 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAda-DQA: Adaptive Diverse Quality-aware Feature Acquisition for Video Quality Assessment
Aug 01, 2023Video quality assessment (VQA) has attracted growing attention in recent years. While the great expense of annotating large-scale VQA datasets has become the main obstacle for current deep-learning methods. To surmount the constraint of insufficient training data, in this paper, we first consider the complete range of video distribution diversity (\ie content, distortion, motion) and employ diverse pretrained models (\eg architecture, pretext task, pre-training dataset) to benefit quality representation. An Adaptive Diverse Quality-aware feature Acquisition (Ada-DQA) framework is proposed to capture desired quality-related features generated by these frozen pretrained models. By leveraging the Quality-aware Acquisition Module (QAM), the framework is able to extract more essential and relevant features to represent quality. Finally, the learned quality representation is utilized as supplementary supervisory information, along with the supervision of the labeled quality score, to guide the training of a relatively lightweight VQA model in a knowledge distillation manner, which largely reduces the computational cost during inference. Experimental results on three mainstream no-reference VQA benchmarks clearly show the superior performance of Ada-DQA in comparison with current state-of-the-art approaches without using extra training data of VQA.
Capturing Co-existing Distortions in User-Generated Content for No-reference Video Quality Assessment
Jul 31, 2023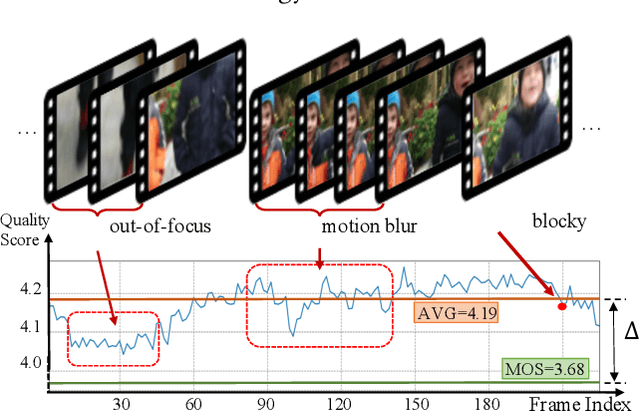
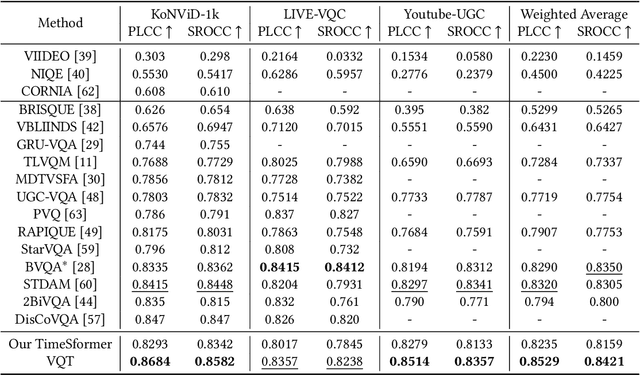
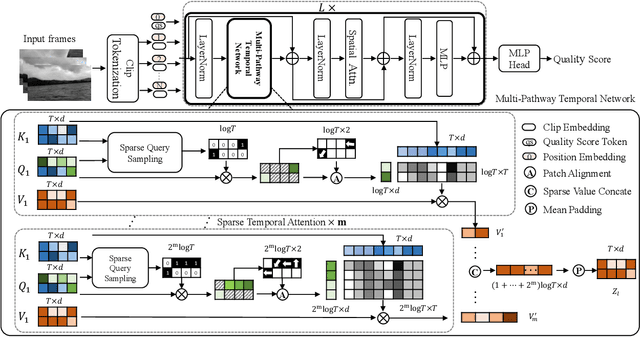
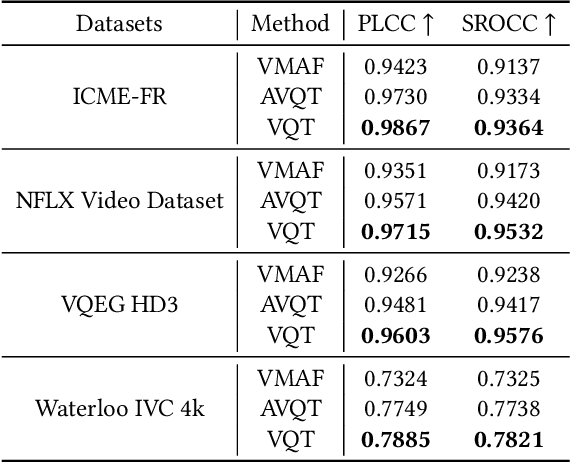
Video Quality Assessment (VQA), which aims to predict the perceptual quality of a video, has attracted raising attention with the rapid development of streaming media technology, such as Facebook, TikTok, Kwai, and so on. Compared with other sequence-based visual tasks (\textit{e.g.,} action recognition), VQA faces two under-estimated challenges unresolved in User Generated Content (UGC) videos. \textit{First}, it is not rare that several frames containing serious distortions (\textit{e.g.,}blocking, blurriness), can determine the perceptual quality of the whole video, while other sequence-based tasks require more frames of equal importance for representations. \textit{Second}, the perceptual quality of a video exhibits a multi-distortion distribution, due to the differences in the duration and probability of occurrence for various distortions. In order to solve the above challenges, we propose \textit{Visual Quality Transformer (VQT)} to extract quality-related sparse features more efficiently. Methodologically, a Sparse Temporal Attention (STA) is proposed to sample keyframes by analyzing the temporal correlation between frames, which reduces the computational complexity from $O(T^2)$ to $O(T \log T)$. Structurally, a Multi-Pathway Temporal Network (MPTN) utilizes multiple STA modules with different degrees of sparsity in parallel, capturing co-existing distortions in a video. Experimentally, VQT demonstrates superior performance than many \textit{state-of-the-art} methods in three public no-reference VQA datasets. Furthermore, VQT shows better performance in four full-reference VQA datasets against widely-adopted industrial algorithms (\textit{i.e.,} VMAF and AVQT).