 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Dropout-Induced Modality Bias on Robustness to Missing Video Frames for Audio-Visual Speech Recognition
Paper and Code
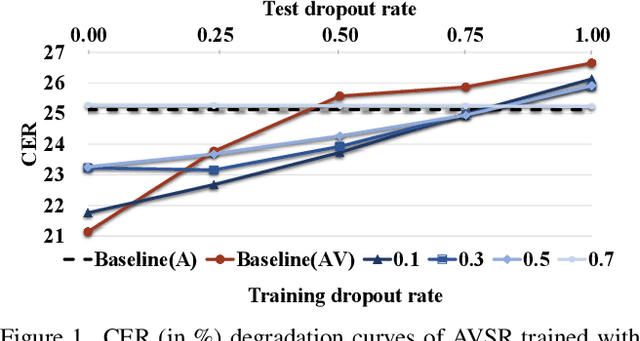

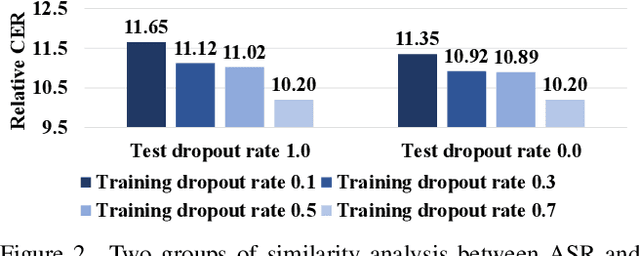
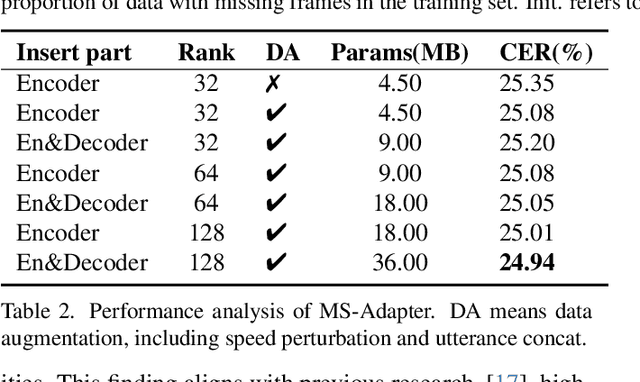
Advanced Audio-Visual Speech Recognition (AVSR) systems have been observed to be sensitive to missing video frames, performing even worse than single-modality models. While applying the dropout technique to the video modality enhances robustness to missing frames, it simultaneously results in a performance loss when dealing with complete data input. In this paper, we investigate this contrasting phenomenon from the perspective of modality bias and reveal that an excessive modality bias on the audio caused by dropout is the underlying reason. Moreover, we present the Modality Bias Hypothesis (MBH) to systematically describe the relationship between modality bias and robustness against missing modality in multimodal systems. Building on these findings, we propose a novel Multimodal Distribution Approximation with Knowledge Distillation (MDA-KD) framework to reduce over-reliance on the audio modality and to maintain performance and robustness simultaneously. Finally, to address an entirely missing modality, we adopt adapters to dynamically switch decision strategies. The effectiveness of our proposed approach is evaluated and validated through a series of comprehensive experiments using the MISP2021 and MISP2022 datasets. Our code is available at https://github.com/dalision/ModalBiasAVSR