 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinning Lottery Tickets in Neural Networks via a Quantum-Inspired Classical Algorithm
May 13, 2026Quantum machine learning (QML) aims to accelerate machine learning tasks by exploiting quantum computation. Previous work studied a QML algorithm for selecting sparse subnetworks from large shallow neural networks. Instead of directly solving an optimization problem over a large-scale network, this algorithm constructs a sparse subnetwork by sampling hidden nodes from an optimized probability distribution defined using the ridgelet transform. The quantum algorithm performs this sampling in time $O(D)$ in the data dimension $D$, whereas a naive classical implementation relies on handling exponentially many candidate nodes and hence takes $\exp[O(D)]$ time. In this work, we construct and analyze a quantum-inspired fully classical algorithm for the same sampling task. We show that our algorithm runs in time $O(\operatorname{poly}(D))$, thereby removing the exponential dependence on $D$ from the previous classical approach. Numerical simulations show that the proposed sampler achieves empirical risk comparable to exact sampling from the optimized distribution and substantially lower than sampling from the non-optimized uniform distribution, while also exhibiting exponentially improved runtime scaling compared with the conventional classical implementation. These successful dequantization results show that sparse subnetwork selection via optimized sampling can be achieved classically with polynomial data-dimension scaling on conventional computers without quantum hardware, providing an alternative to the existing quantum algorithm.
Generalization Error Bounds for Picard-Type Operator Learning in Nonlinear Parabolic PDEs
May 11, 2026Operator learning for partial differential equations (PDEs) aims to learn solution operators on infinite-dimensional function spaces from finite-resolution data. In this setting, it is important for the learned model to be discretization-invariant, or resolution-robust, and to reflect PDE-specific structure. It is therefore natural to ask how such structure should be encoded in the model architecture, hypothesis class, or learning procedure. In this paper, we study operator learning for solution operators of nonlinear parabolic PDEs based on Duhamel--Picard iteration. We formulate Picard iteration as an abstract state-transition model and present a theoretical framework for Picard-type operator learning. We derive implementation-agnostic generalization error bounds that separate the implementation error from the estimation error associated with the abstract state-transition model induced by Picard iteration. A key consequence is that increasing the Picard depth reduces the Picard truncation error without causing an unbounded growth of the entropy-based estimation error. We also extend the analysis to long-time prediction by rolling out the same learned local model over successive time blocks. Finally, we illustrate the theory for nonlinear heat equations on the torus using a Picard-type Fourier neural operator as a concrete implementation.
Why Agentic Theorem Prover Works: A Statistical Provability Theory of Mathematical Reasoning Models
Feb 12, 2026Agentic theorem provers -- pipelines that couple a mathematical reasoning model with library retrieval, subgoal-decomposition/search planner, and a proof assistant verifier -- have recently achieved striking empirical success, yet it remains unclear which components drive performance and why such systems work at all despite classical hardness of proof search. We propose a distributional viewpoint and introduce \textbf{statistical provability}, defined as the finite-horizon success probability of reaching a verified proof, averaged over an instance distribution, and formalize modern theorem-proving pipelines as time-bounded MDPs. Exploiting Bellman structure, we prove existence of optimal policies under mild regularity, derive provability certificates via sub-/super-solution inequalities, and bound the performance gap of score-guided planning (greedy/top-\(k\)/beam/rollouts) in terms of approximation error, sequential statistical complexity, representation geometry (metric entropy/doubling structure), and action-gap margin tails. Together, our theory provides a principled, component-sensitive explanation of when and why agentic theorem provers succeed on biased real-world problem distributions, while clarifying limitations in worst-case or adversarial regimes.
Don't Eliminate Cut: Exponential Separations in LLM-Based Theorem Proving
Feb 11, 2026We develop a theoretical analysis of LLM-guided formal theorem proving in interactive proof assistants (e.g., Lean) by modeling tactic proposal as a stochastic policy in a finite-horizon deterministic MDP. To capture modern representation learning, we treat the state and action spaces as general compact metric spaces and assume Lipschitz policies. To explain the gap between worst-case hardness and empirical success, we introduce problem distributions generated by a reference policy $q$, including a latent-variable model in which proofs exhibit reusable cut/lemma/sketch structure represented by a proof DAG. Under a top-$k$ search protocol and Tsybakov-type margin conditions, we derive lower bounds on finite-horizon success probability that decompose into search and learning terms, with learning controlled by sequential Rademacher/covering complexity. Our main separation result shows that when cut elimination expands a DAG of depth $D$ into a cut-free tree of size $Ω(Λ^D)$ while the cut-aware hierarchical process has size $O(λ^D)$ with $λ\llΛ$, a flat (cut-free) learner provably requires exponentially more data than a cut-aware hierarchical learner. This provides a principled justification for subgoal decomposition in recent agentic theorem provers.
Why High-rank Neural Networks Generalize?: An Algebraic Framework with RKHSs
Sep 26, 2025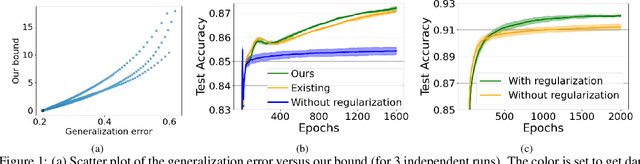
We derive a new Rademacher complexity bound for deep neural networks using Koopman operators, group representations, and reproducing kernel Hilbert spaces (RKHSs). The proposed bound describes why the models with high-rank weight matrices generalize well. Although there are existing bounds that attempt to describe this phenomenon, these existing bounds can be applied to limited types of models. We introduce an algebraic representation of neural networks and a kernel function to construct an RKHS to derive a bound for a wider range of realistic models. This work paves the way for the Koopman-based theory for Rademacher complexity bounds to be valid for more practical situations.
Generalization Through Growth: Hidden Dynamics Controls Depth Dependence
May 21, 2025Recent theory has reduced the depth dependence of generalization bounds from exponential to polynomial and even depth-independent rates, yet these results remain tied to specific architectures and Euclidean inputs. We present a unified framework for arbitrary \blue{pseudo-metric} spaces in which a depth-\(k\) network is the composition of continuous hidden maps \(f:\mathcal{X}\to \mathcal{X}\) and an output map \(h:\mathcal{X}\to \mathbb{R}\). The resulting bound $O(\sqrt{(\alpha + \log \beta(k))/n})$ isolates the sole depth contribution in \(\beta(k)\), the word-ball growth of the semigroup generated by the hidden layers. By Gromov's theorem polynomial (resp. exponential) growth corresponds to virtually nilpotent (resp. expanding) dynamics, revealing a geometric dichotomy behind existing $O(\sqrt{k})$ (sublinear depth) and $\tilde{O}(1)$ (depth-independent) rates. We further provide covering-number estimates showing that expanding dynamics yield an exponential parameter saving via compositional expressivity. Our results decouple specification from implementation, offering architecture-agnostic and dynamical-systems-aware guarantees applicable to modern deep-learning paradigms such as test-time inference and diffusion models.
Lean Formalization of Generalization Error Bound by Rademacher Complexity
Mar 25, 2025

We formalize the generalization error bound using Rademacher complexity in the Lean 4 theorem prover. Generalization error quantifies the gap between a learning machine's performance on given training data versus unseen test data, and Rademacher complexity serves as an estimate of this error based on the complexity of learning machines, or hypothesis class. Unlike traditional methods such as PAC learning and VC dimension, Rademacher complexity is applicable across diverse machine learning scenarios including deep learning and kernel methods. We formalize key concepts and theorems, including the empirical and population Rademacher complexities, and establish generalization error bounds through formal proofs of McDiarmid's inequality, Hoeffding's lemma, and symmetrization arguments.
Constructive Universal Approximation Theorems for Deep Joint-Equivariant Networks by Schur's Lemma
May 22, 2024

We present a unified constructive universal approximation theorem covering a wide range of learning machines including both shallow and deep neural networks based on the group representation theory. Constructive here means that the distribution of parameters is given in a closed-form expression (called the ridgelet transform). Contrary to the case of shallow models, expressive power analysis of deep models has been conducted in a case-by-case manner. Recently, Sonoda et al. (2023a,b) developed a systematic method to show a constructive approximation theorem from scalar-valued joint-group-invariant feature maps, covering a formal deep network. However, each hidden layer was formalized as an abstract group action, so it was not possible to cover real deep networks defined by composites of nonlinear activation function. In this study, we extend the method for vector-valued joint-group-equivariant feature maps, so to cover such real networks.
A unified Fourier slice method to derive ridgelet transform for a variety of depth-2 neural networks
Feb 25, 2024To investigate neural network parameters, it is easier to study the distribution of parameters than to study the parameters in each neuron. The ridgelet transform is a pseudo-inverse operator that maps a given function $f$ to the parameter distribution $\gamma$ so that a network $\mathtt{NN}[\gamma]$ reproduces $f$, i.e. $\mathtt{NN}[\gamma]=f$. For depth-2 fully-connected networks on a Euclidean space, the ridgelet transform has been discovered up to the closed-form expression, thus we could describe how the parameters are distributed. However, for a variety of modern neural network architectures, the closed-form expression has not been known. In this paper, we explain a systematic method using Fourier expressions to derive ridgelet transforms for a variety of modern networks such as networks on finite fields $\mathbb{F}_p$, group convolutional networks on abstract Hilbert space $\mathcal{H}$, fully-connected networks on noncompact symmetric spaces $G/K$, and pooling layers, or the $d$-plane ridgelet transform.
A Policy Gradient Primal-Dual Algorithm for Constrained MDPs with Uniform PAC Guarantees
Feb 02, 2024

We study a primal-dual reinforcement learning (RL) algorithm for the online constrained Markov decision processes (CMDP) problem, wherein the agent explores an optimal policy that maximizes return while satisfying constraints. Despite its widespread practical use, the existing theoretical literature on primal-dual RL algorithms for this problem only provides sublinear regret guarantees and fails to ensure convergence to optimal policies. In this paper, we introduce a novel policy gradient primal-dual algorithm with uniform probably approximate correctness (Uniform-PAC) guarantees, simultaneously ensuring convergence to optimal policies, sublinear regret, and polynomial sample complexity for any target accuracy. Notably, this represents the first Uniform-PAC algorithm for the online CMDP problem. In addition to the theoretical guarantees, we empirically demonstrate in a simple CMDP that our algorithm converges to optimal policies, while an existing algorithm exhibits oscillatory performance and constraint violation.