 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Recurrent Binary/Ternary Weights
Sep 28, 2018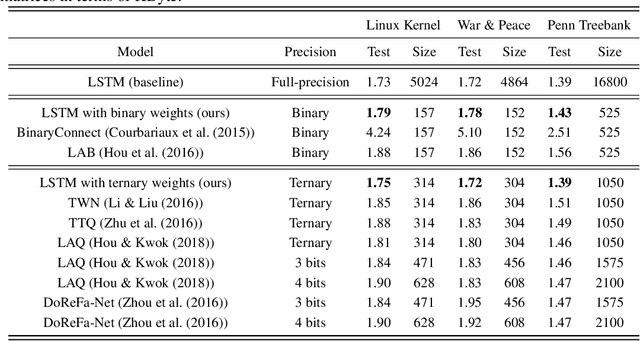
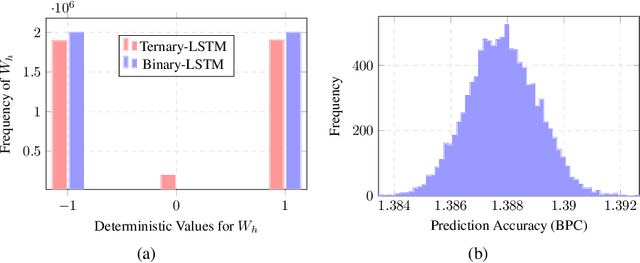

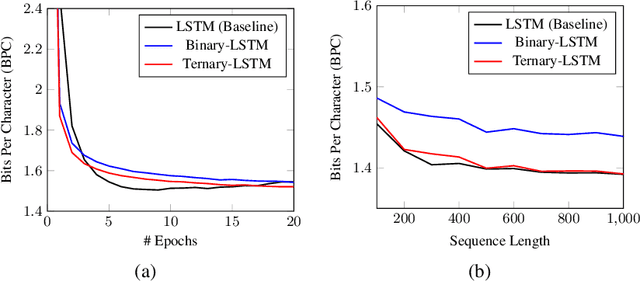
Recurrent neural networks (RNNs) have shown excellent performance in processing sequence data. However, they are both complex and memory intensive due to their recursive nature. These limitations make RNNs difficult to embed on mobile devices requiring real-time processes with limited hardware resources. To address the above issues, we introduce a method that can learn binary and ternary weights during the training phase to facilitate hardware implementations of RNNs. As a result, using this approach replaces all multiply-accumulate operations by simple accumulations, bringing significant benefits to custom hardware in terms of silicon area and power consumption. On the software side, we evaluate the performance (in terms of accuracy) of our method using long short-term memories (LSTMs) on various sequential models including sequence classification and language modeling. We demonstrate that our method achieves competitive results on the aforementioned tasks while using binary/ternary weights during the runtime. On the hardware side, we present custom hardware for accelerating the recurrent computations of LSTMs with binary/ternary weights. Ultimately, we show that LSTMs with binary/ternary weights can achieve up to 12x memory saving and 10x inference speedup compared to the full-precision implementation on an ASIC platform.
Neural Networks Designing Neural Networks: Multi-Objective Hyper-Parameter Optimization
Nov 07, 2016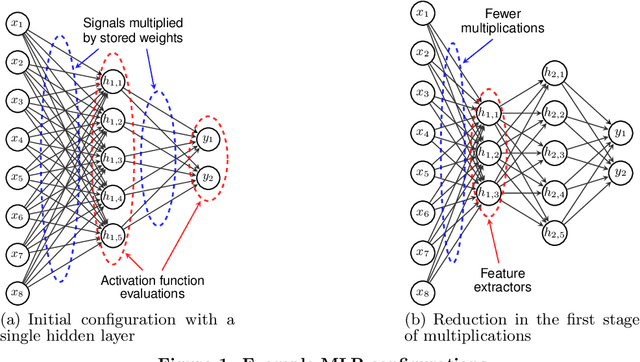

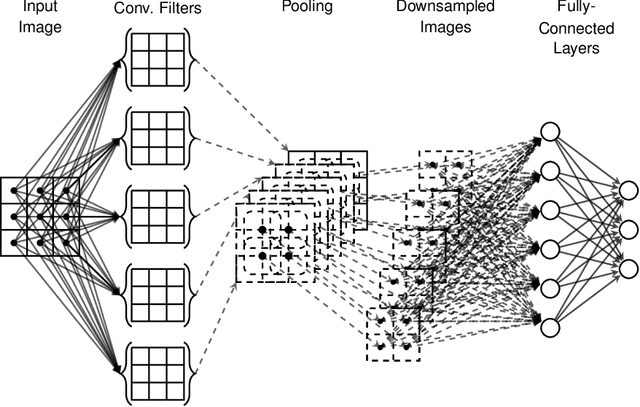
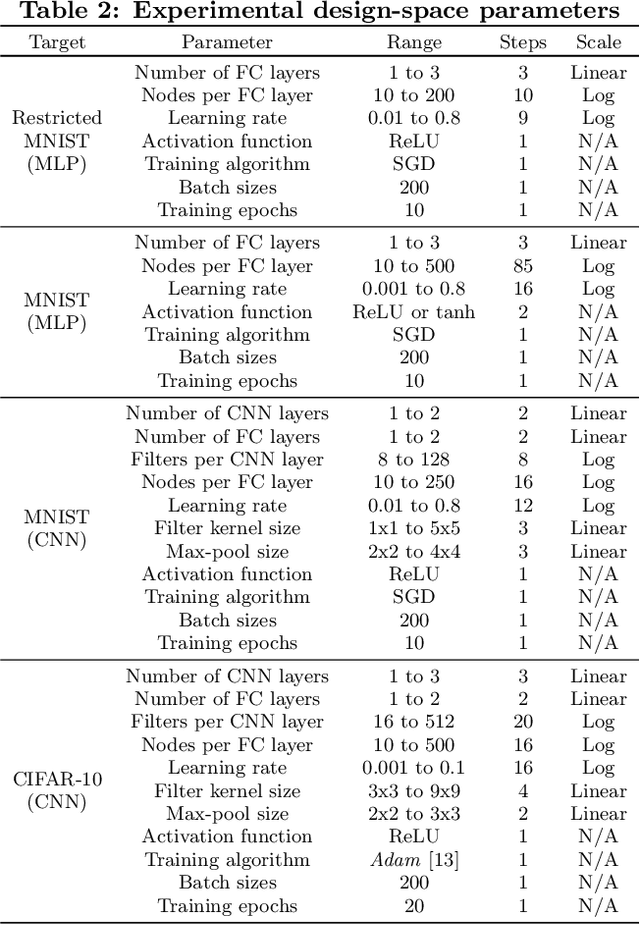
Artificial neural networks have gone through a recent rise in popularity, achieving state-of-the-art results in various fields, including image classification, speech recognition, and automated control. Both the performance and computational complexity of such models are heavily dependant on the design of characteristic hyper-parameters (e.g., number of hidden layers, nodes per layer, or choice of activation functions), which have traditionally been optimized manually. With machine learning penetrating low-power mobile and embedded areas, the need to optimize not only for performance (accuracy), but also for implementation complexity, becomes paramount. In this work, we present a multi-objective design space exploration method that reduces the number of solution networks trained and evaluated through response surface modelling. Given spaces which can easily exceed 1020 solutions, manually designing a near-optimal architecture is unlikely as opportunities to reduce network complexity, while maintaining performance, may be overlooked. This problem is exacerbated by the fact that hyper-parameters which perform well on specific datasets may yield sub-par results on others, and must therefore be designed on a per-application basis. In our work, machine learning is leveraged by training an artificial neural network to predict the performance of future candidate networks. The method is evaluated on the MNIST and CIFAR-10 image datasets, optimizing for both recognition accuracy and computational complexity. Experimental results demonstrate that the proposed method can closely approximate the Pareto-optimal front, while only exploring a small fraction of the design space.