 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoRefiner: Improving Autoregressive Video Diffusion Models via Reflective Refinement Over the Stochastic Sampling Path
Dec 15, 2025Autoregressive video diffusion models (AR-VDMs) show strong promise as scalable alternatives to bidirectional VDMs, enabling real-time and interactive applications. Yet there remains room for improvement in their sample fidelity. A promising solution is inference-time alignment, which optimizes the noise space to improve sample fidelity without updating model parameters. Yet, optimization- or search-based methods are computationally impractical for AR-VDMs. Recent text-to-image (T2I) works address this via feedforward noise refiners that modulate sampled noises in a single forward pass. Can such noise refiners be extended to AR-VDMs? We identify the failure of naively extending T2I noise refiners to AR-VDMs and propose AutoRefiner-a noise refiner tailored for AR-VDMs, with two key designs: pathwise noise refinement and a reflective KV-cache. Experiments demonstrate that AutoRefiner serves as an efficient plug-in for AR-VDMs, effectively enhancing sample fidelity by refining noise along stochastic denoising paths.
Establishing Reliability Metrics for Reward Models in Large Language Models
Apr 21, 2025The reward model (RM) that represents human preferences plays a crucial role in optimizing the outputs of large language models (LLMs), e.g., through reinforcement learning from human feedback (RLHF) or rejection sampling. However, a long challenge for RM is its uncertain reliability, i.e., LLM outputs with higher rewards may not align with actual human preferences. Currently, there is a lack of a convincing metric to quantify the reliability of RMs. To bridge this gap, we propose the \textit{\underline{R}eliable at \underline{$\eta$}} (RETA) metric, which directly measures the reliability of an RM by evaluating the average quality (scored by an oracle) of the top $\eta$ quantile responses assessed by an RM. On top of RETA, we present an integrated benchmarking pipeline that allows anyone to evaluate their own RM without incurring additional Oracle labeling costs. Extensive experimental studies demonstrate the superior stability of RETA metric, providing solid evaluations of the reliability of various publicly available and proprietary RMs. When dealing with an unreliable RM, we can use the RETA metric to identify the optimal quantile from which to select the responses.
Probability Density Geodesics in Image Diffusion Latent Space
Apr 09, 2025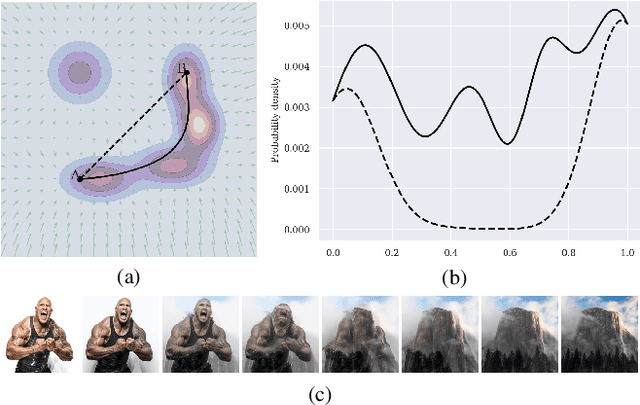
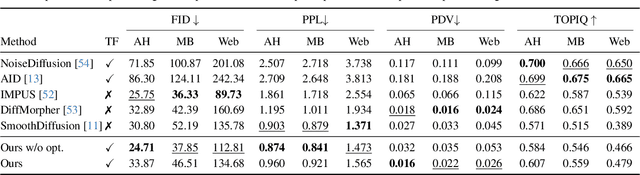
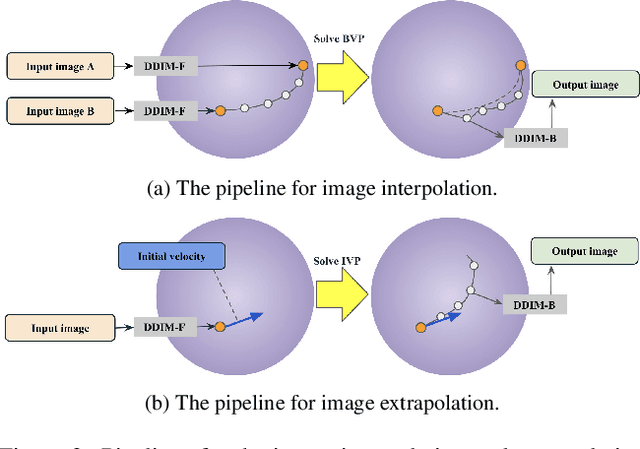
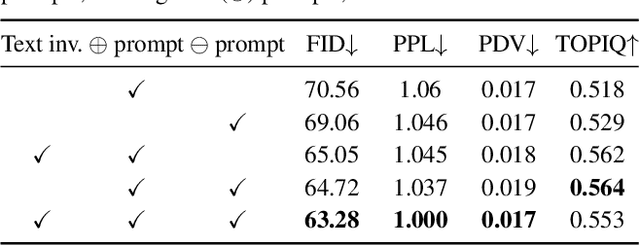
Diffusion models indirectly estimate the probability density over a data space, which can be used to study its structure. In this work, we show that geodesics can be computed in diffusion latent space, where the norm induced by the spatially-varying inner product is inversely proportional to the probability density. In this formulation, a path that traverses a high density (that is, probable) region of image latent space is shorter than the equivalent path through a low density region. We present algorithms for solving the associated initial and boundary value problems and show how to compute the probability density along the path and the geodesic distance between two points. Using these techniques, we analyze how closely video clips approximate geodesics in a pre-trained image diffusion space. Finally, we demonstrate how these techniques can be applied to training-free image sequence interpolation and extrapolation, given a pre-trained image diffusion model.
Divide and Ensemble: Progressively Learning for the Unknown
Oct 09, 2023
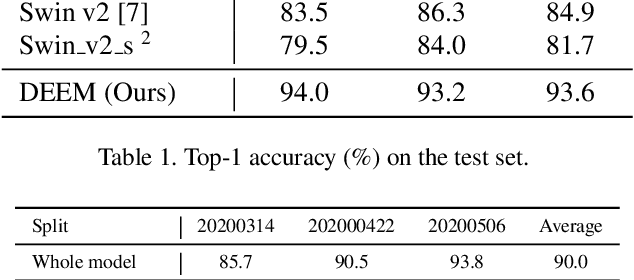


In the wheat nutrient deficiencies classification challenge, we present the DividE and EnseMble (DEEM) method for progressive test data predictions. We find that (1) test images are provided in the challenge; (2) samples are equipped with their collection dates; (3) the samples of different dates show notable discrepancies. Based on the findings, we partition the dataset into discrete groups by the dates and train models on each divided group. We then adopt the pseudo-labeling approach to label the test data and incorporate those with high confidence into the training set. In pseudo-labeling, we leverage models ensemble with different architectures to enhance the reliability of predictions. The pseudo-labeling and ensembled model training are iteratively conducted until all test samples are labeled. Finally, the separated models for each group are unified to obtain the model for the whole dataset. Our method achieves an average of 93.6\% Top-1 test accuracy~(94.0\% on WW2020 and 93.2\% on WR2021) and wins the 1$st$ place in the Deep Nutrient Deficiency Challenge~\footnote{https://cvppa2023.github.io/challenges/}.
Recurrent Temporal Revision Graph Networks
Sep 26, 2023Temporal graphs offer more accurate modeling of many real-world scenarios than static graphs. However, neighbor aggregation, a critical building block of graph networks, for temporal graphs, is currently straightforwardly extended from that of static graphs. It can be computationally expensive when involving all historical neighbors during such aggregation. In practice, typically only a subset of the most recent neighbors are involved. However, such subsampling leads to incomplete and biased neighbor information. To address this limitation, we propose a novel framework for temporal neighbor aggregation that uses the recurrent neural network with node-wise hidden states to integrate information from all historical neighbors for each node to acquire the complete neighbor information. We demonstrate the superior theoretical expressiveness of the proposed framework as well as its state-of-the-art performance in real-world applications. Notably, it achieves a significant +9.6% improvement on averaged precision in a real-world Ecommerce dataset over existing methods on 2-layer models.
When 3D Bounding-Box Meets SAM: Point Cloud Instance Segmentation with Weak-and-Noisy Supervision
Sep 02, 2023

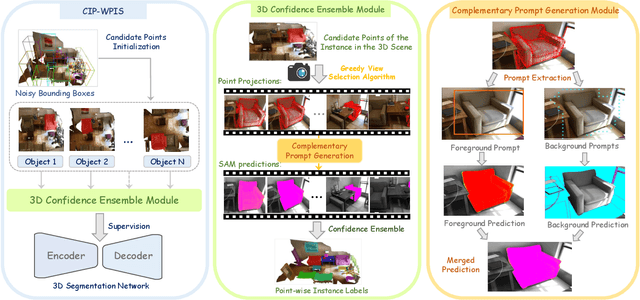

Learning from bounding-boxes annotations has shown great potential in weakly-supervised 3D point cloud instance segmentation. However, we observed that existing methods would suffer severe performance degradation with perturbed bounding box annotations. To tackle this issue, we propose a complementary image prompt-induced weakly-supervised point cloud instance segmentation (CIP-WPIS) method. CIP-WPIS leverages pretrained knowledge embedded in the 2D foundation model SAM and 3D geometric prior to achieve accurate point-wise instance labels from the bounding box annotations. Specifically, CP-WPIS first selects image views in which 3D candidate points of an instance are fully visible. Then, we generate complementary background and foreground prompts from projections to obtain SAM 2D instance mask predictions. According to these, we assign the confidence values to points indicating the likelihood of points belonging to the instance. Furthermore, we utilize 3D geometric homogeneity provided by superpoints to decide the final instance label assignments. In this fashion, we achieve high-quality 3D point-wise instance labels. Extensive experiments on both Scannet-v2 and S3DIS benchmarks demonstrate that our method is robust against noisy 3D bounding-box annotations and achieves state-of-the-art performance.
Clustered Embedding Learning for Recommender Systems
Feb 10, 2023In recent years, recommender systems have advanced rapidly, where embedding learning for users and items plays a critical role. A standard method learns a unique embedding vector for each user and item. However, such a method has two important limitations in real-world applications: 1) it is hard to learn embeddings that generalize well for users and items with rare interactions on their own; and 2) it may incur unbearably high memory costs when the number of users and items scales up. Existing approaches either can only address one of the limitations or have flawed overall performances. In this paper, we propose Clustered Embedding Learning (CEL) as an integrated solution to these two problems. CEL is a plug-and-play embedding learning framework that can be combined with any differentiable feature interaction model. It is capable of achieving improved performance, especially for cold users and items, with reduced memory cost. CEL enables automatic and dynamic clustering of users and items in a top-down fashion, where clustered entities jointly learn a shared embedding. The accelerated version of CEL has an optimal time complexity, which supports efficient online updates. Theoretically, we prove the identifiability and the existence of a unique optimal number of clusters for CEL in the context of nonnegative matrix factorization. Empirically, we validate the effectiveness of CEL on three public datasets and one business dataset, showing its consistently superior performance against current state-of-the-art methods. In particular, when incorporating CEL into the business model, it brings an improvement of $+0.6\%$ in AUC, which translates into a significant revenue gain; meanwhile, the size of the embedding table gets $2650$ times smaller.