 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStraggler-Resilient Decentralized Learning via Adaptive Asynchronous Updates
Paper and Code
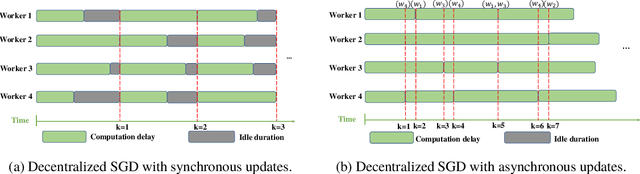
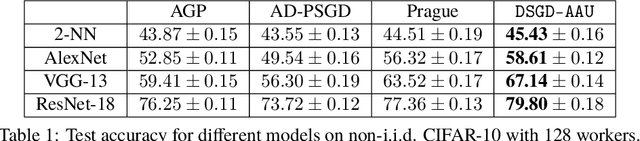
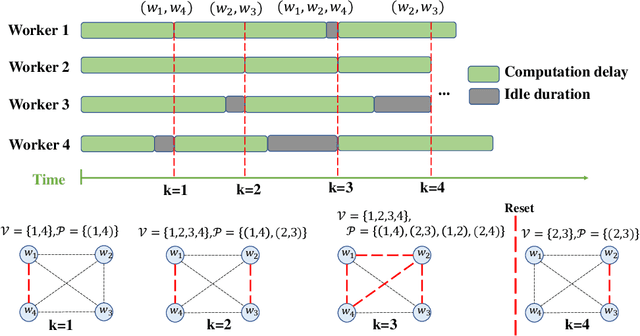

With the increasing demand for large-scale training of machine learning models, fully decentralized optimization methods have recently been advocated as alternatives to the popular parameter server framework. In this paradigm, each worker maintains a local estimate of the optimal parameter vector, and iteratively updates it by waiting and averaging all estimates obtained from its neighbors, and then corrects it on the basis of its local dataset. However, the synchronization phase is sensitive to stragglers. An efficient way to mitigate this effect is to consider asynchronous updates, where each worker computes stochastic gradients and communicates with other workers at its own pace. Unfortunately, fully asynchronous updates suffer from staleness of the stragglers' parameters. To address these limitations, we propose a fully decentralized algorithm DSGD-AAU with adaptive asynchronous updates via adaptively determining the number of neighbor workers for each worker to communicate with. We show that DSGD-AAU achieves a linear speedup for convergence (i.e., convergence performance increases linearly with respect to the number of workers). Experimental results on a suite of datasets and deep neural network models are provided to verify our theoretical results.