 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Aided Compilation for Tensor Accelerators
Aug 06, 2024Hardware accelerators, in particular accelerators for tensor processing, have many potential application domains. However, they currently lack the software infrastructure to support the majority of domains outside of deep learning. Furthermore, a compiler that can easily be updated to reflect changes at both application and hardware levels would enable more agile development and design space exploration of accelerators, allowing hardware designers to realize closer-to-optimal performance. In this work, we discuss how large language models (LLMs) could be leveraged to build such a compiler. Specifically, we demonstrate the ability of GPT-4 to achieve high pass rates in translating code to the Gemmini accelerator, and prototype a technique for decomposing translation into smaller, more LLM-friendly steps. Additionally, we propose a 2-phase workflow for utilizing LLMs to generate hardware-optimized code.
SlimFit: Memory-Efficient Fine-Tuning of Transformer-based Models Using Training Dynamics
May 29, 2023



Transformer-based models, such as BERT and ViT, have achieved state-of-the-art results across different natural language processing (NLP) and computer vision (CV) tasks. However, these models are extremely memory intensive during their fine-tuning process, making them difficult to deploy on GPUs with limited memory resources. To address this issue, we introduce a new tool called SlimFit that reduces the memory requirements of these models by dynamically analyzing their training dynamics and freezing less-contributory layers during fine-tuning. The layers to freeze are chosen using a runtime inter-layer scheduling algorithm. SlimFit adopts quantization and pruning for particular layers to balance the load of dynamic activations and to minimize the memory footprint of static activations, where static activations refer to those that cannot be discarded regardless of freezing. This allows SlimFit to freeze up to 95% of layers and reduce the overall on-device GPU memory usage of transformer-based models such as ViT and BERT by an average of 2.2x, across different NLP and CV benchmarks/datasets such as GLUE, SQuAD 2.0, CIFAR-10, CIFAR-100 and ImageNet with an average degradation of 0.2% in accuracy. For such NLP and CV tasks, SlimFit can reduce up to 3.1x the total on-device memory usage with an accuracy degradation of only up to 0.4%. As a result, while fine-tuning of ViT on ImageNet and BERT on SQuAD 2.0 with a batch size of 128 requires 3 and 2 32GB GPUs respectively, SlimFit enables their fine-tuning on a single 32GB GPU without any significant accuracy degradation.
Dynamic Tensor Rematerialization
Jun 18, 2020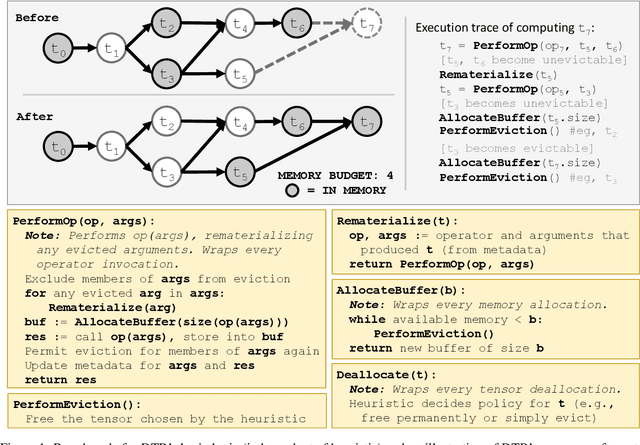

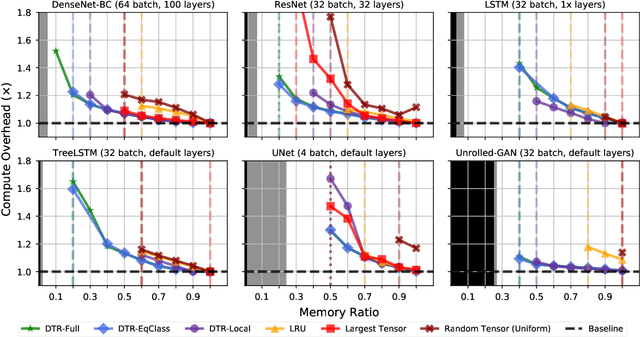
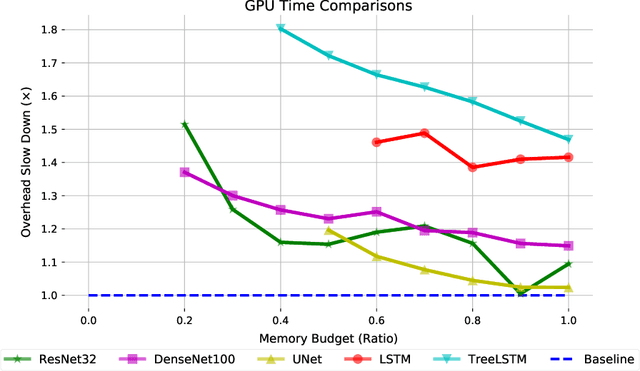
Checkpointing enables training larger models by freeing intermediate activations and recomputing them on demand. Previous checkpointing techniques are difficult to generalize to dynamic models because they statically plan recomputations offline. We present Dynamic Tensor Rematerialization (DTR), a greedy online algorithm for heuristically checkpointing arbitrary models. DTR is extensible and general: it is parameterized by an eviction policy and only collects lightweight metadata on tensors and operators. Though DTR has no advance knowledge of the model or training task, we prove it can train an $N$-layer feedforward network on an $\Omega(\sqrt{N})$ memory budget with only $\mathcal{O}(N)$ tensor operations. Moreover, we identify a general eviction heuristic and show how it allows DTR to automatically provide favorable checkpointing performance across a variety of models and memory budgets.