 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient FPGA Implementation of Stochastic Simulated Annealing
Jan 25, 2026Simulated annealing (SA) is a well-known algorithm for solving combinatorial optimization problems. However, the computation time of SA increases rapidly, as the size of the problem grows. Recently, a stochastic simulated annealing (SSA) algorithm that converges faster than conventional SA has been reported. In this paper, we present a hardware-aware SSA (HA- SSA) algorithm for memory-efficient FPGA implementations. HA-SSA can reduce the memory usage of storing intermediate results while maintaining the computing speed of SSA. For evaluation purposes, the proposed algorithm is compared with the conventional SSA and SA approaches on maximum cut combinatorial optimization problems. HA-SSA achieves a convergence speed that is up to 114-times faster than that of the conventional SA algorithm depending on the maximum cut problem selected from the G-set which is a dataset of the maximum cut problems. HA-SSA is implemented on a field-programmable gate array (FPGA) (Xilinx Kintex-7), and it achieves up to 6-times the memory efficiency of conventional SSA while maintaining high solution quality for optimization problems.
Enhanced Convergence in p-bit Based Simulated Annealing with Partial Deactivation for Large-Scale Combinatorial Optimization Problems
Jan 22, 2026This article critically investigates the limitations of the simulated annealing algorithm using probabilistic bits (pSA) in solving large-scale combinatorial optimization problems. The study begins with an in-depth analysis of the pSA process, focusing on the issues resulting from unexpected oscillations among p-bits. These oscillations hinder the energy reduction of the Ising model and thus obstruct the successful execution of pSA in complex tasks. Through detailed simulations, we unravel the root cause of this energy stagnation, identifying the feedback mechanism inherent to the pSA operation as the primary contributor to these disruptive oscillations. To address this challenge, we propose two novel algorithms, time average pSA (TApSA) and stalled pSA (SpSA). These algorithms are designed based on partial deactivation of p-bits and are thoroughly tested using Python simulations on maximum cut benchmarks that are typical combinatorial optimization problems. On the 16 benchmarks from 800 to 5,000 nodes, the proposed methods improve the normalized cut value from 0.8% to 98.4% on average in comparison with the conventional pSA.
GPU-accelerated simulated annealing based on p-bits with real-world device-variability modeling
Jan 20, 2026Probabilistic computing using probabilistic bits (p-bits) presents an efficient alternative to traditional CMOS logic for complex problem-solving, including simulated annealing and machine learning. Realizing p-bits with emerging devices such as magnetic tunnel junctions (MTJs) introduces device variability, which was expected to negatively impact computational performance. However, this study reveals an unexpected finding: device variability can not only degrade but also enhance algorithm performance, particularly by leveraging timing variability. This paper introduces a GPU-accelerated, open-source simulated annealing framework based on p-bits that models key device variability factors -timing, intensity, and offset- to reflect real-world device behavior. Through CUDA-based simulations, our approach achieves a two-order magnitude speedup over CPU implementations on the MAX-CUT benchmark with problem sizes ranging from 800 to 20,000 nodes. By providing a scalable and accessible tool, this framework aims to advance research in probabilistic computing, enabling optimization applications in diverse fields.
Local Energy Distribution Based Hyperparameter Determination for Stochastic Simulated Annealing
Apr 24, 2023



This paper presents a local energy distribution based hyperparameter determination for stochastic simulated annealing (SSA). SSA is capable of solving combinatorial optimization problems faster than typical simulated annealing (SA), but requires a time-consuming hyperparameter search. The proposed method determines hyperparameters based on the local energy distributions of spins (probabilistic bits). The spin is a basic computing element of SSA and is graphically connected to other spins with its weights. The distribution of the local energy can be estimated based on the central limit theorem (CLT). The CLT-based normal distribution is used to determine the hyperparameters, which reduces the time complexity for hyperparameter search from O(n^3) of the conventional method to O(1). The performance of SSA with the determined hyperparameters is evaluated on the Gset and K2000 benchmarks for maximum-cut problems. The results show that the proposed method achieves mean cut values of approximately 98% of the best-known cut values.
VLSI Implementation of Deep Neural Network Using Integral Stochastic Computing
Aug 24, 2016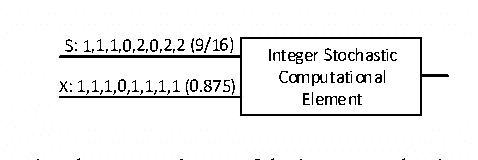
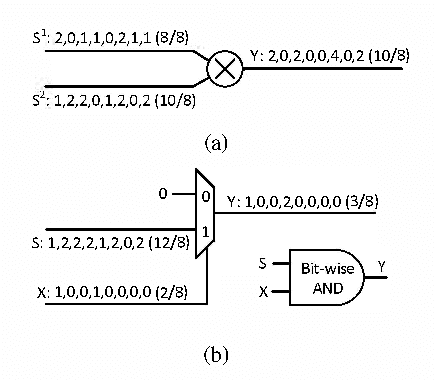
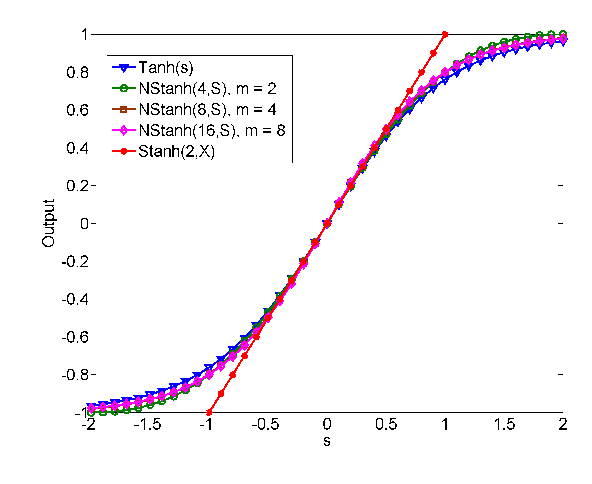
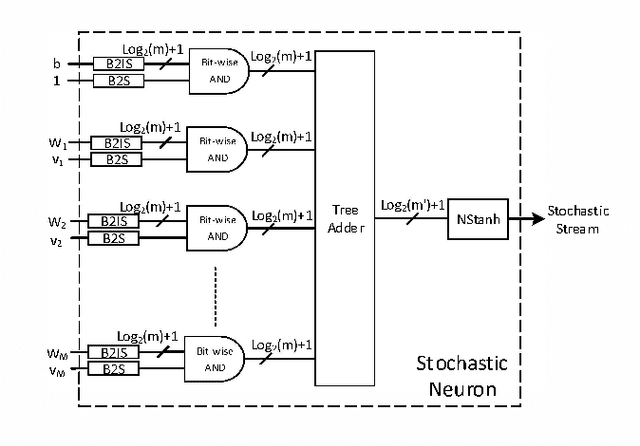
The hardware implementation of deep neural networks (DNNs) has recently received tremendous attention: many applications in fact require high-speed operations that suit a hardware implementation. However, numerous elements and complex interconnections are usually required, leading to a large area occupation and copious power consumption. Stochastic computing has shown promising results for low-power area-efficient hardware implementations, even though existing stochastic algorithms require long streams that cause long latencies. In this paper, we propose an integer form of stochastic computation and introduce some elementary circuits. We then propose an efficient implementation of a DNN based on integral stochastic computing. The proposed architecture has been implemented on a Virtex7 FPGA, resulting in 45% and 62% average reductions in area and latency compared to the best reported architecture in literature. We also synthesize the circuits in a 65 nm CMOS technology and we show that the proposed integral stochastic architecture results in up to 21% reduction in energy consumption compared to the binary radix implementation at the same misclassification rate. Due to fault-tolerant nature of stochastic architectures, we also consider a quasi-synchronous implementation which yields 33% reduction in energy consumption w.r.t. the binary radix implementation without any compromise on performance.
* 11 pages, 12 figures
Associative Memories Based on Multiple-Valued Sparse Clustered Networks
Feb 03, 2014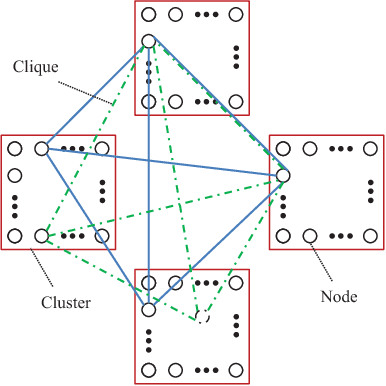
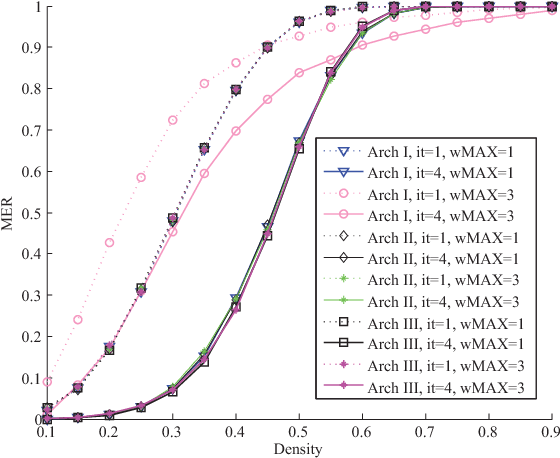
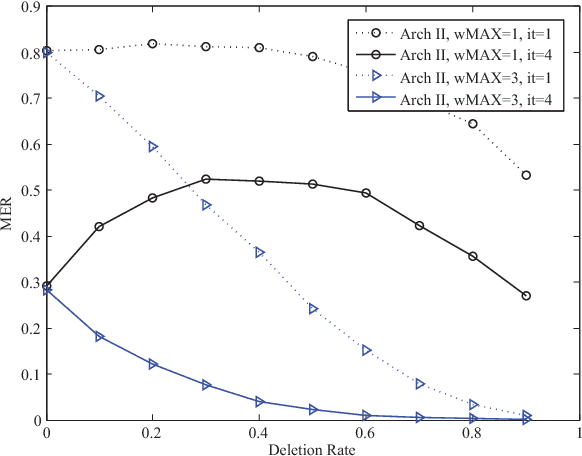
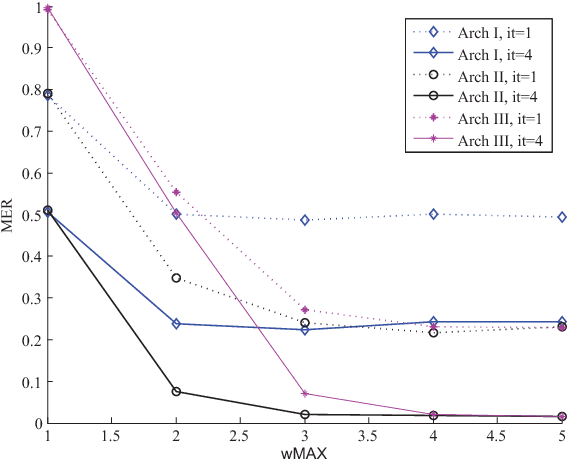
Associative memories are structures that store data patterns and retrieve them given partial inputs. Sparse Clustered Networks (SCNs) are recently-introduced binary-weighted associative memories that significantly improve the storage and retrieval capabilities over the prior state-of-the art. However, deleting or updating the data patterns result in a significant increase in the data retrieval error probability. In this paper, we propose an algorithm to address this problem by incorporating multiple-valued weights for the interconnections used in the network. The proposed algorithm lowers the error rate by an order of magnitude for our sample network with 60% deleted contents. We then investigate the advantages of the proposed algorithm for hardware implementations.