 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence of Exploration in Policy Gradient Reinforcement Learning via Retrying
May 29, 2026In reinforcement learning (RL), agents benefit from exploration only because they repeatedly encounter similar states: trying different actions can improve performance or reduce uncertainty; without such retries, a greedy policy is optimal. We formalize this intuition with ReMax, an objective that evaluates a policy by the expected maximum return over $M$ samples, where $M$ is a positive integer, while accounting for return uncertainty. Optimizing this objective induces stochastic exploration as an emergent property, without explicit bonus terms. For efficient policy optimization, we derive a new policy-gradient formulation for ReMax and introduce ReMax PPO (RePPO), a PPO variant that optimizes ReMax while generalizing the discrete retry count $M$ to a continuous parameter $m > 0$, enabling fine-grained control of exploration. Empirically, RePPO promotes exploration, without any explicit exploration bonuses, on the MinAtar and Craftax benchmarks.
Finite-Time Regret Analysis of Retry-Aware Bandits
May 20, 2026We study a stochastic bandit algorithm motivated by retry-aware objectives that value the best outcome among multiple attempts, such as pass@$k$ and max@$k$. Given a posterior over arm values, ReMax chooses a sampling distribution that maximizes the posterior expected maximum reward over $M$ virtual draws. Although this objective was introduced in reinforcement learning as an exploration mechanism under uncertainty, its regret properties in bandit problems have remained unclear. For Gaussian rewards and the first nontrivial case $M=2$, we characterize the optimal ReMax distribution through an expected-improvement balance condition and prove the first sublinear regret bound for ReMax. Our analysis separates the usual saturation behavior of suboptimal arms from a ReMax-specific underestimation effect, in which the optimal arm may be sampled too rarely after an unfavorable estimate. This explains why ReMax can be more exploitative than Thompson sampling (TS) and why its regret analysis is technically delicate. Experiments support this picture: ReMax often outperforms KL-UCB and Thompson sampling under mild underestimation, while posterior-variance scaling empirically mitigates severe underestimation.
Does "Do Differentiable Simulators Give Better Policy Gradients?'' Give Better Policy Gradients?
Apr 20, 2026In policy gradient reinforcement learning, access to a differentiable model enables 1st-order gradient estimation that accelerates learning compared to relying solely on derivative-free 0th-order estimators. However, discontinuous dynamics cause bias and undermine the effectiveness of 1st-order estimators. Prior work addressed this bias by constructing a confidence interval around the REINFORCE 0th-order gradient estimator and using these bounds to detect discontinuities. However, the REINFORCE estimator is notoriously noisy, and we find that this method requires task-specific hyperparameter tuning and has low sample efficiency. This paper asks whether such bias is the primary obstacle and what minimal fixes suffice. First, we re-examine standard discontinuous settings from prior work and introduce DDCG, a lightweight test that switches estimators in nonsmooth regions; with a single hyperparameter, DDCG achieves robust performance and remains reliable with small samples. Second, on differentiable robotics control tasks, we present IVW-H, a per-step inverse-variance implementation that stabilizes variance without explicit discontinuity detection and yields strong results. Together, these findings indicate that while estimator switching improves robustness in controlled studies, careful variance control often dominates in practical deployments.
* ICLR2026
Double Horizon Model-Based Policy Optimization
Dec 17, 2025Model-based reinforcement learning (MBRL) reduces the cost of real-environment sampling by generating synthetic trajectories (called rollouts) from a learned dynamics model. However, choosing the length of the rollouts poses two dilemmas: (1) Longer rollouts better preserve on-policy training but amplify model bias, indicating the need for an intermediate horizon to mitigate distribution shift (i.e., the gap between on-policy and past off-policy samples). (2) Moreover, a longer model rollout may reduce value estimation bias but raise the variance of policy gradients due to backpropagation through multiple steps, implying another intermediate horizon for stable gradient estimates. However, these two optimal horizons may differ. To resolve this conflict, we propose Double Horizon Model-Based Policy Optimization (DHMBPO), which divides the rollout procedure into a long "distribution rollout" (DR) and a short "training rollout" (TR). The DR generates on-policy state samples for mitigating distribution shift. In contrast, the short TR leverages differentiable transitions to offer accurate value gradient estimation with stable gradient updates, thereby requiring fewer updates and reducing overall runtime. We demonstrate that the double-horizon approach effectively balances distribution shift, model bias, and gradient instability, and surpasses existing MBRL methods on continuous-control benchmarks in terms of both sample efficiency and runtime.
Near-Optimal Policy Identification in Robust Constrained Markov Decision Processes via Epigraph Form
Sep 02, 2024


Designing a safe policy for uncertain environments is crucial in real-world control applications. However, this challenge remains inadequately addressed within the Markov decision process (MDP) framework. This paper presents the first algorithm capable of identifying a near-optimal policy in a robust constrained MDP (RCMDP), where an optimal policy minimizes cumulative cost while satisfying constraints in the worst-case scenario across a set of environments. We first prove that the conventional Lagrangian max-min formulation with policy gradient methods can become trapped in suboptimal solutions by encountering a sum of conflicting gradients from the objective and constraint functions during its inner minimization problem. To address this, we leverage the epigraph form of the RCMDP problem, which resolves the conflict by selecting a single gradient from either the objective or the constraints. Building on the epigraph form, we propose a binary search algorithm with a policy gradient subroutine and prove that it identifies an $\varepsilon$-optimal policy in an RCMDP with $\tilde{\mathcal{O}}(\varepsilon^{-4})$ policy evaluations.
A unified view of likelihood ratio and reparameterization gradients
May 31, 2021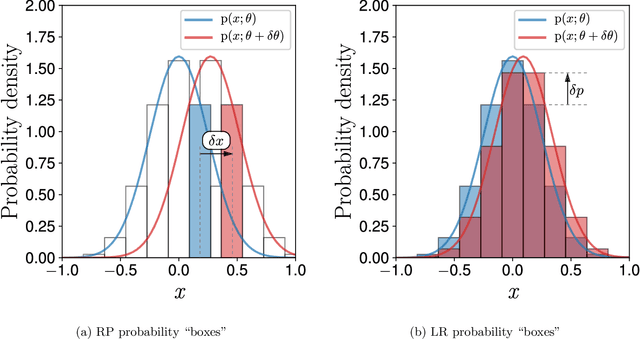
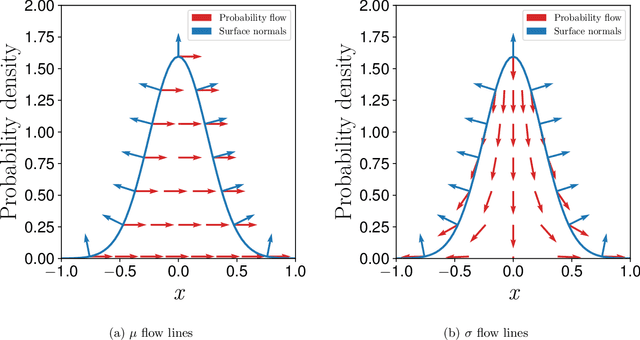


Reparameterization (RP) and likelihood ratio (LR) gradient estimators are used to estimate gradients of expectations throughout machine learning and reinforcement learning; however, they are usually explained as simple mathematical tricks, with no insight into their nature. We use a first principles approach to explain that LR and RP are alternative methods of keeping track of the movement of probability mass, and the two are connected via the divergence theorem. Moreover, we show that the space of all possible estimators combining LR and RP can be completely parameterized by a flow field $u(x)$ and an importance sampling distribution $q(x)$. We prove that there cannot exist a single-sample estimator of this type outside our characterized space, thus, clarifying where we should be searching for better Monte Carlo gradient estimators.
* AISTATS2021; Earlier paper was split in two (arXiv:1910.06419). Refer to the current paper for the unified view, but see the earlier paper for discussion on an importance sampling technique
A unified view of likelihood ratio and reparameterization gradients and an optimal importance sampling scheme
Oct 14, 2019Reparameterization (RP) and likelihood ratio (LR) gradient estimators are used throughout machine and reinforcement learning; however, they are usually explained as simple mathematical tricks without providing any insight into their nature. We use a first principles approach to explain LR and RP, and show a connection between the two via the divergence theorem. The theory motivated us to derive optimal importance sampling schemes to reduce LR gradient variance. Our newly derived distributions have analytic probability densities and can be directly sampled from. The improvement for Gaussian target distributions was modest, but for other distributions such as a Beta distribution, our method could lead to arbitrarily large improvements, and was crucial to obtain competitive performance in evolution strategies experiments.
Total stochastic gradient algorithms and applications in reinforcement learning
Feb 05, 2019
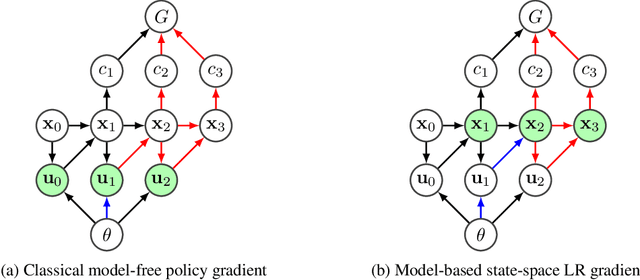
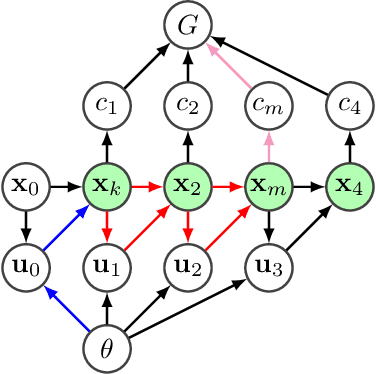
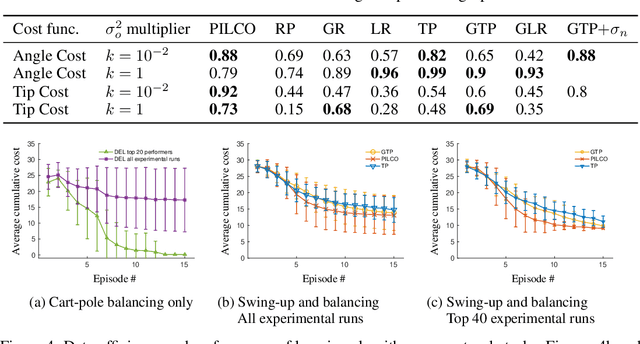
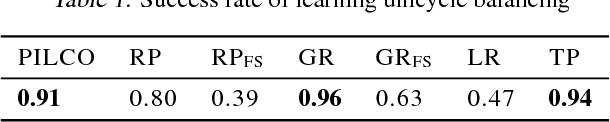
Backpropagation and the chain rule of derivatives have been prominent; however, the total derivative rule has not enjoyed the same amount of attention. In this work we show how the total derivative rule leads to an intuitive visual framework for creating gradient estimators on graphical models. In particular, previous "policy gradient theorems" are easily derived. We derive new gradient estimators based on density estimation, as well as a likelihood ratio gradient, which "jumps" to an intermediate node, not directly to the objective function. We evaluate our methods on model-based policy gradient algorithms, achieve good performance, and present evidence towards demystifying the success of the popular PILCO algorithm.
PIPPS: Flexible Model-Based Policy Search Robust to the Curse of Chaos
Feb 04, 2019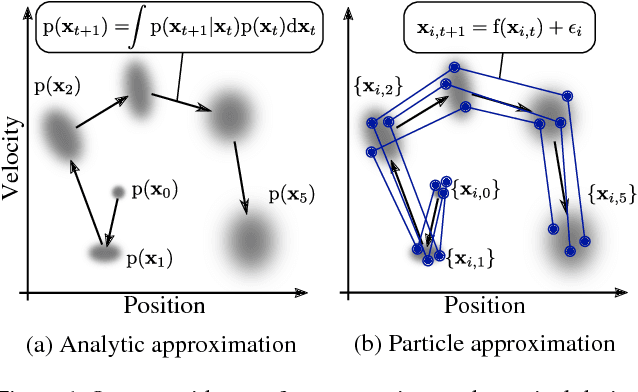
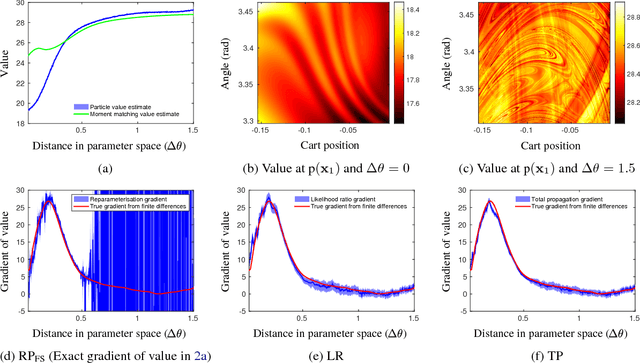

Previously, the exploding gradient problem has been explained to be central in deep learning and model-based reinforcement learning, because it causes numerical issues and instability in optimization. Our experiments in model-based reinforcement learning imply that the problem is not just a numerical issue, but it may be caused by a fundamental chaos-like nature of long chains of nonlinear computations. Not only do the magnitudes of the gradients become large, the direction of the gradients becomes essentially random. We show that reparameterization gradients suffer from the problem, while likelihood ratio gradients are robust. Using our insights, we develop a model-based policy search framework, Probabilistic Inference for Particle-Based Policy Search (PIPPS), which is easily extensible, and allows for almost arbitrary models and policies, while simultaneously matching the performance of previous data-efficient learning algorithms. Finally, we invent the total propagation algorithm, which efficiently computes a union over all pathwise derivative depths during a single backwards pass, automatically giving greater weight to estimators with lower variance, sometimes improving over reparameterization gradients by $10^6$ times.