 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrap Latent Representations for Multi-modal Recommendation
Paper and Code



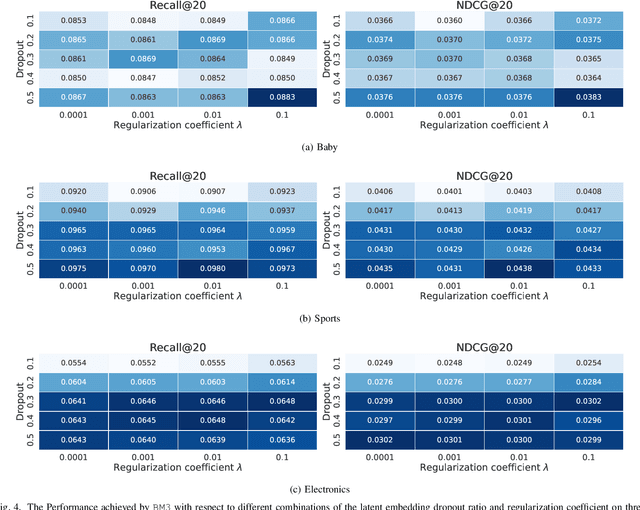
This paper studies the multi-modal recommendation problem, where the item multi-modality information (eg. images and textual descriptions) is exploited to improve the recommendation accuracy. Besides the user-item interaction graph, existing state-of-the-art methods usually use auxiliary graphs (eg. user-user or item-item relation graph) to augment the learned representations of users and/or items. These representations are often propagated and aggregated on auxiliary graphs using graph convolutional networks, which can be prohibitively expensive in computation and memory, especially for large graphs. Moreover, existing multi-modal recommendation methods usually leverage randomly sampled negative examples in Bayesian Personalized Ranking (BPR) loss to guide the learning of user/item representations, which increases the computational cost on large graphs and may also bring noisy supervision signals into the training process. To tackle the above issues, we propose a novel self-supervised multi-modal recommendation model, dubbed BM3, which requires neither augmentations from auxiliary graphs nor negative samples. Specifically, BM3 first bootstraps latent contrastive views from the representations of users and items with a simple dropout augmentation. It then jointly optimizes three multi-modal objectives to learn the representations of users and items by reconstructing the user-item interaction graph and aligning modality features under both inter- and intra-modality perspectives. BM3 alleviates both the need for contrasting with negative examples and the complex graph augmentation from an additional target network for contrastive view generation. We show BM3 outperforms prior recommendation models on three datasets with number of nodes ranging from 20K to 200K, while achieving a 2-9X reduction in training time. Our code is available at https://github.com/enoche/BM3.