 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Physical Risk Control in the Era of Foundation Model-enabled Robotics
May 19, 2025Recent Foundation Model-enabled robotics (FMRs) display greatly improved general-purpose skills, enabling more adaptable automation than conventional robotics. Their ability to handle diverse tasks thus creates new opportunities to replace human labor. However, unlike general foundation models, FMRs interact with the physical world, where their actions directly affect the safety of humans and surrounding objects, requiring careful deployment and control. Based on this proposition, our survey comprehensively summarizes robot control approaches to mitigate physical risks by covering all the lifespan of FMRs ranging from pre-deployment to post-accident stage. Specifically, we broadly divide the timeline into the following three phases: (1) pre-deployment phase, (2) pre-incident phase, and (3) post-incident phase. Throughout this survey, we find that there is much room to study (i) pre-incident risk mitigation strategies, (ii) research that assumes physical interaction with humans, and (iii) essential issues of foundation models themselves. We hope that this survey will be a milestone in providing a high-resolution analysis of the physical risks of FMRs and their control, contributing to the realization of a good human-robot relationship.
Near-Optimal Policy Identification in Robust Constrained Markov Decision Processes via Epigraph Form
Sep 02, 2024Designing a safe policy for uncertain environments is crucial in real-world control applications. However, this challenge remains inadequately addressed within the Markov decision process (MDP) framework. This paper presents the first algorithm capable of identifying a near-optimal policy in a robust constrained MDP (RCMDP), where an optimal policy minimizes cumulative cost while satisfying constraints in the worst-case scenario across a set of environments. We first prove that the conventional Lagrangian max-min formulation with policy gradient methods can become trapped in suboptimal solutions by encountering a sum of conflicting gradients from the objective and constraint functions during its inner minimization problem. To address this, we leverage the epigraph form of the RCMDP problem, which resolves the conflict by selecting a single gradient from either the objective or the constraints. Building on the epigraph form, we propose a binary search algorithm with a policy gradient subroutine and prove that it identifies an $\varepsilon$-optimal policy in an RCMDP with $\tilde{\mathcal{O}}(\varepsilon^{-4})$ policy evaluations.
A Policy Gradient Primal-Dual Algorithm for Constrained MDPs with Uniform PAC Guarantees
Feb 02, 2024

We study a primal-dual reinforcement learning (RL) algorithm for the online constrained Markov decision processes (CMDP) problem, wherein the agent explores an optimal policy that maximizes return while satisfying constraints. Despite its widespread practical use, the existing theoretical literature on primal-dual RL algorithms for this problem only provides sublinear regret guarantees and fails to ensure convergence to optimal policies. In this paper, we introduce a novel policy gradient primal-dual algorithm with uniform probably approximate correctness (Uniform-PAC) guarantees, simultaneously ensuring convergence to optimal policies, sublinear regret, and polynomial sample complexity for any target accuracy. Notably, this represents the first Uniform-PAC algorithm for the online CMDP problem. In addition to the theoretical guarantees, we empirically demonstrate in a simple CMDP that our algorithm converges to optimal policies, while an existing algorithm exhibits oscillatory performance and constraint violation.
Regularization and Variance-Weighted Regression Achieves Minimax Optimality in Linear MDPs: Theory and Practice
May 22, 2023Mirror descent value iteration (MDVI), an abstraction of Kullback-Leibler (KL) and entropy-regularized reinforcement learning (RL), has served as the basis for recent high-performing practical RL algorithms. However, despite the use of function approximation in practice, the theoretical understanding of MDVI has been limited to tabular Markov decision processes (MDPs). We study MDVI with linear function approximation through its sample complexity required to identify an $\varepsilon$-optimal policy with probability $1-\delta$ under the settings of an infinite-horizon linear MDP, generative model, and G-optimal design. We demonstrate that least-squares regression weighted by the variance of an estimated optimal value function of the next state is crucial to achieving minimax optimality. Based on this observation, we present Variance-Weighted Least-Squares MDVI (VWLS-MDVI), the first theoretical algorithm that achieves nearly minimax optimal sample complexity for infinite-horizon linear MDPs. Furthermore, we propose a practical VWLS algorithm for value-based deep RL, Deep Variance Weighting (DVW). Our experiments demonstrate that DVW improves the performance of popular value-based deep RL algorithms on a set of MinAtar benchmarks.
KL-Entropy-Regularized RL with a Generative Model is Minimax Optimal
May 27, 2022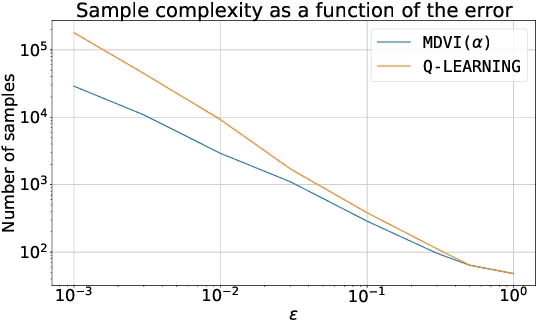

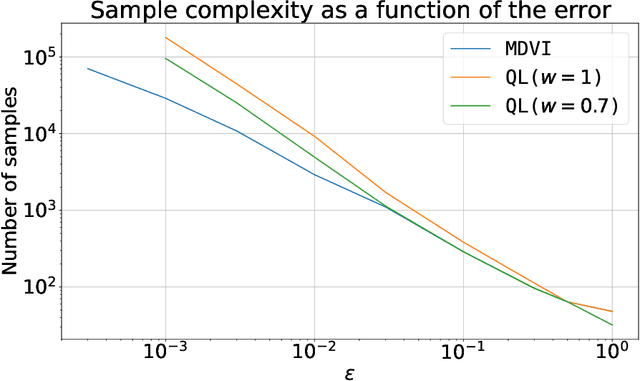
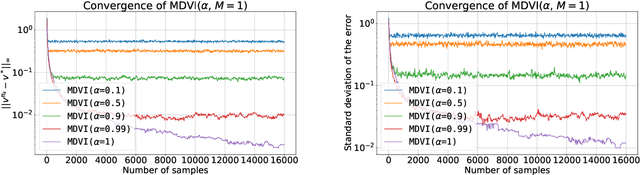
In this work, we consider and analyze the sample complexity of model-free reinforcement learning with a generative model. Particularly, we analyze mirror descent value iteration (MDVI) by Geist et al. (2019) and Vieillard et al. (2020a), which uses the Kullback-Leibler divergence and entropy regularization in its value and policy updates. Our analysis shows that it is nearly minimax-optimal for finding an $\varepsilon$-optimal policy when $\varepsilon$ is sufficiently small. This is the first theoretical result that demonstrates that a simple model-free algorithm without variance-reduction can be nearly minimax-optimal under the considered setting.
ShinRL: A Library for Evaluating RL Algorithms from Theoretical and Practical Perspectives
Dec 08, 2021



We present ShinRL, an open-source library specialized for the evaluation of reinforcement learning (RL) algorithms from both theoretical and practical perspectives. Existing RL libraries typically allow users to evaluate practical performances of deep RL algorithms through returns. Nevertheless, these libraries are not necessarily useful for analyzing if the algorithms perform as theoretically expected, such as if Q learning really achieves the optimal Q function. In contrast, ShinRL provides an RL environment interface that can compute metrics for delving into the behaviors of RL algorithms, such as the gap between learned and the optimal Q values and state visitation frequencies. In addition, we introduce a flexible solver interface for evaluating both theoretically justified algorithms (e.g., dynamic programming and tabular RL) and practically effective ones (i.e., deep RL, typically with some additional extensions and regularizations) in a consistent fashion. As a case study, we show that how combining these two features of ShinRL makes it easier to analyze the behavior of deep Q learning. Furthermore, we demonstrate that ShinRL can be used to empirically validate recent theoretical findings such as the effect of KL regularization for value iteration and for deep Q learning, and the robustness of entropy-regularized policies to adversarial rewards. The source code for ShinRL is available on GitHub: https://github.com/omron-sinicx/ShinRL.
Geometric Value Iteration: Dynamic Error-Aware KL Regularization for Reinforcement Learning
Jul 16, 2021


The recent booming of entropy-regularized literature reveals that Kullback-Leibler (KL) regularization brings advantages to Reinforcement Learning (RL) algorithms by canceling out errors under mild assumptions. However, existing analyses focus on fixed regularization with a constant weighting coefficient and have not considered the case where the coefficient is allowed to change dynamically. In this paper, we study the dynamic coefficient scheme and present the first asymptotic error bound. Based on the dynamic coefficient error bound, we propose an effective scheme to tune the coefficient according to the magnitude of error in favor of more robust learning. On top of this development, we propose a novel algorithm: Geometric Value Iteration (GVI) that features a dynamic error-aware KL coefficient design aiming to mitigate the impact of errors on the performance. Our experiments demonstrate that GVI can effectively exploit the trade-off between learning speed and robustness over uniform averaging of constant KL coefficient. The combination of GVI and deep networks shows stable learning behavior even in the absence of a target network where algorithms with a constant KL coefficient would greatly oscillate or even fail to converge.
Cautious Policy Programming: Exploiting KL Regularization in Monotonic Policy Improvement for Reinforcement Learning
Jul 13, 2021
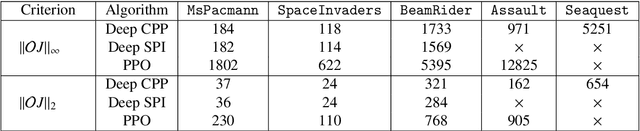


In this paper, we propose cautious policy programming (CPP), a novel value-based reinforcement learning (RL) algorithm that can ensure monotonic policy improvement during learning. Based on the nature of entropy-regularized RL, we derive a new entropy regularization-aware lower bound of policy improvement that only requires estimating the expected policy advantage function. CPP leverages this lower bound as a criterion for adjusting the degree of a policy update for alleviating policy oscillation. Different from similar algorithms that are mostly theory-oriented, we also propose a novel interpolation scheme that makes CPP better scale in high dimensional control problems. We demonstrate that the proposed algorithm can trade o? performance and stability in both didactic classic control problems and challenging high-dimensional Atari games.
Cautious Actor-Critic
Jul 12, 2021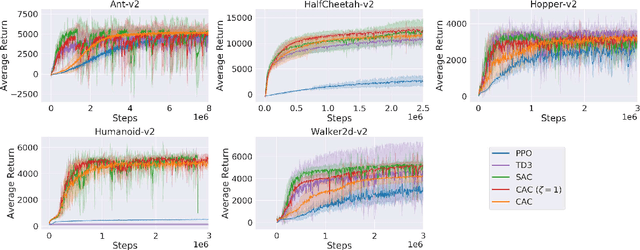


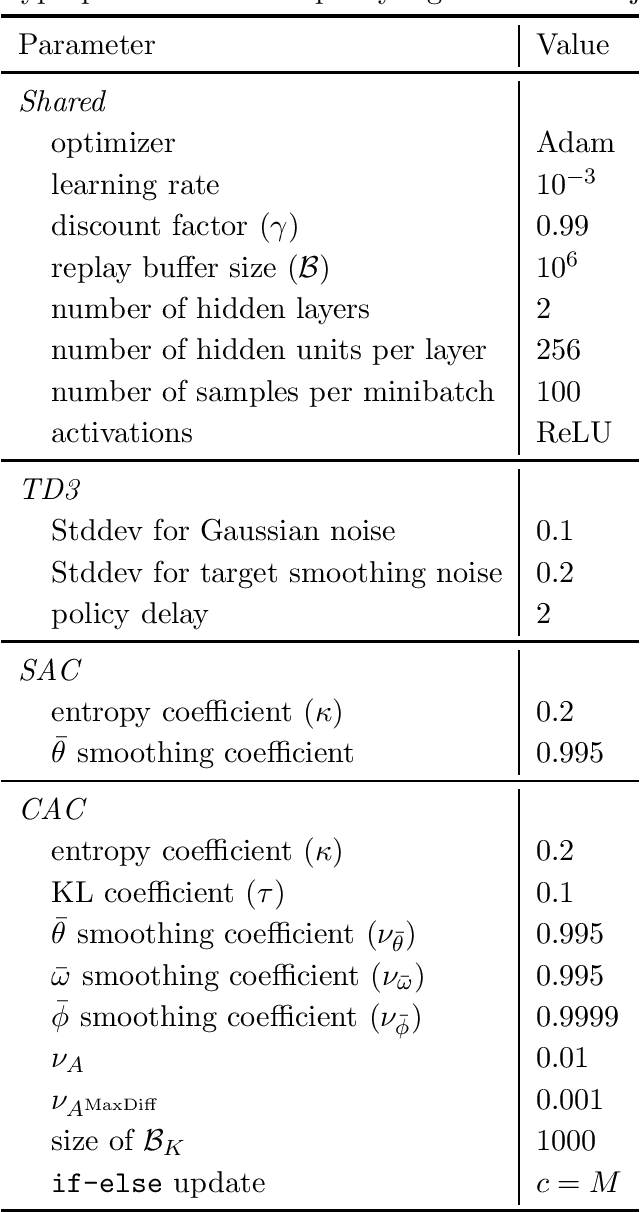
The oscillating performance of off-policy learning and persisting errors in the actor-critic (AC) setting call for algorithms that can conservatively learn to suit the stability-critical applications better. In this paper, we propose a novel off-policy AC algorithm cautious actor-critic (CAC). The name cautious comes from the doubly conservative nature that we exploit the classic policy interpolation from conservative policy iteration for the actor and the entropy-regularization of conservative value iteration for the critic. Our key observation is the entropy-regularized critic facilitates and simplifies the unwieldy interpolated actor update while still ensuring robust policy improvement. We compare CAC to state-of-the-art AC methods on a set of challenging continuous control problems and demonstrate that CAC achieves comparable performance while significantly stabilizes learning.