 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCoVR: Closing the Loop in Interactive Composed Video Retrieval
May 11, 2026Composed video retrieval (CoVR) searches for target videos using a reference video and a modification text, but existing methods are restricted to a single interaction round and cannot support the progressive nature of real-world visual search. To bridge this gap, we first formalize interactive composed video retrieval, a multi-turn extension of CoVR, where users progressively refine their search intent through natural-language feedback across turns. Adapting existing interactive retrieval methods to this setting reveals two structural weaknesses: reliance on a single retrieval channel and an open-loop retrieval design that consumes user feedback but does not diagnose whether its own retrieval trajectory is drifting or stagnating. To address these limitations, we propose ReCoVR (Reflexive Composed Video Retrieval), a dual-pathway architecture built on reflexive perception, where the system treats its retrieval history as diagnostic evidence alongside user feedback. Specifically, an Intent Pathway routes heterogeneous feedback to complementary retrieval channels, while a Reflection Pathway performs trajectory-level reflection to monitor result evolution and correct retrieval errors across turns. Experiments on multiple benchmarks show that ReCoVR consistently outperforms interactive baselines, notably achieving 74.30% R@1 after just one interactive round on the WebVid-CoVR-Test dataset.
FlashVTG: Feature Layering and Adaptive Score Handling Network for Video Temporal Grounding
Dec 18, 2024
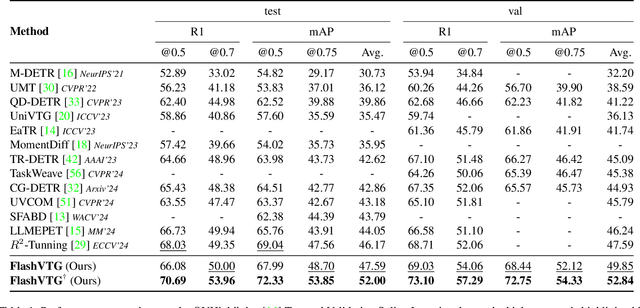

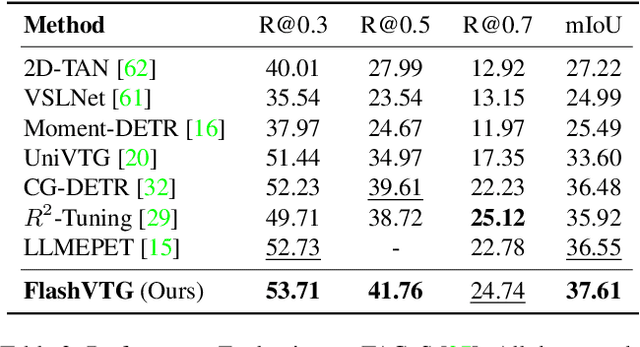
Text-guided Video Temporal Grounding (VTG) aims to localize relevant segments in untrimmed videos based on textual descriptions, encompassing two subtasks: Moment Retrieval (MR) and Highlight Detection (HD). Although previous typical methods have achieved commendable results, it is still challenging to retrieve short video moments. This is primarily due to the reliance on sparse and limited decoder queries, which significantly constrain the accuracy of predictions. Furthermore, suboptimal outcomes often arise because previous methods rank predictions based on isolated predictions, neglecting the broader video context. To tackle these issues, we introduce FlashVTG, a framework featuring a Temporal Feature Layering (TFL) module and an Adaptive Score Refinement (ASR) module. The TFL module replaces the traditional decoder structure to capture nuanced video content variations across multiple temporal scales, while the ASR module improves prediction ranking by integrating context from adjacent moments and multi-temporal-scale features. Extensive experiments demonstrate that FlashVTG achieves state-of-the-art performance on four widely adopted datasets in both MR and HD. Specifically, on the QVHighlights dataset, it boosts mAP by 5.8% for MR and 3.3% for HD. For short-moment retrieval, FlashVTG increases mAP to 125% of previous SOTA performance. All these improvements are made without adding training burdens, underscoring its effectiveness. Our code is available at https://github.com/Zhuo-Cao/FlashVTG.
TokenBinder: Text-Video Retrieval with One-to-Many Alignment Paradigm
Sep 30, 2024



Text-Video Retrieval (TVR) methods typically match query-candidate pairs by aligning text and video features in coarse-grained, fine-grained, or combined (coarse-to-fine) manners. However, these frameworks predominantly employ a one(query)-to-one(candidate) alignment paradigm, which struggles to discern nuanced differences among candidates, leading to frequent mismatches. Inspired by Comparative Judgement in human cognitive science, where decisions are made by directly comparing items rather than evaluating them independently, we propose TokenBinder. This innovative two-stage TVR framework introduces a novel one-to-many coarse-to-fine alignment paradigm, imitating the human cognitive process of identifying specific items within a large collection. Our method employs a Focused-view Fusion Network with a sophisticated cross-attention mechanism, dynamically aligning and comparing features across multiple videos to capture finer nuances and contextual variations. Extensive experiments on six benchmark datasets confirm that TokenBinder substantially outperforms existing state-of-the-art methods. These results demonstrate its robustness and the effectiveness of its fine-grained alignment in bridging intra- and inter-modality information gaps in TVR tasks.
Object Detection Difficulty: Suppressing Over-aggregation for Faster and Better Video Object Detection
Aug 22, 2023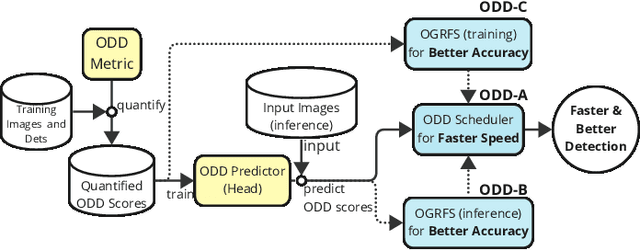
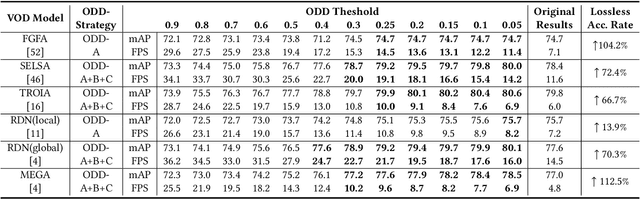

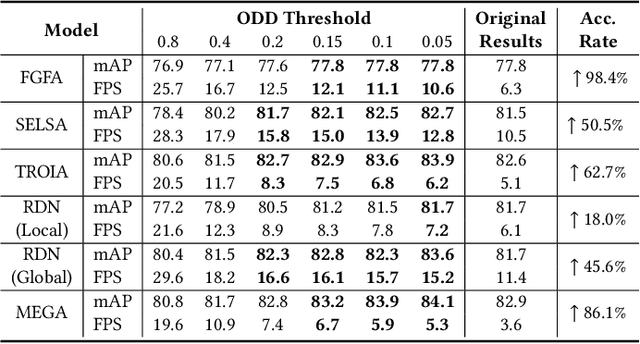
Current video object detection (VOD) models often encounter issues with over-aggregation due to redundant aggregation strategies, which perform feature aggregation on every frame. This results in suboptimal performance and increased computational complexity. In this work, we propose an image-level Object Detection Difficulty (ODD) metric to quantify the difficulty of detecting objects in a given image. The derived ODD scores can be used in the VOD process to mitigate over-aggregation. Specifically, we train an ODD predictor as an auxiliary head of a still-image object detector to compute the ODD score for each image based on the discrepancies between detection results and ground-truth bounding boxes. The ODD score enhances the VOD system in two ways: 1) it enables the VOD system to select superior global reference frames, thereby improving overall accuracy; and 2) it serves as an indicator in the newly designed ODD Scheduler to eliminate the aggregation of frames that are easy to detect, thus accelerating the VOD process. Comprehensive experiments demonstrate that, when utilized for selecting global reference frames, ODD-VOD consistently enhances the accuracy of Global-frame-based VOD models. When employed for acceleration, ODD-VOD consistently improves the frames per second (FPS) by an average of 73.3% across 8 different VOD models without sacrificing accuracy. When combined, ODD-VOD attains state-of-the-art performance when competing with many VOD methods in both accuracy and speed. Our work represents a significant advancement towards making VOD more practical for real-world applications.
STAR-GNN: Spatial-Temporal Video Representation for Content-based Retrieval
Aug 15, 2022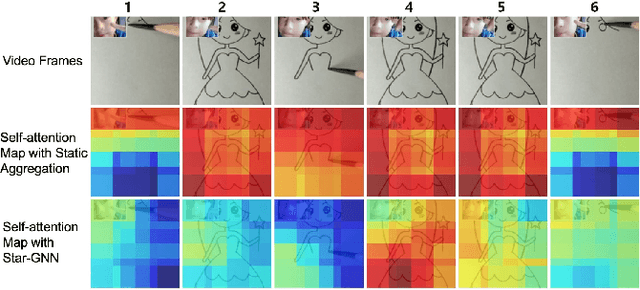
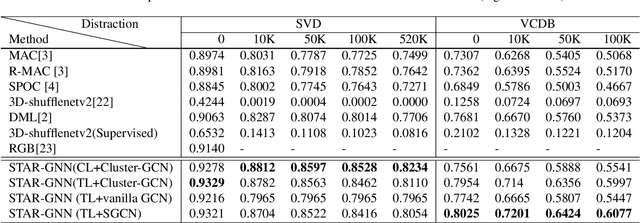
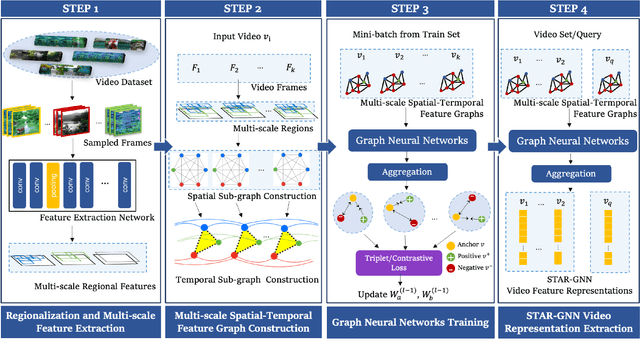
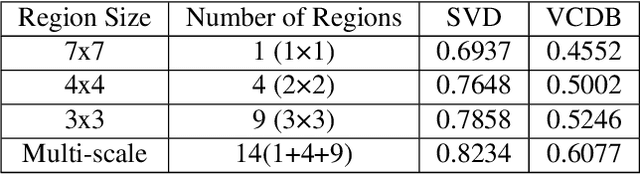
We propose a video feature representation learning framework called STAR-GNN, which applies a pluggable graph neural network component on a multi-scale lattice feature graph. The essence of STAR-GNN is to exploit both the temporal dynamics and spatial contents as well as visual connections between regions at different scales in the frames. It models a video with a lattice feature graph in which the nodes represent regions of different granularity, with weighted edges that represent the spatial and temporal links. The contextual nodes are aggregated simultaneously by graph neural networks with parameters trained with retrieval triplet loss. In the experiments, we show that STAR-GNN effectively implements a dynamic attention mechanism on video frame sequences, resulting in the emphasis for dynamic and semantically rich content in the video, and is robust to noise and redundancies. Empirical results show that STAR-GNN achieves state-of-the-art performance for Content-Based Video Retrieval.
InvisibiliTee: Angle-agnostic Cloaking from Person-Tracking Systems with a Tee
Aug 15, 2022
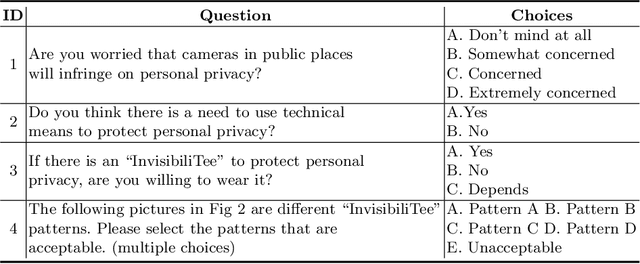


After a survey for person-tracking system-induced privacy concerns, we propose a black-box adversarial attack method on state-of-the-art human detection models called InvisibiliTee. The method learns printable adversarial patterns for T-shirts that cloak wearers in the physical world in front of person-tracking systems. We design an angle-agnostic learning scheme which utilizes segmentation of the fashion dataset and a geometric warping process so the adversarial patterns generated are effective in fooling person detectors from all camera angles and for unseen black-box detection models. Empirical results in both digital and physical environments show that with the InvisibiliTee on, person-tracking systems' ability to detect the wearer drops significantly.
OpenTraj: Assessing Prediction Complexity in Human Trajectories Datasets
Oct 02, 2020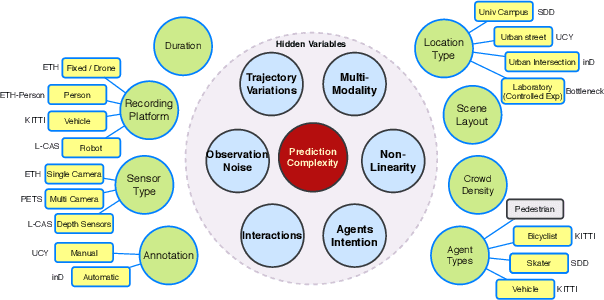
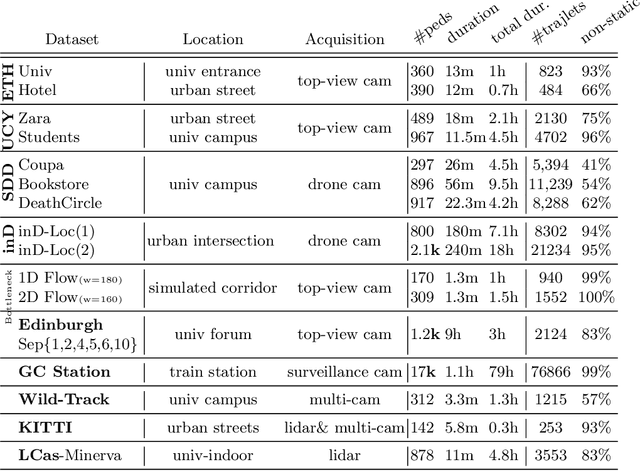

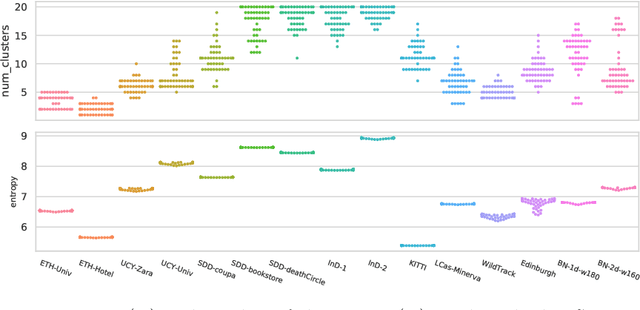
Human Trajectory Prediction (HTP) has gained much momentum in the last years and many solutions have been proposed to solve it. Proper benchmarking being a key issue for comparing methods, this paper addresses the question of evaluating how complex is a given dataset with respect to the prediction problem. For assessing a dataset complexity, we define a series of indicators around three concepts: Trajectory predictability; Trajectory regularity; Context complexity. We compare the most common datasets used in HTP in the light of these indicators and discuss what this may imply on benchmarking of HTP algorithms. Our source code is released on