 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Throughput SAT Sampling
Feb 12, 2025In this work, we present a novel technique for GPU-accelerated Boolean satisfiability (SAT) sampling. Unlike conventional sampling algorithms that directly operate on conjunctive normal form (CNF), our method transforms the logical constraints of SAT problems by factoring their CNF representations into simplified multi-level, multi-output Boolean functions. It then leverages gradient-based optimization to guide the search for a diverse set of valid solutions. Our method operates directly on the circuit structure of refactored SAT instances, reinterpreting the SAT problem as a supervised multi-output regression task. This differentiable technique enables independent bit-wise operations on each tensor element, allowing parallel execution of learning processes. As a result, we achieve GPU-accelerated sampling with significant runtime improvements ranging from $33.6\times$ to $523.6\times$ over state-of-the-art heuristic samplers. We demonstrate the superior performance of our sampling method through an extensive evaluation on $60$ instances from a public domain benchmark suite utilized in previous studies.
SlimFit: Memory-Efficient Fine-Tuning of Transformer-based Models Using Training Dynamics
May 29, 2023



Transformer-based models, such as BERT and ViT, have achieved state-of-the-art results across different natural language processing (NLP) and computer vision (CV) tasks. However, these models are extremely memory intensive during their fine-tuning process, making them difficult to deploy on GPUs with limited memory resources. To address this issue, we introduce a new tool called SlimFit that reduces the memory requirements of these models by dynamically analyzing their training dynamics and freezing less-contributory layers during fine-tuning. The layers to freeze are chosen using a runtime inter-layer scheduling algorithm. SlimFit adopts quantization and pruning for particular layers to balance the load of dynamic activations and to minimize the memory footprint of static activations, where static activations refer to those that cannot be discarded regardless of freezing. This allows SlimFit to freeze up to 95% of layers and reduce the overall on-device GPU memory usage of transformer-based models such as ViT and BERT by an average of 2.2x, across different NLP and CV benchmarks/datasets such as GLUE, SQuAD 2.0, CIFAR-10, CIFAR-100 and ImageNet with an average degradation of 0.2% in accuracy. For such NLP and CV tasks, SlimFit can reduce up to 3.1x the total on-device memory usage with an accuracy degradation of only up to 0.4%. As a result, while fine-tuning of ViT on ImageNet and BERT on SQuAD 2.0 with a batch size of 128 requires 3 and 2 32GB GPUs respectively, SlimFit enables their fine-tuning on a single 32GB GPU without any significant accuracy degradation.
Standard Deviation-Based Quantization for Deep Neural Networks
Feb 24, 2022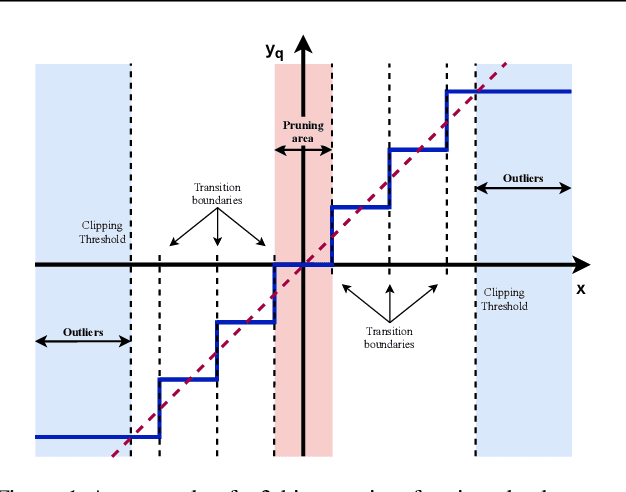
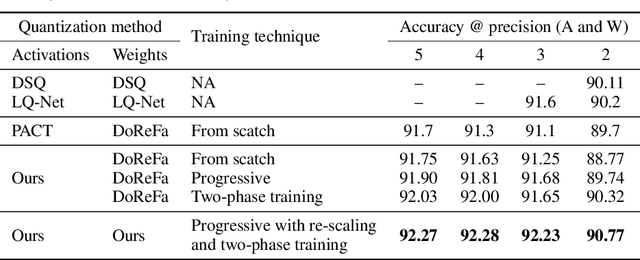
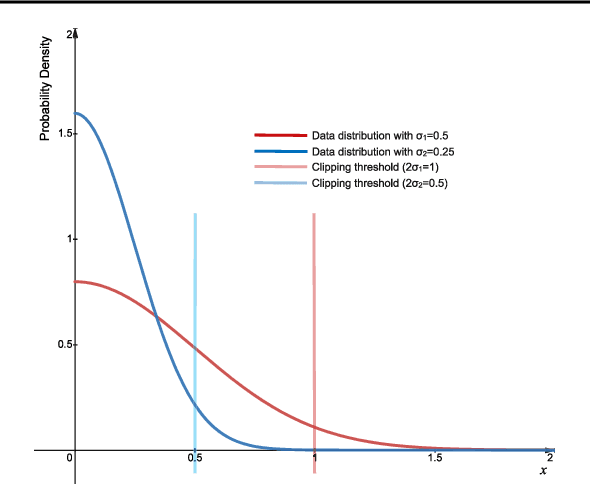
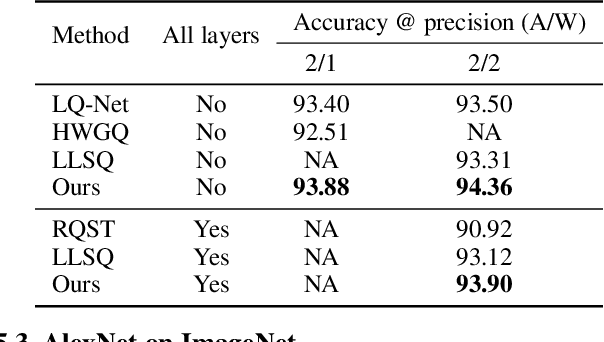
Quantization of deep neural networks is a promising approach that reduces the inference cost, making it feasible to run deep networks on resource-restricted devices. Inspired by existing methods, we propose a new framework to learn the quantization intervals (discrete values) using the knowledge of the network's weight and activation distributions, i.e., standard deviation. Furthermore, we propose a novel base-2 logarithmic quantization scheme to quantize weights to power-of-two discrete values. Our proposed scheme allows us to replace resource-hungry high-precision multipliers with simple shift-add operations. According to our evaluations, our method outperforms existing work on CIFAR10 and ImageNet datasets and even achieves better accuracy performance with 3-bit weights and activations when compared to the full-precision models. Moreover, our scheme simultaneously prunes the network's parameters and allows us to flexibly adjust the pruning ratio during the quantization process.
Learning to Skip Ineffectual Recurrent Computations in LSTMs
Nov 29, 2018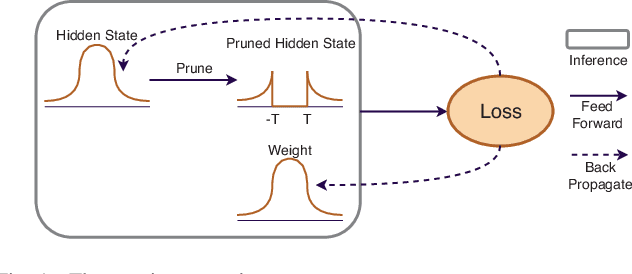
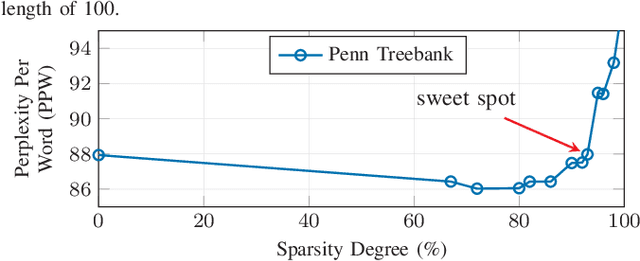


Long Short-Term Memory (LSTM) is a special class of recurrent neural network, which has shown remarkable successes in processing sequential data. The typical architecture of an LSTM involves a set of states and gates: the states retain information over arbitrary time intervals and the gates regulate the flow of information. Due to the recursive nature of LSTMs, they are computationally intensive to deploy on edge devices with limited hardware resources. To reduce the computational complexity of LSTMs, we first introduce a method that learns to retain only the important information in the states by pruning redundant information. We then show that our method can prune over 90% of information in the states without incurring any accuracy degradation over a set of temporal tasks. This observation suggests that a large fraction of the recurrent computations are ineffectual and can be avoided to speed up the process during the inference as they involve noncontributory multiplications/accumulations with zero-valued states. Finally, we introduce a custom hardware accelerator that can perform the recurrent computations using both sparse and dense states. Experimental measurements show that performing the computations using the sparse states speeds up the process and improves energy efficiency by up to 5.2x when compared to implementation results of the accelerator performing the computations using dense states.
Learning Recurrent Binary/Ternary Weights
Sep 28, 2018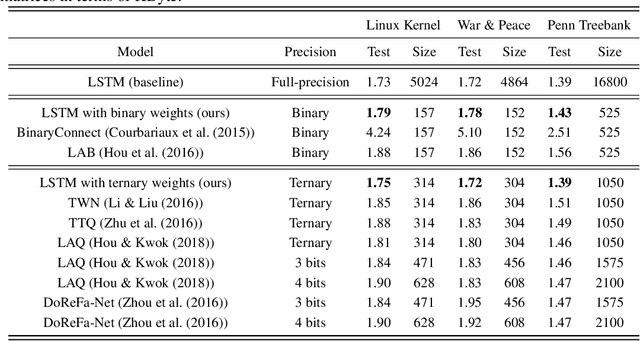
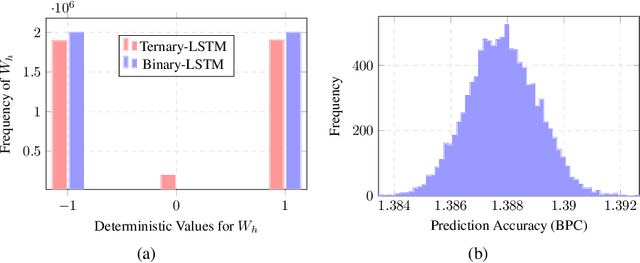

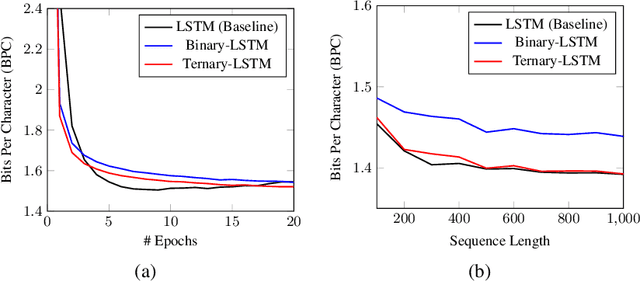
Recurrent neural networks (RNNs) have shown excellent performance in processing sequence data. However, they are both complex and memory intensive due to their recursive nature. These limitations make RNNs difficult to embed on mobile devices requiring real-time processes with limited hardware resources. To address the above issues, we introduce a method that can learn binary and ternary weights during the training phase to facilitate hardware implementations of RNNs. As a result, using this approach replaces all multiply-accumulate operations by simple accumulations, bringing significant benefits to custom hardware in terms of silicon area and power consumption. On the software side, we evaluate the performance (in terms of accuracy) of our method using long short-term memories (LSTMs) on various sequential models including sequence classification and language modeling. We demonstrate that our method achieves competitive results on the aforementioned tasks while using binary/ternary weights during the runtime. On the hardware side, we present custom hardware for accelerating the recurrent computations of LSTMs with binary/ternary weights. Ultimately, we show that LSTMs with binary/ternary weights can achieve up to 12x memory saving and 10x inference speedup compared to the full-precision implementation on an ASIC platform.
Sparsely-Connected Neural Networks: Towards Efficient VLSI Implementation of Deep Neural Networks
Mar 30, 2017
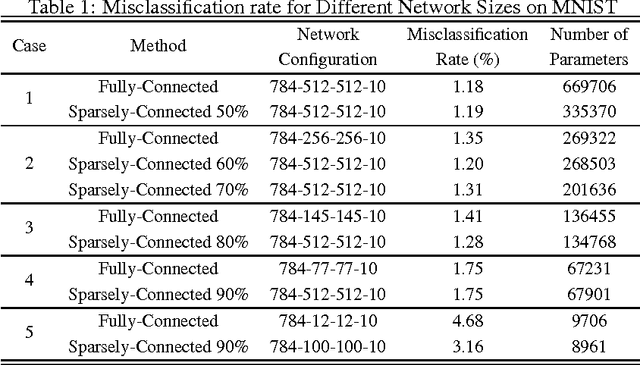
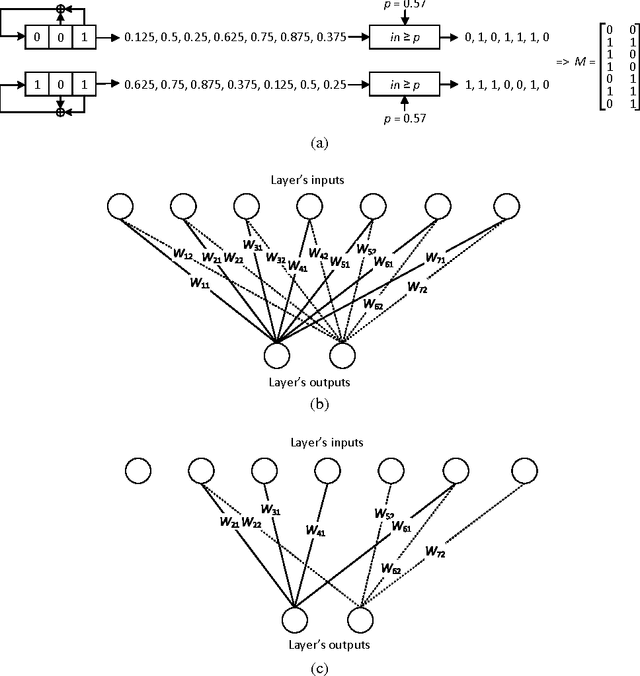
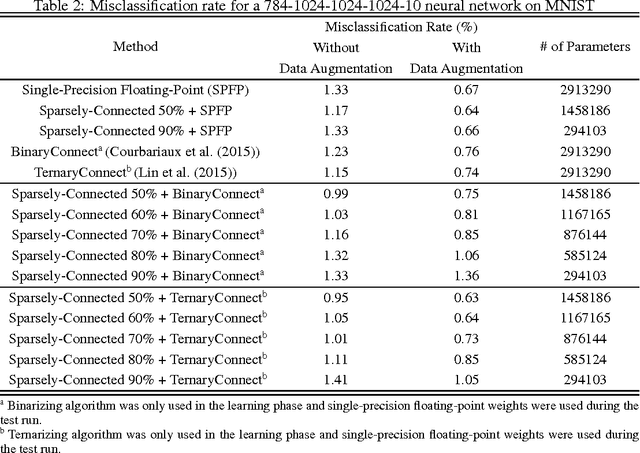
Recently deep neural networks have received considerable attention due to their ability to extract and represent high-level abstractions in data sets. Deep neural networks such as fully-connected and convolutional neural networks have shown excellent performance on a wide range of recognition and classification tasks. However, their hardware implementations currently suffer from large silicon area and high power consumption due to the their high degree of complexity. The power/energy consumption of neural networks is dominated by memory accesses, the majority of which occur in fully-connected networks. In fact, they contain most of the deep neural network parameters. In this paper, we propose sparsely-connected networks, by showing that the number of connections in fully-connected networks can be reduced by up to 90% while improving the accuracy performance on three popular datasets (MNIST, CIFAR10 and SVHN). We then propose an efficient hardware architecture based on linear-feedback shift registers to reduce the memory requirements of the proposed sparsely-connected networks. The proposed architecture can save up to 90% of memory compared to the conventional implementations of fully-connected neural networks. Moreover, implementation results show up to 84% reduction in the energy consumption of a single neuron of the proposed sparsely-connected networks compared to a single neuron of fully-connected neural networks.
VLSI Implementation of Deep Neural Network Using Integral Stochastic Computing
Aug 24, 2016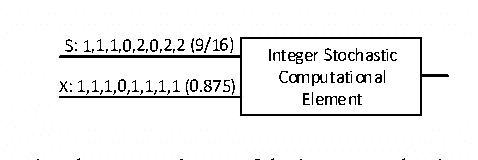
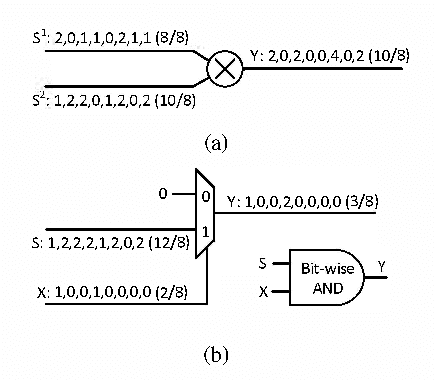
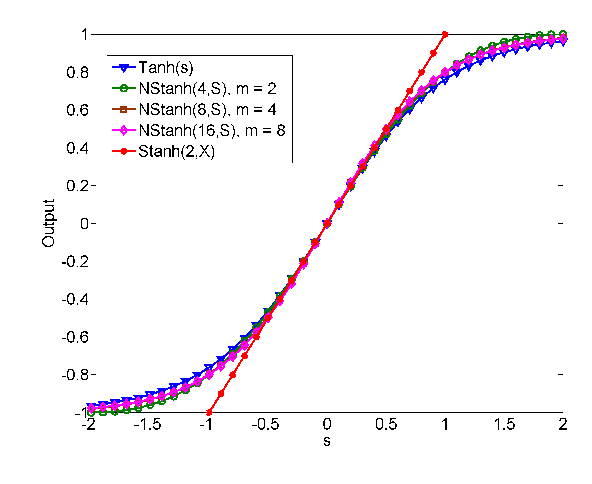
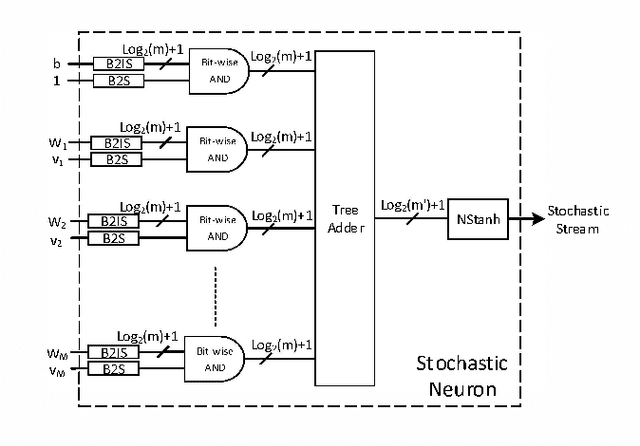
The hardware implementation of deep neural networks (DNNs) has recently received tremendous attention: many applications in fact require high-speed operations that suit a hardware implementation. However, numerous elements and complex interconnections are usually required, leading to a large area occupation and copious power consumption. Stochastic computing has shown promising results for low-power area-efficient hardware implementations, even though existing stochastic algorithms require long streams that cause long latencies. In this paper, we propose an integer form of stochastic computation and introduce some elementary circuits. We then propose an efficient implementation of a DNN based on integral stochastic computing. The proposed architecture has been implemented on a Virtex7 FPGA, resulting in 45% and 62% average reductions in area and latency compared to the best reported architecture in literature. We also synthesize the circuits in a 65 nm CMOS technology and we show that the proposed integral stochastic architecture results in up to 21% reduction in energy consumption compared to the binary radix implementation at the same misclassification rate. Due to fault-tolerant nature of stochastic architectures, we also consider a quasi-synchronous implementation which yields 33% reduction in energy consumption w.r.t. the binary radix implementation without any compromise on performance.
* 11 pages, 12 figures