 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Voice Anonymization Using Adversarial Perturbation On Speaker Embedding
Paper and Code
Jun 12, 2024


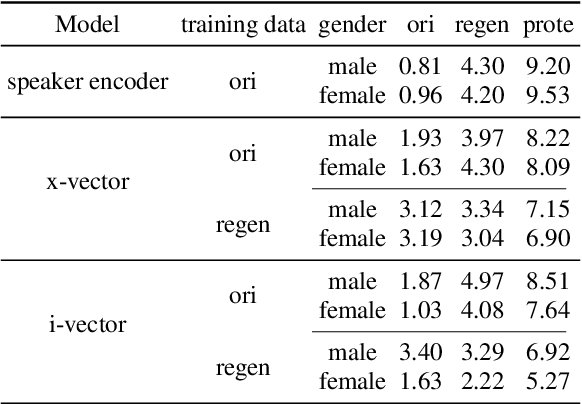
Voice anonymization has been developed as a technique for preserving privacy by replacing the speaker's voice in a speech signal with that of a pseudo-speaker, thereby obscuring the original voice attributes from machine recognition and human perception. In this paper, we focus on altering the voice attributes against machine recognition while retaining human perception. We referred to this as the asynchronous voice anonymization. To this end, a speech generation framework incorporating a speaker disentanglement mechanism is employed to generate the anonymized speech. The speaker attributes are altered through adversarial perturbation applied on the speaker embedding, while human perception is preserved by controlling the intensity of perturbation. Experiments conducted on the LibriSpeech dataset showed that the speaker attributes were obscured with their human perception preserved for 60.71% of the processed utterances.