 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Prebuilt Recurrent Reconstruction Network for Video Super-Resolution
Paper and Code
Dec 10, 2021

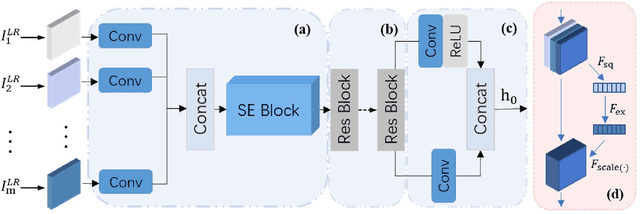
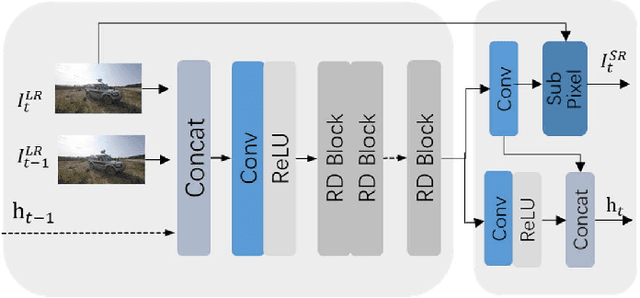
The video super-resolution (VSR) method based on the recurrent convolutional network has strong temporal modeling capability for video sequences. However, the input information received by different recurrent units in the unidirectional recurrent convolutional network is unbalanced. Early reconstruction frames receive less temporal information, resulting in fuzzy or artifact results. Although the bidirectional recurrent convolution network can alleviate this problem, it greatly increases reconstruction time and computational complexity. It is also not suitable for many application scenarios, such as online super-resolution. To solve the above problems, we propose an end-to-end information prebuilt recurrent reconstruction network (IPRRN), consisting of an information prebuilt network (IPNet) and a recurrent reconstruction network (RRNet). By integrating sufficient information from the front of the video to build the hidden state needed for the initially recurrent unit to help restore the earlier frames, the information prebuilt network balances the input information difference before and after without backward propagation. In addition, we demonstrate a compact recurrent reconstruction network, which has significant improvements in recovery quality and time efficiency. Many experiments have verified the effectiveness of our proposed network, and compared with the existing state-of-the-art methods, our method can effectively achieve higher quantitative and qualitative evaluation performance.