 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStandard Deviation-Based Quantization for Deep Neural Networks
Feb 24, 2022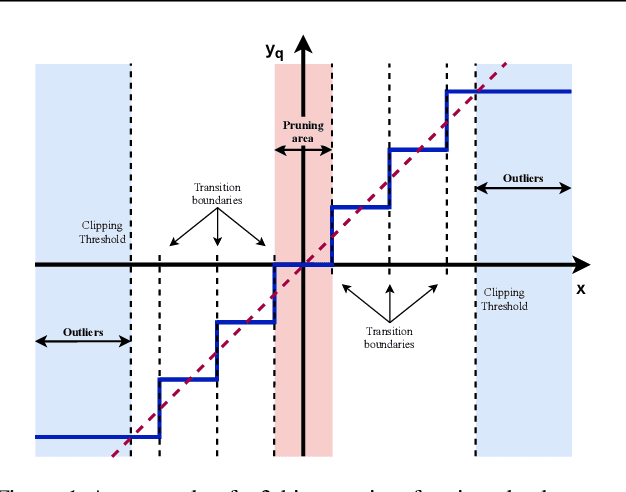
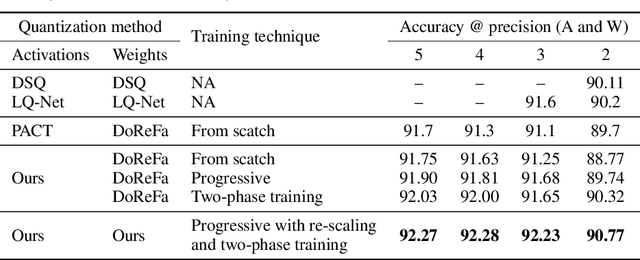
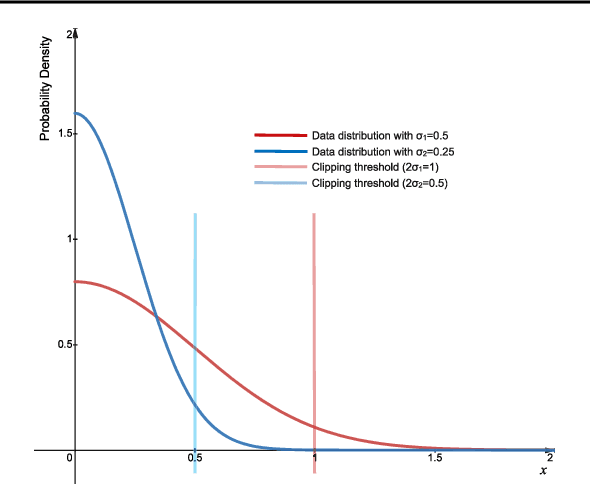
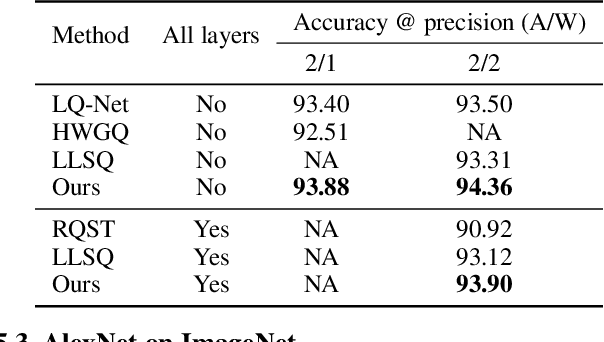
Quantization of deep neural networks is a promising approach that reduces the inference cost, making it feasible to run deep networks on resource-restricted devices. Inspired by existing methods, we propose a new framework to learn the quantization intervals (discrete values) using the knowledge of the network's weight and activation distributions, i.e., standard deviation. Furthermore, we propose a novel base-2 logarithmic quantization scheme to quantize weights to power-of-two discrete values. Our proposed scheme allows us to replace resource-hungry high-precision multipliers with simple shift-add operations. According to our evaluations, our method outperforms existing work on CIFAR10 and ImageNet datasets and even achieves better accuracy performance with 3-bit weights and activations when compared to the full-precision models. Moreover, our scheme simultaneously prunes the network's parameters and allows us to flexibly adjust the pruning ratio during the quantization process.