 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCautious Policy Programming: Exploiting KL Regularization in Monotonic Policy Improvement for Reinforcement Learning
Paper and Code
Jul 13, 2021
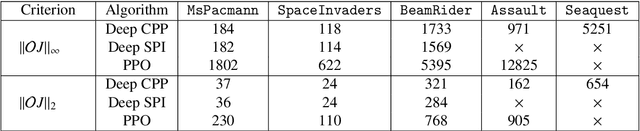


In this paper, we propose cautious policy programming (CPP), a novel value-based reinforcement learning (RL) algorithm that can ensure monotonic policy improvement during learning. Based on the nature of entropy-regularized RL, we derive a new entropy regularization-aware lower bound of policy improvement that only requires estimating the expected policy advantage function. CPP leverages this lower bound as a criterion for adjusting the degree of a policy update for alleviating policy oscillation. Different from similar algorithms that are mostly theory-oriented, we also propose a novel interpolation scheme that makes CPP better scale in high dimensional control problems. We demonstrate that the proposed algorithm can trade o? performance and stability in both didactic classic control problems and challenging high-dimensional Atari games.