 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Skip Ineffectual Recurrent Computations in LSTMs
Nov 29, 2018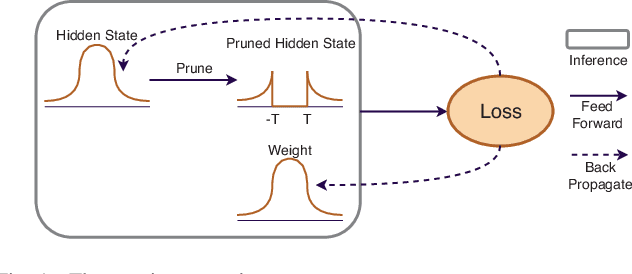
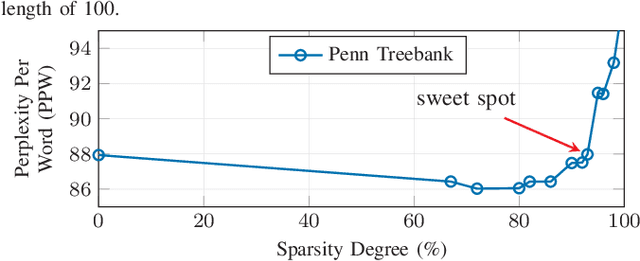


Long Short-Term Memory (LSTM) is a special class of recurrent neural network, which has shown remarkable successes in processing sequential data. The typical architecture of an LSTM involves a set of states and gates: the states retain information over arbitrary time intervals and the gates regulate the flow of information. Due to the recursive nature of LSTMs, they are computationally intensive to deploy on edge devices with limited hardware resources. To reduce the computational complexity of LSTMs, we first introduce a method that learns to retain only the important information in the states by pruning redundant information. We then show that our method can prune over 90% of information in the states without incurring any accuracy degradation over a set of temporal tasks. This observation suggests that a large fraction of the recurrent computations are ineffectual and can be avoided to speed up the process during the inference as they involve noncontributory multiplications/accumulations with zero-valued states. Finally, we introduce a custom hardware accelerator that can perform the recurrent computations using both sparse and dense states. Experimental measurements show that performing the computations using the sparse states speeds up the process and improves energy efficiency by up to 5.2x when compared to implementation results of the accelerator performing the computations using dense states.
Learning Recurrent Binary/Ternary Weights
Sep 28, 2018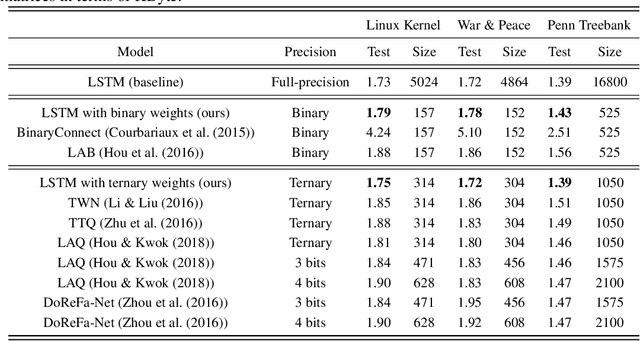
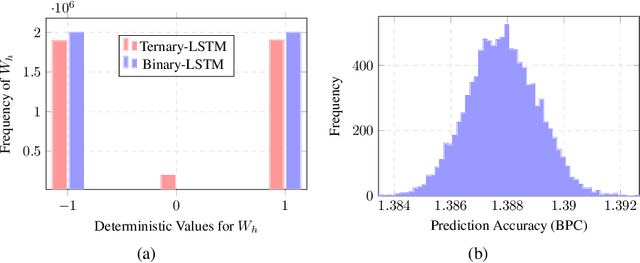

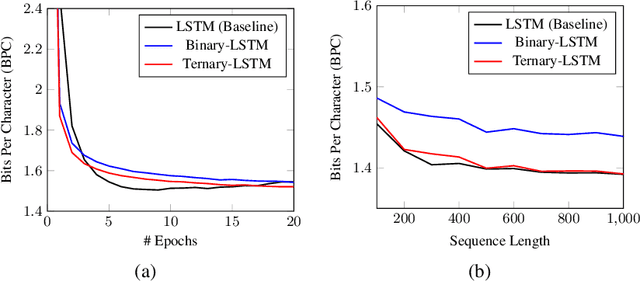
Recurrent neural networks (RNNs) have shown excellent performance in processing sequence data. However, they are both complex and memory intensive due to their recursive nature. These limitations make RNNs difficult to embed on mobile devices requiring real-time processes with limited hardware resources. To address the above issues, we introduce a method that can learn binary and ternary weights during the training phase to facilitate hardware implementations of RNNs. As a result, using this approach replaces all multiply-accumulate operations by simple accumulations, bringing significant benefits to custom hardware in terms of silicon area and power consumption. On the software side, we evaluate the performance (in terms of accuracy) of our method using long short-term memories (LSTMs) on various sequential models including sequence classification and language modeling. We demonstrate that our method achieves competitive results on the aforementioned tasks while using binary/ternary weights during the runtime. On the hardware side, we present custom hardware for accelerating the recurrent computations of LSTMs with binary/ternary weights. Ultimately, we show that LSTMs with binary/ternary weights can achieve up to 12x memory saving and 10x inference speedup compared to the full-precision implementation on an ASIC platform.