 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Reorganization with Weak Spatial Constraints: Solving Arbitrary Jigsaw Puzzles for Unsupervised Representation Learning
Dec 02, 2018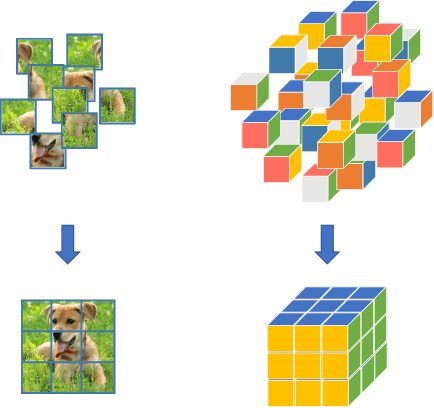



Learning visual features from unlabeled image data is an important yet challenging task, which is often achieved by training a model on some annotation-free information. We consider spatial contexts, for which we solve so-called jigsaw puzzles, i.e., each image is cut into grids and then disordered, and the goal is to recover the correct configuration. Existing approaches formulated it as a classification task by defining a fixed mapping from a small subset of configurations to a class set, but these approaches ignore the underlying relationship between different configurations and also limit their application to more complex scenarios. This paper presents a novel approach which applies to jigsaw puzzles with an arbitrary grid size and dimensionality. We provide a fundamental and generalized principle, that weaker cues are easier to be learned in an unsupervised manner and also transfer better. In the context of puzzle recognition, we use an iterative manner which, instead of solving the puzzle all at once, adjusts the order of the patches in each step until convergence. In each step, we combine both unary and binary features on each patch into a cost function judging the correctness of the current configuration. Our approach, by taking similarity between puzzles into consideration, enjoys a more reasonable way of learning visual knowledge. We verify the effectiveness of our approach in two aspects. First, it is able to solve arbitrarily complex puzzles, including high-dimensional puzzles, that prior methods are difficult to handle. Second, it serves as a reliable way of network initialization, which leads to better transfer performance in a few visual recognition tasks including image classification, object detection, and semantic segmentation.
Progressive Recurrent Learning for Visual Recognition
Nov 29, 2018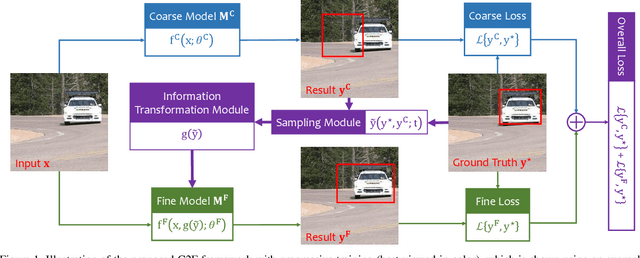
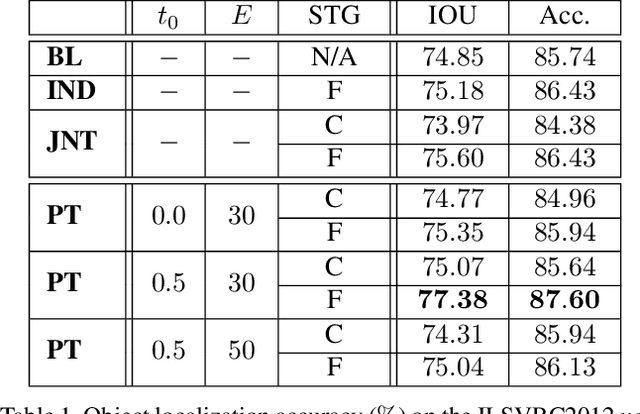

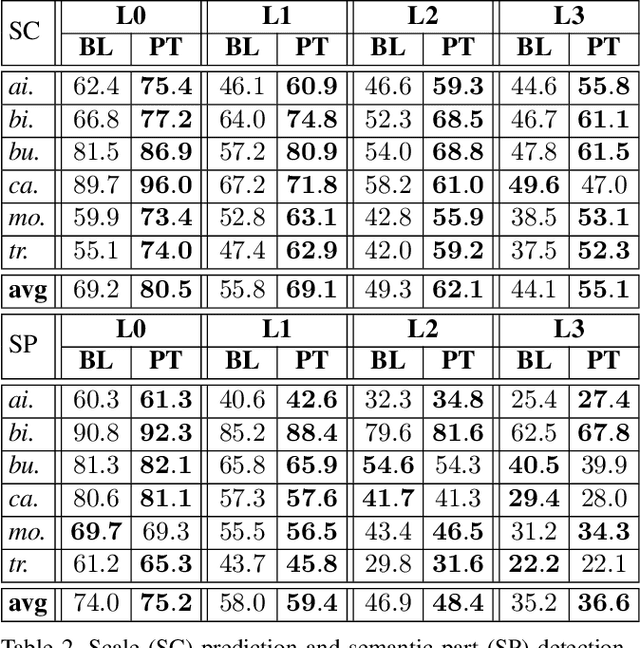
Computer vision is difficult, partly because the mathematical function connecting input and output data is often complex, fuzzy and thus hard to learn. A currently popular solution is to design a deep neural network and optimize it on a large-scale dataset. However, as the number of parameters increases, the generalization ability is often not guaranteed, e.g., the model can over-fit due to the limited amount of training data, or fail to converge because the desired function is too difficult to learn. This paper presents an effective framework named progressive recurrent learning (PRL). The core idea is similar to curriculum learning which gradually increases the difficulty of training data. We generalize it to a wide range of vision problems that were previously considered less proper to apply curriculum learning. PRL starts with inserting a recurrent prediction scheme, based on the motivation of feeding the prediction of a vision model to the same model iteratively, so that the auxiliary cues contained in it can be exploited to improve the quality of itself. In order to better optimize this framework, we start with providing perfect prediction, i.e., ground-truth, to the second stage, but gradually replace it with the prediction of the first stage. In the final status, the ground-truth information is not needed any more, so that the entire model works on the real data distribution as in the testing process. We apply PRL to two challenging visual recognition tasks, namely, object localization and semantic segmentation, and demonstrate consistent accuracy gain compared to the baseline training strategy, especially in the scenarios of more difficult vision tasks.
Joint Enhancement and Denoising Method via Sequential Decomposition
Apr 28, 2018



Many low-light enhancement methods ignore intensive noise in original images. As a result, they often simultaneously enhance the noise as well. Furthermore, extra denoising procedures adopted by most methods ruin the details. In this paper, we introduce a joint low-light enhancement and denoising strategy, aimed at obtaining well-enhanced low-light images while getting rid of the inherent noise issue simultaneously. The proposed method performs Retinex model based decomposition in a successive sequence, which sequentially estimates a piece-wise smoothed illumination and a noise-suppressed reflectance. After getting the illumination and reflectance map, we adjust the illumination layer and generate our enhancement result. In this noise-suppressed sequential decomposition process we enforce the spatial smoothness on each component and skillfully make use of weight matrices to suppress the noise and improve the contrast. Results of extensive experiments demonstrate the effectiveness and practicability of our method. It performs well for a wide variety of images, and achieves better or comparable quality compared with the state-of-the-art methods.