 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying and Attributing Submodel Uncertainty in Stochastic Simulation Models and Digital Twins
Feb 18, 2026Stochastic simulation is widely used to study complex systems composed of various interconnected subprocesses, such as input processes, routing and control logic, optimization routines, and data-driven decision modules. In practice, these subprocesses may be inherently unknown or too computationally intensive to directly embed in the simulation model. Replacing these elements with estimated or learned approximations introduces a form of epistemic uncertainty that we refer to as submodel uncertainty. This paper investigates how submodel uncertainty affects the estimation of system performance metrics. We develop a framework for quantifying submodel uncertainty in stochastic simulation models and extend the framework to digital-twin settings, where simulation experiments are repeatedly conducted with the model initialized from observed system states. Building on approaches from input uncertainty analysis, we leverage bootstrapping and Bayesian model averaging to construct quantile-based confidence or credible intervals for key performance indicators. We propose a tree-based method that decomposes total output variability and attributes uncertainty to individual submodels in the form of importance scores. The proposed framework is model-agnostic and accommodates both parametric and nonparametric submodels under frequentist and Bayesian modeling paradigms. A synthetic numerical experiment and a more realistic digital-twin simulation of a contact center illustrate the importance of understanding how and how much individual submodels contribute to overall uncertainty.
STAR-GNN: Spatial-Temporal Video Representation for Content-based Retrieval
Aug 15, 2022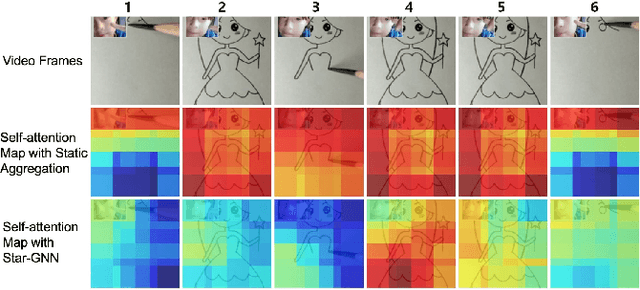
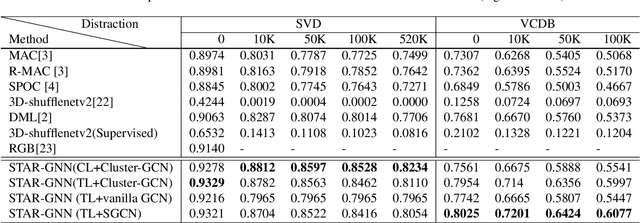
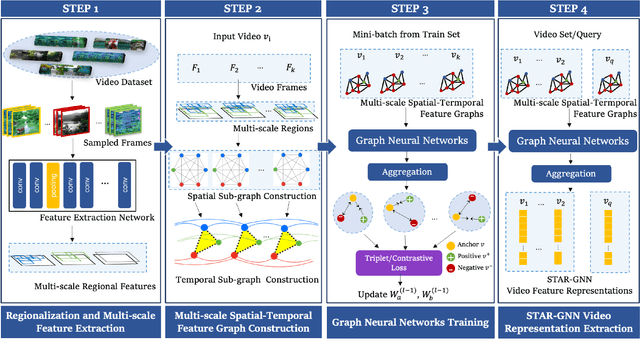
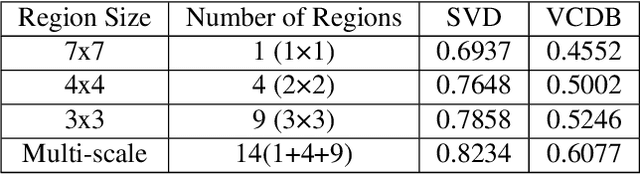
We propose a video feature representation learning framework called STAR-GNN, which applies a pluggable graph neural network component on a multi-scale lattice feature graph. The essence of STAR-GNN is to exploit both the temporal dynamics and spatial contents as well as visual connections between regions at different scales in the frames. It models a video with a lattice feature graph in which the nodes represent regions of different granularity, with weighted edges that represent the spatial and temporal links. The contextual nodes are aggregated simultaneously by graph neural networks with parameters trained with retrieval triplet loss. In the experiments, we show that STAR-GNN effectively implements a dynamic attention mechanism on video frame sequences, resulting in the emphasis for dynamic and semantically rich content in the video, and is robust to noise and redundancies. Empirical results show that STAR-GNN achieves state-of-the-art performance for Content-Based Video Retrieval.
InvisibiliTee: Angle-agnostic Cloaking from Person-Tracking Systems with a Tee
Aug 15, 2022
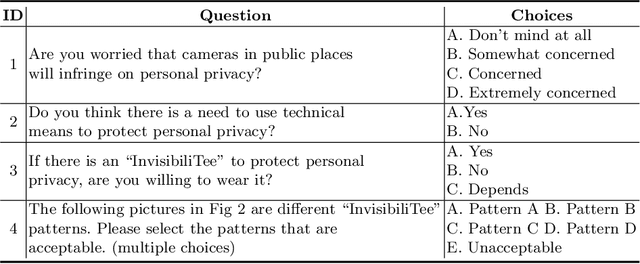


After a survey for person-tracking system-induced privacy concerns, we propose a black-box adversarial attack method on state-of-the-art human detection models called InvisibiliTee. The method learns printable adversarial patterns for T-shirts that cloak wearers in the physical world in front of person-tracking systems. We design an angle-agnostic learning scheme which utilizes segmentation of the fashion dataset and a geometric warping process so the adversarial patterns generated are effective in fooling person detectors from all camera angles and for unseen black-box detection models. Empirical results in both digital and physical environments show that with the InvisibiliTee on, person-tracking systems' ability to detect the wearer drops significantly.
Emotion-Based End-to-End Matching Between Image and Music in Valence-Arousal Space
Aug 22, 2020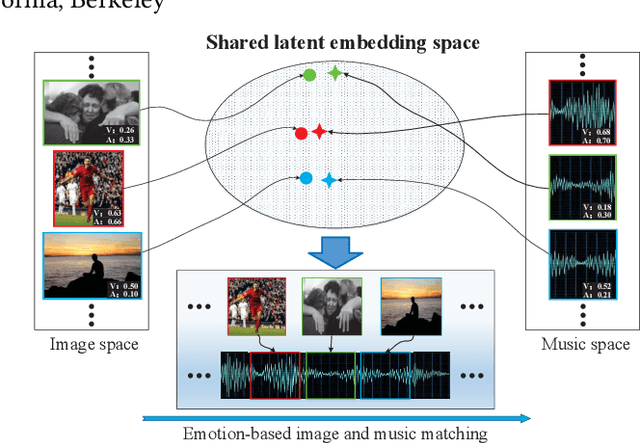
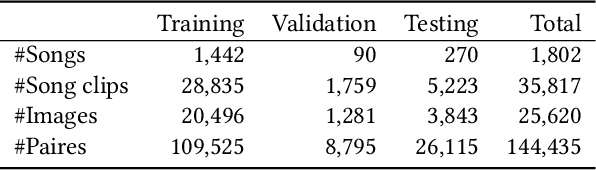
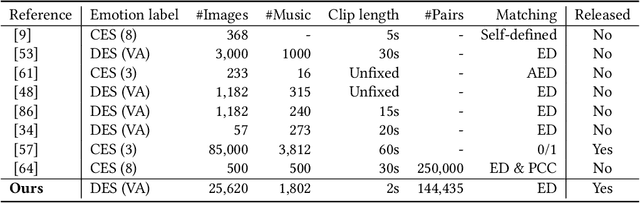
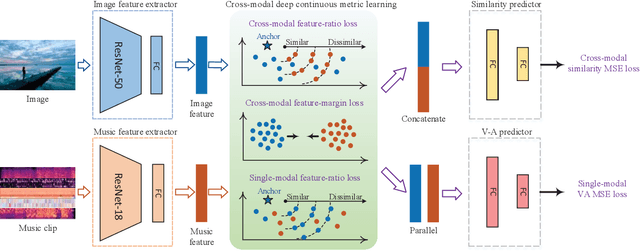
Both images and music can convey rich semantics and are widely used to induce specific emotions. Matching images and music with similar emotions might help to make emotion perceptions more vivid and stronger. Existing emotion-based image and music matching methods either employ limited categorical emotion states which cannot well reflect the complexity and subtlety of emotions, or train the matching model using an impractical multi-stage pipeline. In this paper, we study end-to-end matching between image and music based on emotions in the continuous valence-arousal (VA) space. First, we construct a large-scale dataset, termed Image-Music-Emotion-Matching-Net (IMEMNet), with over 140K image-music pairs. Second, we propose cross-modal deep continuous metric learning (CDCML) to learn a shared latent embedding space which preserves the cross-modal similarity relationship in the continuous matching space. Finally, we refine the embedding space by further preserving the single-modal emotion relationship in the VA spaces of both images and music. The metric learning in the embedding space and task regression in the label space are jointly optimized for both cross-modal matching and single-modal VA prediction. The extensive experiments conducted on IMEMNet demonstrate the superiority of CDCML for emotion-based image and music matching as compared to the state-of-the-art approaches.
Multi-source Distilling Domain Adaptation
Nov 22, 2019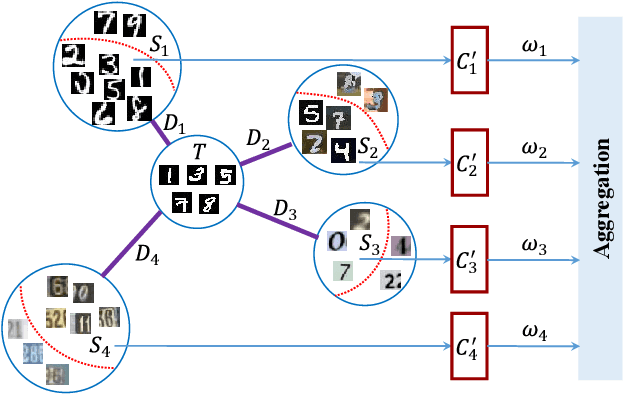
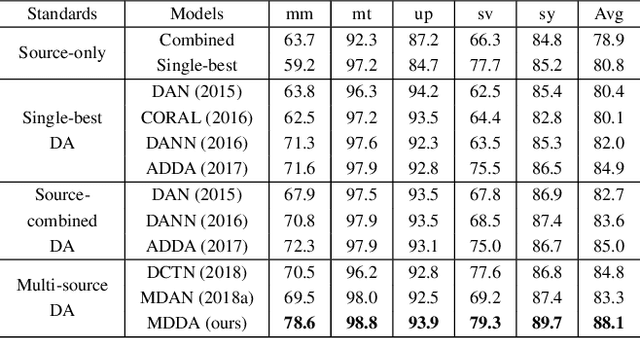
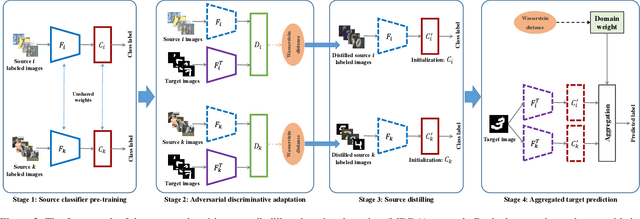
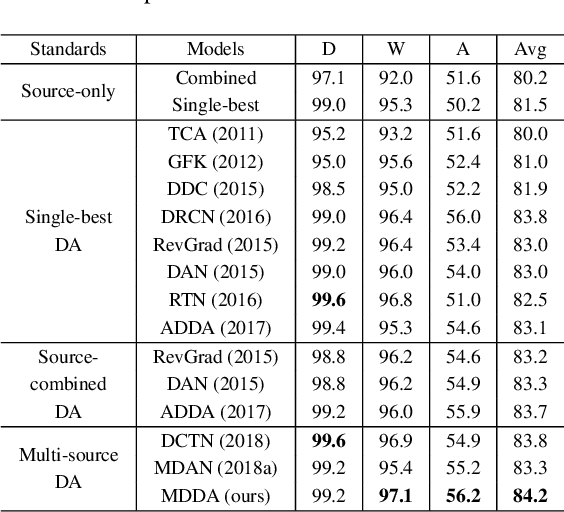
Deep neural networks suffer from performance decay when there is domain shift between the labeled source domain and unlabeled target domain, which motivates the research on domain adaptation (DA). Conventional DA methods usually assume that the labeled data is sampled from a single source distribution. However, in practice, labeled data may be collected from multiple sources, while naive application of the single-source DA algorithms may lead to suboptimal solutions. In this paper, we propose a novel multi-source distilling domain adaptation (MDDA) network, which not only considers the different distances among multiple sources and the target, but also investigates the different similarities of the source samples to the target ones. Specifically, the proposed MDDA includes four stages: (1) pre-train the source classifiers separately using the training data from each source; (2) adversarially map the target into the feature space of each source respectively by minimizing the empirical Wasserstein distance between source and target; (3) select the source training samples that are closer to the target to fine-tune the source classifiers; and (4) classify each encoded target feature by corresponding source classifier, and aggregate different predictions using respective domain weight, which corresponds to the discrepancy between each source and target. Extensive experiments are conducted on public DA benchmarks, and the results demonstrate that the proposed MDDA significantly outperforms the state-of-the-art approaches. Our source code is released at: https://github.com/daoyuan98/MDDA.