 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSSP : A Versatile Multi-Scenario Adaptable Intelligent Robot Simulation Platform Based on LIDAR-Inertial Fusion
Jul 19, 2024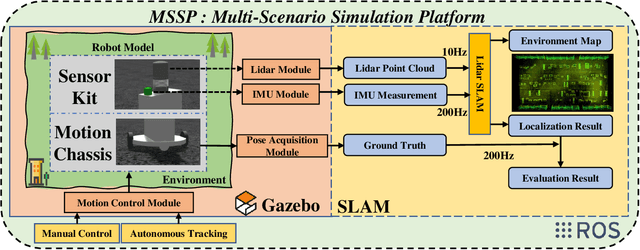
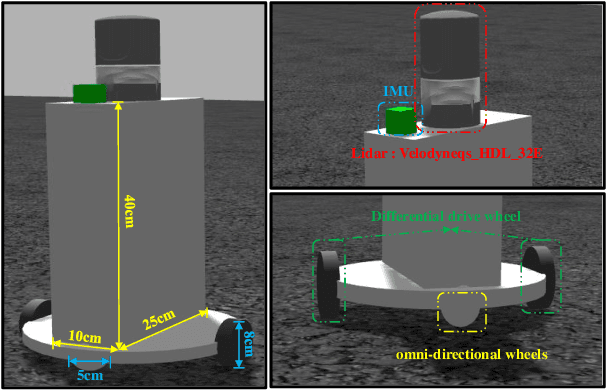
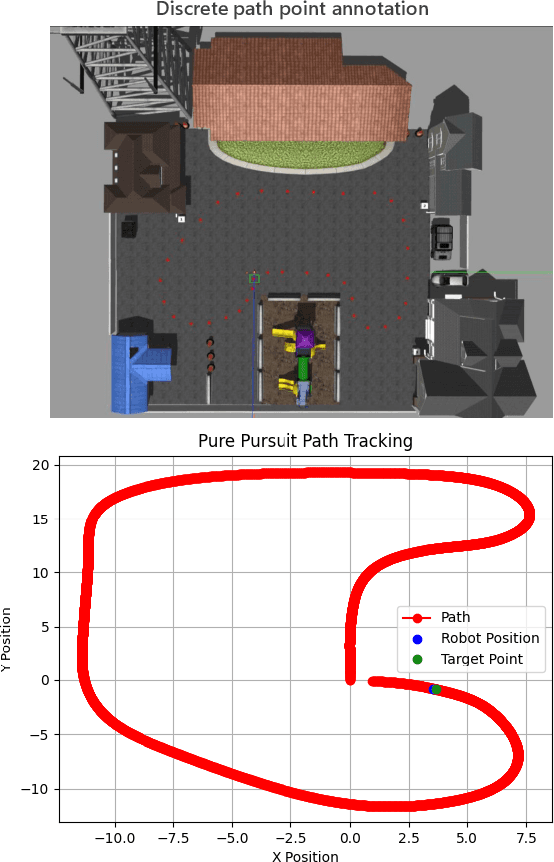

This letter presents a multi-scenario adaptable intelligent robot simulation platform based on LIDAR-inertial fusion, with three main features: (1 The platform includes an versatile robot model that can be freely controlled through manual control or autonomous tracking. This model is equipped with various types of LIDAR and Inertial Measurement Unit (IMU), providing ground truth information with absolute accuracy. (2 The platform provides a collection of simulation environments with diverse characteristic information and supports developers in customizing and modifying environments according to their needs. (3 The platform supports evaluation of localization performance for SLAM frameworks. Ground truth with absolute accuracy eliminates the inherent errors of global positioning sensors present in real experiments, facilitating detailed analysis and evaluation of the algorithms. By utilizing the simulation platform, developers can overcome the limitations of real environments and datasets, enabling fine-grained analysis and evaluation of mainstream SLAM algorithms in various environments. Experiments conducted in different environments and with different LIDARs demonstrate the wide applicability and practicality of our simulation platform. The implementation of the simulation platform is open-sourced on Github.
VoxelMap++: Mergeable Voxel Mapping Method for Online LiDAR(-inertial) Odometry
Aug 05, 2023



This paper presents VoxelMap++: a voxel mapping method with plane merging which can effectively improve the accuracy and efficiency of LiDAR(-inertial) based simultaneous localization and mapping (SLAM). This map is a collection of voxels that contains one plane feature with 3DOF representation and corresponding covariance estimation. Considering total map will contain a large number of coplanar features (kid planes), these kid planes' 3DOF estimation can be regarded as the measurements with covariance of a larger plane (father plane). Thus, we design a plane merging module based on union-find which can save resources and further improve the accuracy of plane fitting. This module can distinguish the kid planes in different voxels and merge these kid planes to estimate the father plane. After merging, the father plane 3DOF representation will be more accurate than the kids plane and the uncertainty will decrease significantly which can further improve the performance of LiDAR(-inertial) odometry. Experiments on challenging environments such as corridors and forests demonstrate the high accuracy and efficiency of our method compared to other state-of-the-art methods (see our attached video). By the way, our implementation VoxelMap++ is open-sourced on GitHub which is applicable for both non-repetitive scanning LiDARs and traditional scanning LiDAR.
History-Aware Hierarchical Transformer for Multi-session Open-domain Dialogue System
Feb 02, 2023With the evolution of pre-trained language models, current open-domain dialogue systems have achieved great progress in conducting one-session conversations. In contrast, Multi-Session Conversation (MSC), which consists of multiple sessions over a long term with the same user, is under-investigated. In this paper, we propose History-Aware Hierarchical Transformer (HAHT) for multi-session open-domain dialogue. HAHT maintains a long-term memory of history conversations and utilizes history information to understand current conversation context and generate well-informed and context-relevant responses. Specifically, HAHT first encodes history conversation sessions hierarchically into a history memory. Then, HAHT leverages historical information to facilitate the understanding of the current conversation context by encoding the history memory together with the current context with attention-based mechanisms. Finally, to explicitly utilize historical information, HAHT uses a history-aware response generator that switches between a generic vocabulary and a history-aware vocabulary. Experimental results on a large-scale MSC dataset suggest that the proposed HAHT model consistently outperforms baseline models. Human evaluation results support that HAHT generates more human-like, context-relevant and history-relevant responses than baseline models.
McQueen: a Benchmark for Multimodal Conversational Query Rewrite
Oct 23, 2022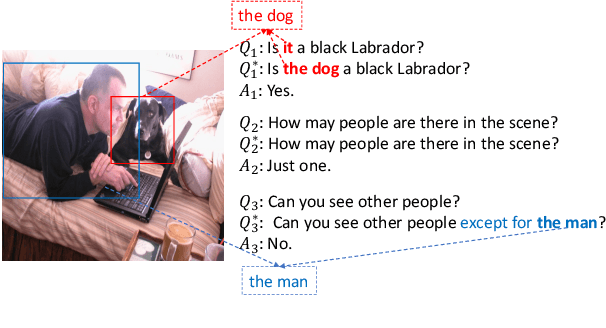

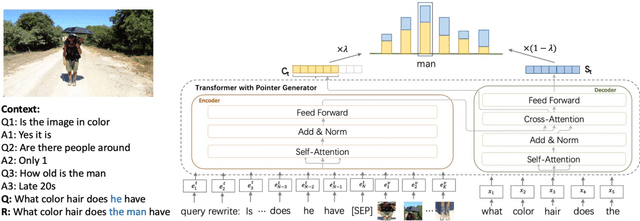
The task of query rewrite aims to convert an in-context query to its fully-specified version where ellipsis and coreference are completed and referred-back according to the history context. Although much progress has been made, less efforts have been paid to real scenario conversations that involve drawing information from more than one modalities. In this paper, we propose the task of multimodal conversational query rewrite (McQR), which performs query rewrite under the multimodal visual conversation setting. We collect a large-scale dataset named McQueen based on manual annotation, which contains 15k visual conversations and over 80k queries where each one is associated with a fully-specified rewrite version. In addition, for entities appearing in the rewrite, we provide the corresponding image box annotation. We then use the McQueen dataset to benchmark a state-of-the-art method for effectively tackling the McQR task, which is based on a multimodal pre-trained model with pointer generator. Extensive experiments are performed to demonstrate the effectiveness of our model on this task\footnote{The dataset and code of this paper are both available in \url{https://github.com/yfyuan01/MQR}
Bootstrap Latent Representations for Multi-modal Recommendation
Jul 13, 2022


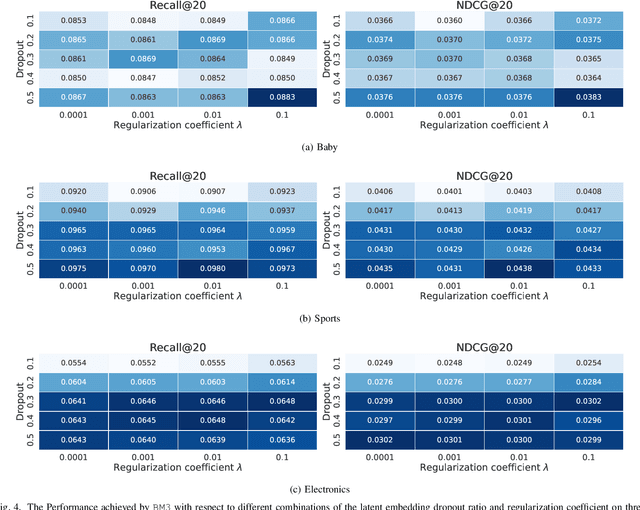
This paper studies the multi-modal recommendation problem, where the item multi-modality information (eg. images and textual descriptions) is exploited to improve the recommendation accuracy. Besides the user-item interaction graph, existing state-of-the-art methods usually use auxiliary graphs (eg. user-user or item-item relation graph) to augment the learned representations of users and/or items. These representations are often propagated and aggregated on auxiliary graphs using graph convolutional networks, which can be prohibitively expensive in computation and memory, especially for large graphs. Moreover, existing multi-modal recommendation methods usually leverage randomly sampled negative examples in Bayesian Personalized Ranking (BPR) loss to guide the learning of user/item representations, which increases the computational cost on large graphs and may also bring noisy supervision signals into the training process. To tackle the above issues, we propose a novel self-supervised multi-modal recommendation model, dubbed BM3, which requires neither augmentations from auxiliary graphs nor negative samples. Specifically, BM3 first bootstraps latent contrastive views from the representations of users and items with a simple dropout augmentation. It then jointly optimizes three multi-modal objectives to learn the representations of users and items by reconstructing the user-item interaction graph and aligning modality features under both inter- and intra-modality perspectives. BM3 alleviates both the need for contrasting with negative examples and the complex graph augmentation from an additional target network for contrastive view generation. We show BM3 outperforms prior recommendation models on three datasets with number of nodes ranging from 20K to 200K, while achieving a 2-9X reduction in training time. Our code is available at https://github.com/enoche/BM3.
Large scale classification in deep neural network with Label Mapping
Jun 07, 2018
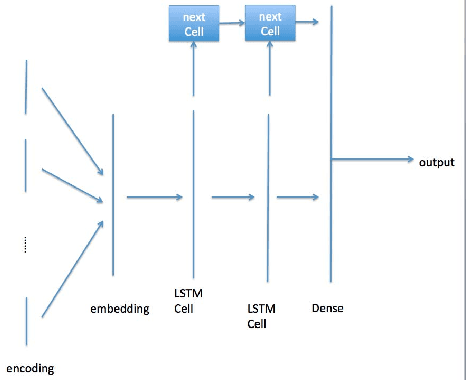
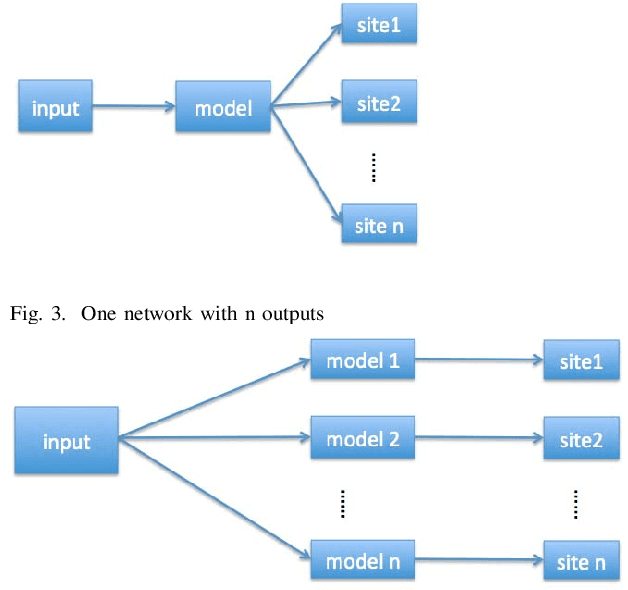
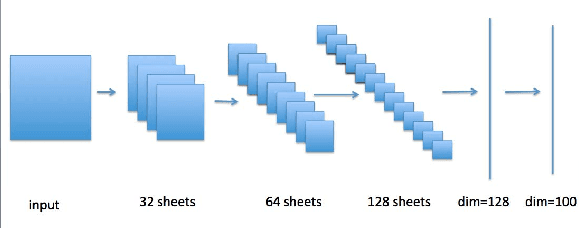
In recent years, deep neural network is widely used in machine learning. The multi-class classification problem is a class of important problem in machine learning. However, in order to solve those types of multi-class classification problems effectively, the required network size should have hyper-linear growth with respect to the number of classes. Therefore, it is infeasible to solve the multi-class classification problem using deep neural network when the number of classes are huge. This paper presents a method, so called Label Mapping (LM), to solve this problem by decomposing the original classification problem to several smaller sub-problems which are solvable theoretically. Our method is an ensemble method like error-correcting output codes (ECOC), but it allows base learners to be multi-class classifiers with different number of class labels. We propose two design principles for LM, one is to maximize the number of base classifier which can separate two different classes, and the other is to keep all base learners to be independent as possible in order to reduce the redundant information. Based on these principles, two different LM algorithms are derived using number theory and information theory. Since each base learner can be trained independently, it is easy to scale our method into a large scale training system. Experiments show that our proposed method outperforms the standard one-hot encoding and ECOC significantly in terms of accuracy and model complexity.