 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCautious Actor-Critic
Paper and Code
Jul 12, 2021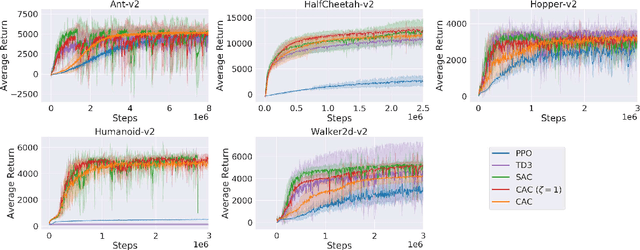


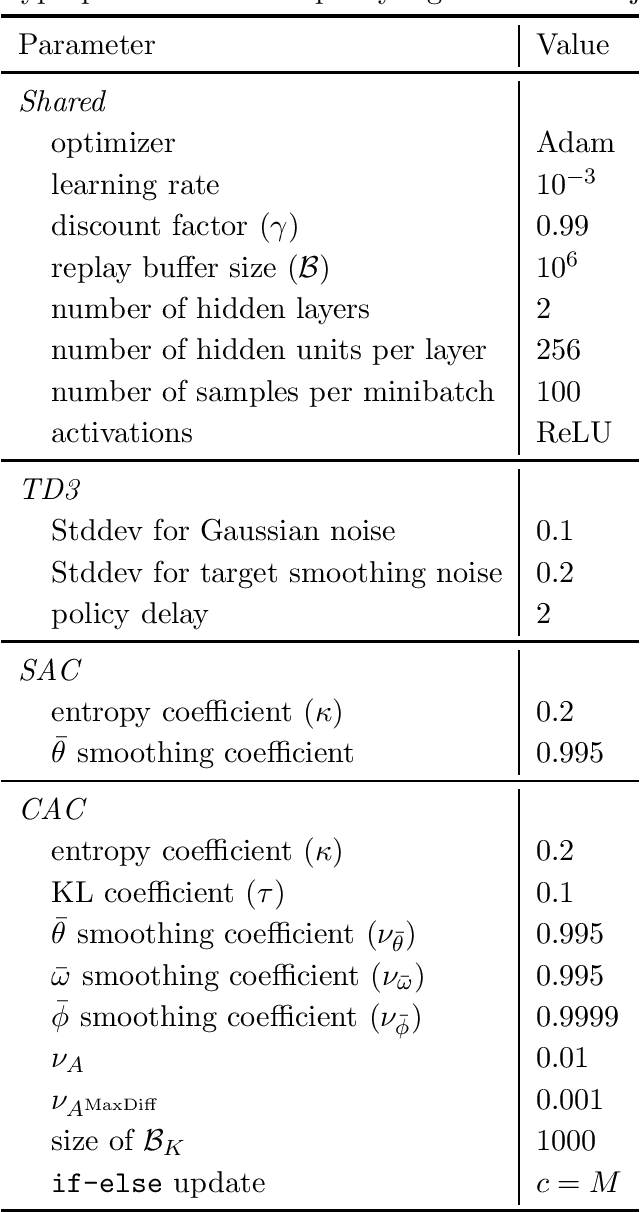
The oscillating performance of off-policy learning and persisting errors in the actor-critic (AC) setting call for algorithms that can conservatively learn to suit the stability-critical applications better. In this paper, we propose a novel off-policy AC algorithm cautious actor-critic (CAC). The name cautious comes from the doubly conservative nature that we exploit the classic policy interpolation from conservative policy iteration for the actor and the entropy-regularization of conservative value iteration for the critic. Our key observation is the entropy-regularized critic facilitates and simplifies the unwieldy interpolated actor update while still ensuring robust policy improvement. We compare CAC to state-of-the-art AC methods on a set of challenging continuous control problems and demonstrate that CAC achieves comparable performance while significantly stabilizes learning.