 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseTrain:Leveraging Dynamic Sparsity in Training DNNs on General-Purpose SIMD Processors
Paper and Code
Nov 22, 2019
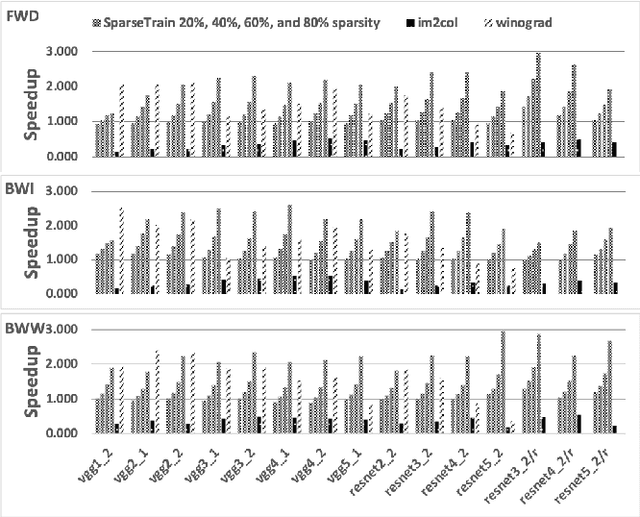
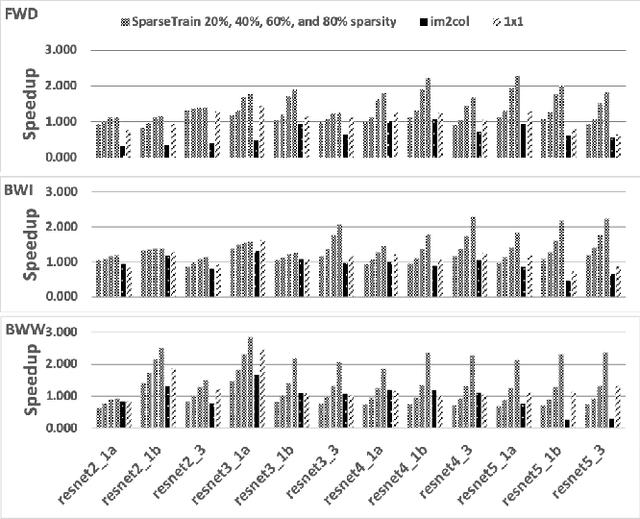
Our community has greatly improved the efficiency of deep learning applications, including by exploiting sparsity in inputs. Most of that work, though, is for inference, where weight sparsity is known statically, and/or for specialized hardware. We propose a scheme to leverage dynamic sparsity during training. In particular, we exploit zeros introduced by the ReLU activation function to both feature maps and their gradients. This is challenging because the sparsity degree is moderate and the locations of zeros change over time. We also rely purely on software. We identify zeros in a dense data representation without transforming the data and performs conventional vectorized computation. Variations of the scheme are applicable to all major components of training: forward propagation, backward propagation by inputs, and backward propagation by weights. Our method significantly outperforms a highly-optimized dense direct convolution on several popular deep neural networks. At realistic sparsity, we speed up the training of the non-initial convolutional layers in VGG16, ResNet-34, ResNet-50, and Fixup ResNet-50 by 2.19x, 1.37x, 1.31x, and 1.51x respectively on an Intel Skylake-X CPU.