 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-SFENet: Multi-scale Multi-task Localization and Classification of Bladder Cancer in MRI with Spatial Feature Encoder Network
Feb 22, 2023Background and Objective: Bladder cancer is a common malignant urinary carcinoma, with muscle-invasive and non-muscle-invasive as its two major subtypes. This paper aims to achieve automated bladder cancer invasiveness localization and classification based on MRI. Method: Different from previous efforts that segment bladder wall and tumor, we propose a novel end-to-end multi-scale multi-task spatial feature encoder network (MM-SFENet) for locating and classifying bladder cancer, according to the classification criteria of the spatial relationship between the tumor and bladder wall. First, we built a backbone with residual blocks to distinguish bladder wall and tumor; then, a spatial feature encoder is designed to encode the multi-level features of the backbone to learn the criteria. Results: We substitute Smooth-L1 Loss with IoU Loss for multi-task learning, to improve the accuracy of the classification task. By testing a total of 1287 MRIs collected from 98 patients at the hospital, the mAP and IoU are used as the evaluation metrics. The experimental result could reach 93.34\% and 83.16\% on test set. Conclusions: The experimental result demonstrates the effectiveness of the proposed MM-SFENet on the localization and classification of bladder cancer. It may provide an effective supplementary diagnosis method for bladder cancer staging.
BB-GCN: A Bi-modal Bridged Graph Convolutional Network for Multi-label Chest X-Ray Recognition
Feb 22, 2023



Multi-label chest X-ray (CXR) recognition involves simultaneously diagnosing and identifying multiple labels for different pathologies. Since pathological labels have rich information about their relationship to each other, modeling the co-occurrence dependencies between pathological labels is essential to improve recognition performance. However, previous methods rely on state variable coding and attention mechanisms-oriented to model local label information, and lack learning of global co-occurrence relationships between labels. Furthermore, these methods roughly integrate image features and label embedding, ignoring the alignment and compactness problems in cross-modal vector fusion.To solve these problems, a Bi-modal Bridged Graph Convolutional Network (BB-GCN) model is proposed. This model mainly consists of a backbone module, a pathology Label Co-occurrence relationship Embedding (LCE) module, and a Transformer Bridge Graph (TBG) module. Specifically, the backbone module obtains image visual feature representation. The LCE module utilizes a graph to model the global co-occurrence relationship between multiple labels and employs graph convolutional networks for learning inference. The TBG module bridges the cross-modal vectors more compactly and efficiently through the GroupSum method.We have evaluated the effectiveness of the proposed BB-GCN in two large-scale CXR datasets (ChestX-Ray14 and CheXpert). Our model achieved state-of-the-art performance: the mean AUC scores for the 14 pathologies were 0.835 and 0.813, respectively.The proposed LCE and TBG modules can jointly effectively improve the recognition performance of BB-GCN. Our model also achieves satisfactory results in multi-label chest X-ray recognition and exhibits highly competitive generalization performance.
Semi-Cycled Generative Adversarial Networks for Real-World Face Super-Resolution
May 08, 2022
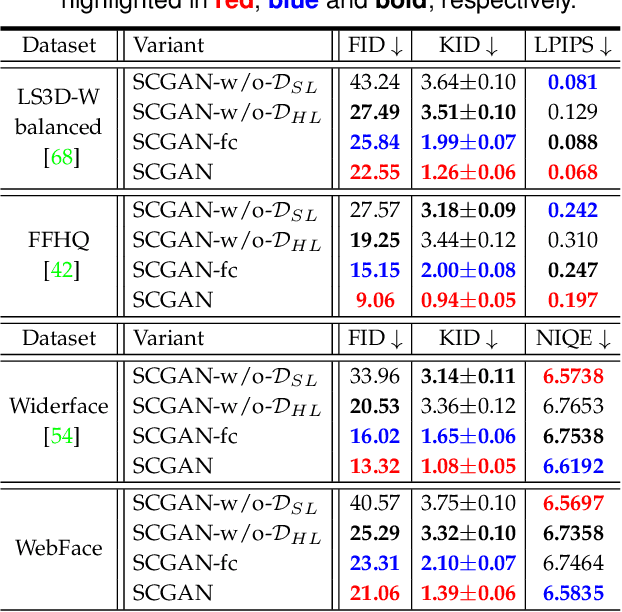

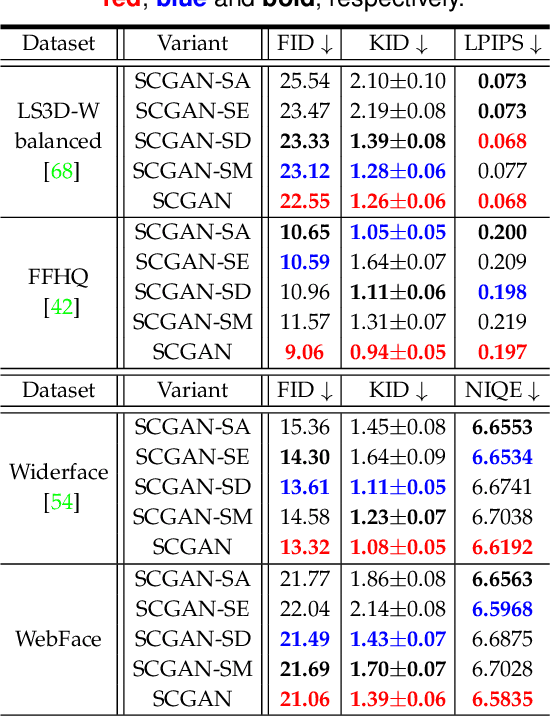
Real-world face super-resolution (SR) is a highly ill-posed image restoration task. The fully-cycled Cycle-GAN architecture is widely employed to achieve promising performance on face SR, but prone to produce artifacts upon challenging cases in real-world scenarios, since joint participation in the same degradation branch will impact final performance due to huge domain gap between real-world and synthetic LR ones obtained by generators. To better exploit the powerful generative capability of GAN for real-world face SR, in this paper, we establish two independent degradation branches in the forward and backward cycle-consistent reconstruction processes, respectively, while the two processes share the same restoration branch. Our Semi-Cycled Generative Adversarial Networks (SCGAN) is able to alleviate the adverse effects of the domain gap between the real-world LR face images and the synthetic LR ones, and to achieve accurate and robust face SR performance by the shared restoration branch regularized by both the forward and backward cycle-consistent learning processes. Experiments on two synthetic and two real-world datasets demonstrate that, our SCGAN outperforms the state-of-the-art methods on recovering the face structures/details and quantitative metrics for real-world face SR. The code will be publicly released at https://github.com/HaoHou-98/SCGAN.
NLHD: A Pixel-Level Non-Local Retinex Model for Low-Light Image Enhancement
Jun 15, 2021


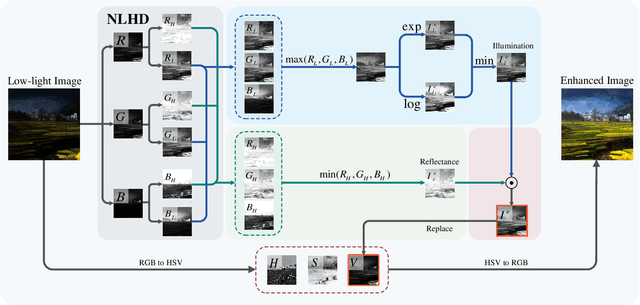
Retinex model has been applied to low-light image enhancement in many existing methods. More appropriate decomposition of a low-light image can help achieve better image enhancement. In this paper, we propose a new pixel-level non-local Haar transform based illumination and reflectance decomposition method (NLHD). The unique low-frequency coefficient of Haar transform on each similar pixel group is used to reconstruct the illumination component, and the rest of all high-frequency coefficients are employed to reconstruct the reflectance component. The complete similarity of pixels in a matched similar pixel group and the simple separable Haar transform help to obtain more appropriate image decomposition; thus, the image is hardly sharpened in the image brightness enhancement procedure. The exponential transform and logarithmic transform are respectively implemented on the illumination component. Then a minimum fusion strategy on the results of these two transforms is utilized to achieve more natural illumination component enhancement. It can alleviate the mosaic artifacts produced in the darker regions by the exponential transform with a gamma value less than 1 and reduce information loss caused by excessive enhancement of the brighter regions due to the logarithmic transform. Finally, the Retinex model is applied to the enhanced illumination and reflectance to achieve image enhancement. We also develop a local noise level estimation based noise suppression method and a non-local saturation reduction based color deviation correction method. These two methods can respectively attenuate noise or color deviation usually presented in the enhanced results of the extremely dark low-light images. Experiments on benchmark datasets show that the proposed method can achieve better low-light image enhancement results on subjective and objective evaluations than most existing methods.
Robust Screening of COVID-19 from Chest X-ray via Discriminative Cost-Sensitive Learning
May 21, 2020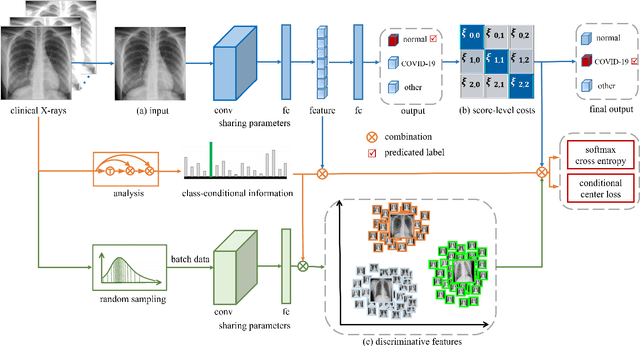
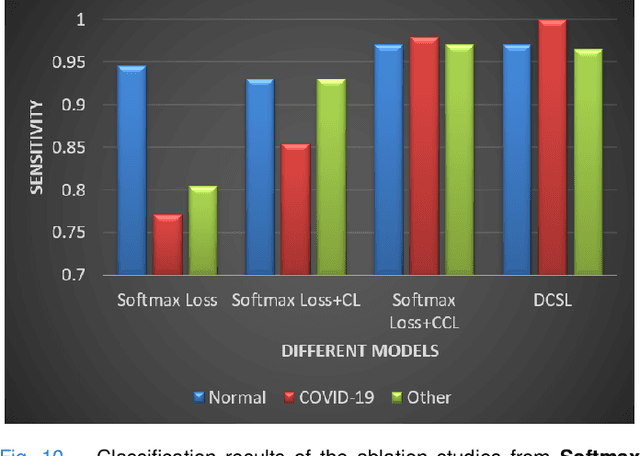
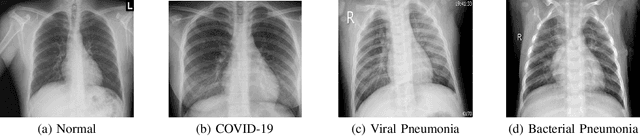
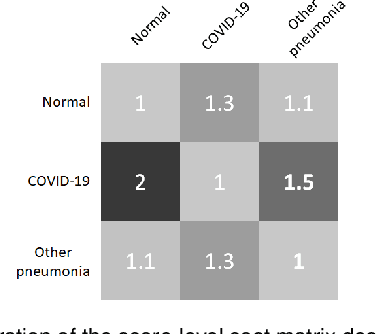
This paper addresses the new problem of automated screening of coronavirus disease 2019 (COVID-19) based on chest X-rays, which is urgently demanded toward fast stopping the pandemic. However, robust and accurate screening of COVID-19 from chest X-rays is still a globally recognized challenge because of two bottlenecks: 1) imaging features of COVID-19 share some similarities with other pneumonia on chest X-rays, and 2) the misdiagnosis rate of COVID-19 is very high, and the misdiagnosis cost is expensive. While a few pioneering works have made much progress, they underestimate both crucial bottlenecks. In this paper, we report our solution, discriminative cost-sensitive learning (DCSL), which should be the choice if the clinical needs the assisted screening of COVID-19 from chest X-rays. DCSL combines both advantages from fine-grained classification and cost-sensitive learning. Firstly, DCSL develops a conditional center loss that learns deep discriminative representation. Secondly, DCSL establishes score-level cost-sensitive learning that can adaptively enlarge the cost of misclassifying COVID-19 examples into other classes. DCSL is so flexible that it can apply in any deep neural network. We collected a large-scale multi-class dataset comprised of 2,239 chest X-ray examples: 239 examples from confirmed COVID-19 cases, 1,000 examples with confirmed bacterial or viral pneumonia cases, and 1,000 examples of healthy people. Extensive experiments on the three-class classification show that our algorithm remarkably outperforms state-of-the-art algorithms. It achieves an accuracy of 97.01%, a precision of 97%, a sensitivity of 97.09%, and an F1-score of 96.98%. These results endow our algorithm as an efficient tool for the fast large-scale screening of COVID-19.
Unifying Neural Learning and Symbolic Reasoning for Spinal Medical Report Generation
Apr 28, 2020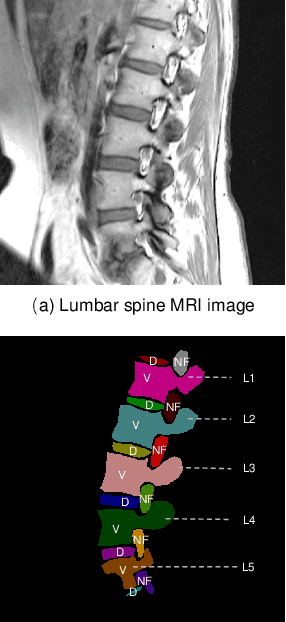
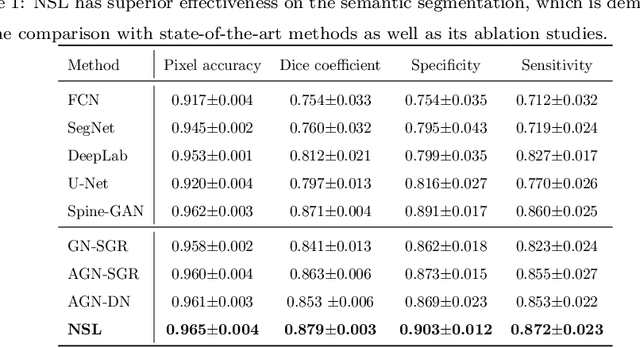


Automated medical report generation in spine radiology, i.e., given spinal medical images and directly create radiologist-level diagnosis reports to support clinical decision making, is a novel yet fundamental study in the domain of artificial intelligence in healthcare. However, it is incredibly challenging because it is an extremely complicated task that involves visual perception and high-level reasoning processes. In this paper, we propose the neural-symbolic learning (NSL) framework that performs human-like learning by unifying deep neural learning and symbolic logical reasoning for the spinal medical report generation. Generally speaking, the NSL framework firstly employs deep neural learning to imitate human visual perception for detecting abnormalities of target spinal structures. Concretely, we design an adversarial graph network that interpolates a symbolic graph reasoning module into a generative adversarial network through embedding prior domain knowledge, achieving semantic segmentation of spinal structures with high complexity and variability. NSL secondly conducts human-like symbolic logical reasoning that realizes unsupervised causal effect analysis of detected entities of abnormalities through meta-interpretive learning. NSL finally fills these discoveries of target diseases into a unified template, successfully achieving a comprehensive medical report generation. When it employed in a real-world clinical dataset, a series of empirical studies demonstrate its capacity on spinal medical report generation as well as show that our algorithm remarkably exceeds existing methods in the detection of spinal structures. These indicate its potential as a clinical tool that contributes to computer-aided diagnosis.