 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-WLAuslan: Multi-View Multi-Modal Word-Level Australian Sign Language Recognition Dataset
Oct 25, 2024



Isolated Sign Language Recognition (ISLR) focuses on identifying individual sign language glosses. Considering the diversity of sign languages across geographical regions, developing region-specific ISLR datasets is crucial for supporting communication and research. Auslan, as a sign language specific to Australia, still lacks a dedicated large-scale word-level dataset for the ISLR task. To fill this gap, we curate \underline{\textbf{the first}} large-scale Multi-view Multi-modal Word-Level Australian Sign Language recognition dataset, dubbed MM-WLAuslan. Compared to other publicly available datasets, MM-WLAuslan exhibits three significant advantages: (1) the largest amount of data, (2) the most extensive vocabulary, and (3) the most diverse of multi-modal camera views. Specifically, we record 282K+ sign videos covering 3,215 commonly used Auslan glosses presented by 73 signers in a studio environment. Moreover, our filming system includes two different types of cameras, i.e., three Kinect-V2 cameras and a RealSense camera. We position cameras hemispherically around the front half of the model and simultaneously record videos using all four cameras. Furthermore, we benchmark results with state-of-the-art methods for various multi-modal ISLR settings on MM-WLAuslan, including multi-view, cross-camera, and cross-view. Experiment results indicate that MM-WLAuslan is a challenging ISLR dataset, and we hope this dataset will contribute to the development of Auslan and the advancement of sign languages worldwide. All datasets and benchmarks are available at MM-WLAuslan.
3DRealCar: An In-the-wild RGB-D Car Dataset with 360-degree Views
Jun 07, 2024

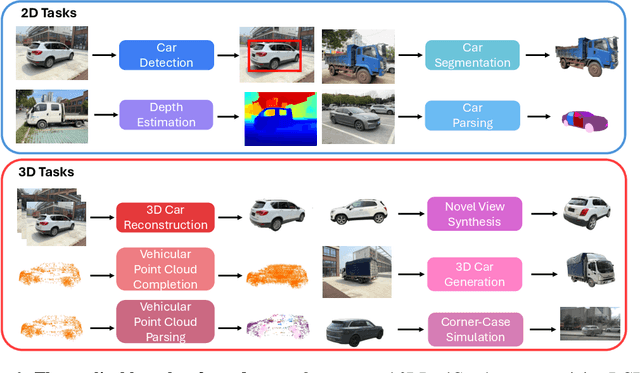
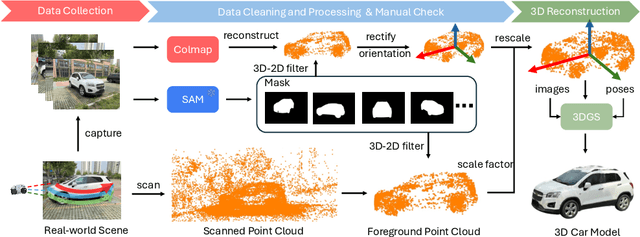
3D cars are commonly used in self-driving systems, virtual/augmented reality, and games. However, existing 3D car datasets are either synthetic or low-quality, presenting a significant gap toward the high-quality real-world 3D car datasets and limiting their applications in practical scenarios. In this paper, we propose the first large-scale 3D real car dataset, termed 3DRealCar, offering three distinctive features. (1) \textbf{High-Volume}: 2,500 cars are meticulously scanned by 3D scanners, obtaining car images and point clouds with real-world dimensions; (2) \textbf{High-Quality}: Each car is captured in an average of 200 dense, high-resolution 360-degree RGB-D views, enabling high-fidelity 3D reconstruction; (3) \textbf{High-Diversity}: The dataset contains various cars from over 100 brands, collected under three distinct lighting conditions, including reflective, standard, and dark. Additionally, we offer detailed car parsing maps for each instance to promote research in car parsing tasks. Moreover, we remove background point clouds and standardize the car orientation to a unified axis for the reconstruction only on cars without background and controllable rendering. We benchmark 3D reconstruction results with state-of-the-art methods across each lighting condition in 3DRealCar. Extensive experiments demonstrate that the standard lighting condition part of 3DRealCar can be used to produce a large number of high-quality 3D cars, improving various 2D and 3D tasks related to cars. Notably, our dataset brings insight into the fact that recent 3D reconstruction methods face challenges in reconstructing high-quality 3D cars under reflective and dark lighting conditions. \textcolor{red}{\href{https://xiaobiaodu.github.io/3drealcar/}{Our dataset is available here.}}
Divide and Ensemble: Progressively Learning for the Unknown
Oct 09, 2023
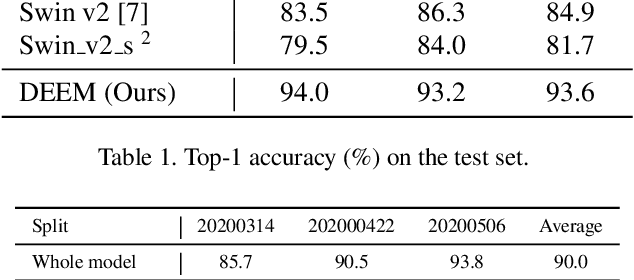


In the wheat nutrient deficiencies classification challenge, we present the DividE and EnseMble (DEEM) method for progressive test data predictions. We find that (1) test images are provided in the challenge; (2) samples are equipped with their collection dates; (3) the samples of different dates show notable discrepancies. Based on the findings, we partition the dataset into discrete groups by the dates and train models on each divided group. We then adopt the pseudo-labeling approach to label the test data and incorporate those with high confidence into the training set. In pseudo-labeling, we leverage models ensemble with different architectures to enhance the reliability of predictions. The pseudo-labeling and ensembled model training are iteratively conducted until all test samples are labeled. Finally, the separated models for each group are unified to obtain the model for the whole dataset. Our method achieves an average of 93.6\% Top-1 test accuracy~(94.0\% on WW2020 and 93.2\% on WR2021) and wins the 1$st$ place in the Deep Nutrient Deficiency Challenge~\footnote{https://cvppa2023.github.io/challenges/}.
RVD: A Handheld Device-Based Fundus Video Dataset for Retinal Vessel Segmentation
Jul 13, 2023Retinal vessel segmentation is generally grounded in image-based datasets collected with bench-top devices. The static images naturally lose the dynamic characteristics of retina fluctuation, resulting in diminished dataset richness, and the usage of bench-top devices further restricts dataset scalability due to its limited accessibility. Considering these limitations, we introduce the first video-based retinal dataset by employing handheld devices for data acquisition. The dataset comprises 635 smartphone-based fundus videos collected from four different clinics, involving 415 patients from 50 to 75 years old. It delivers comprehensive and precise annotations of retinal structures in both spatial and temporal dimensions, aiming to advance the landscape of vasculature segmentation. Specifically, the dataset provides three levels of spatial annotations: binary vessel masks for overall retinal structure delineation, general vein-artery masks for distinguishing the vein and artery, and fine-grained vein-artery masks for further characterizing the granularities of each artery and vein. In addition, the dataset offers temporal annotations that capture the vessel pulsation characteristics, assisting in detecting ocular diseases that require fine-grained recognition of hemodynamic fluctuation. In application, our dataset exhibits a significant domain shift with respect to data captured by bench-top devices, thus posing great challenges to existing methods. In the experiments, we provide evaluation metrics and benchmark results on our dataset, reflecting both the potential and challenges it offers for vessel segmentation tasks. We hope this challenging dataset would significantly contribute to the development of eye disease diagnosis and early prevention.
Autonomous Stabilization of Retinal Videos for Streamlining Assessment of Spontaneous Venous Pulsations
May 10, 2023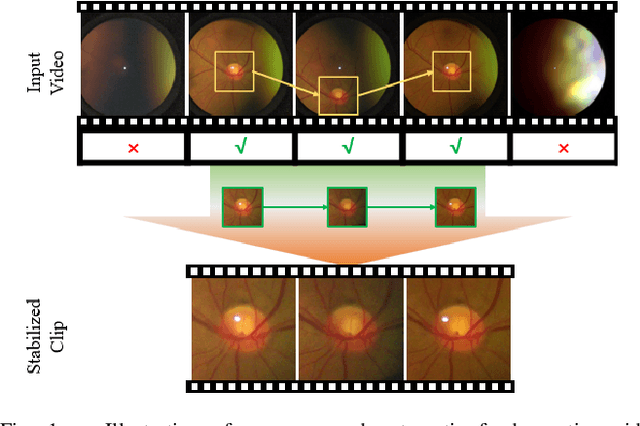

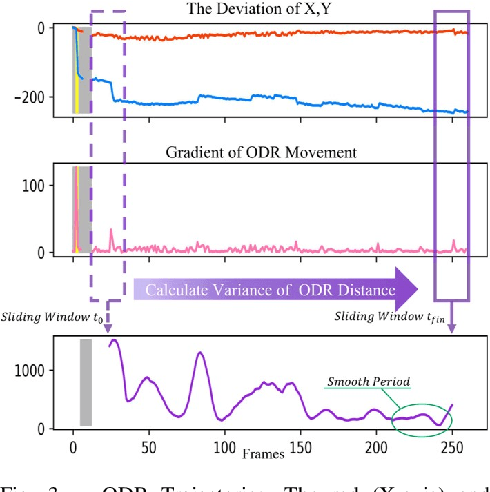
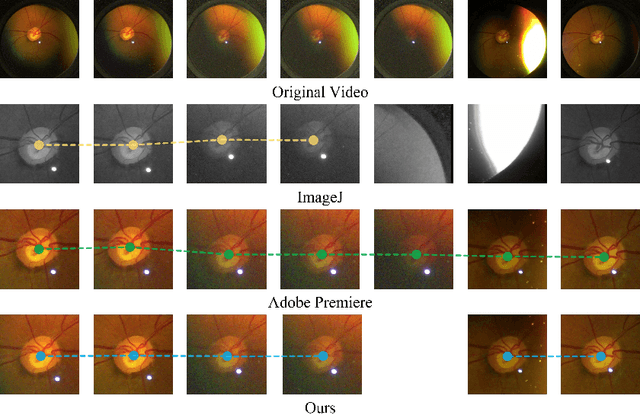
Spontaneous retinal Venous Pulsations (SVP) are rhythmic changes in the caliber of the central retinal vein and are observed in the optic disc region (ODR) of the retina. Its absence is a critical indicator of various ocular or neurological abnormalities. Recent advances in imaging technology have enabled the development of portable smartphone-based devices for observing the retina and assessment of SVPs. However, the quality of smartphone-based retinal videos is often poor due to noise and image jitting, which in return, can severely obstruct the observation of SVPs. In this work, we developed a fully automated retinal video stabilization method that enables the examination of SVPs captured by various mobile devices. Specifically, we first propose an ODR Spatio-Temporal Localization (ODR-STL) module to localize visible ODR and remove noisy and jittering frames. Then, we introduce a Noise-Aware Template Matching (NATM) module to stabilize high-quality video segments at a fixed position in the field of view. After the processing, the SVPs can be easily observed in the stabilized videos, significantly facilitating user observations. Furthermore, our method is cost-effective and has been tested in both subjective and objective evaluations. Both of the evaluations support its effectiveness in facilitating the observation of SVPs. This can improve the timely diagnosis and treatment of associated diseases, making it a valuable tool for eye health professionals.