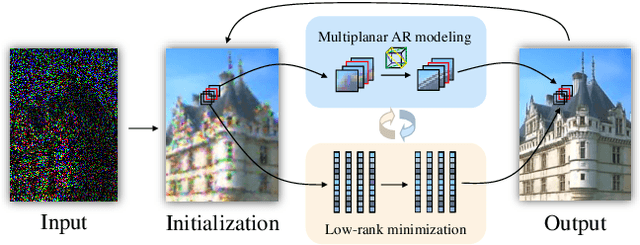
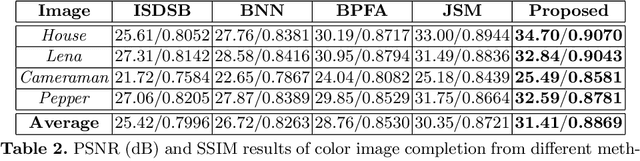
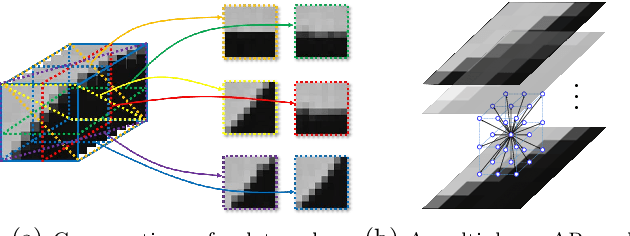
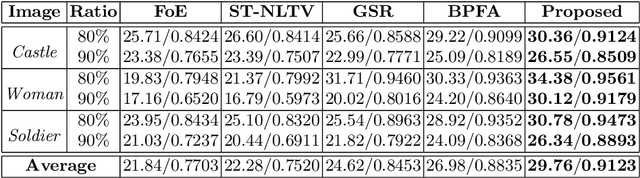
In this paper, we propose a novel multiplanar autoregressive (AR) model to exploit the correlation in cross-dimensional planes of a similar patch group collected in an image, which has long been neglected by previous AR models. On that basis, we then present a joint multiplanar AR and low-rank based approach (MARLow) for image completion from random sampling, which exploits the nonlocal self-similarity within natural images more effectively. Specifically, the multiplanar AR model constraints the local stationarity in different cross-sections of the patch group, while the low-rank minimization captures the intrinsic coherence of nonlocal patches. The proposed approach can be readily extended to multichannel images (e.g. color images), by simultaneously considering the correlation in different channels. Experimental results demonstrate that the proposed approach significantly outperforms state-of-the-art methods, even if the pixel missing rate is as high as 90%.