 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Programming Elicitation and Repair for Text-to-Code in Very Low-Resource Programming Languages
Jun 05, 2024



Recent advances in large language models (LLMs) for code applications have demonstrated remarkable zero-shot fluency and instruction following on challenging code related tasks ranging from test case generation to self-repair. Unsurprisingly, however, models struggle to compose syntactically valid programs in programming languages unrepresented in pre-training, referred to as very low-resource Programming Languages (VLPLs). VLPLs appear in crucial settings including domain-specific languages for internal to tools and tool-chains and legacy languages. Inspired by an HCI technique called natural program elicitation, we propose designing an intermediate language that LLMs ``naturally'' know how to use and which can be automatically compiled to the target VLPL. Specifically, we introduce synthetic programming elicitation and compilation (SPEAK), an approach that enables LLMs to generate syntactically valid code even for VLPLs. We empirically evaluate the performance of SPEAK in a case study and find that, compared to existing retrieval and fine-tuning baselines, SPEAK produces syntactically correct programs more frequently without sacrificing semantic correctness.
Generating Probabilistic Scenario Programs from Natural Language
May 03, 2024
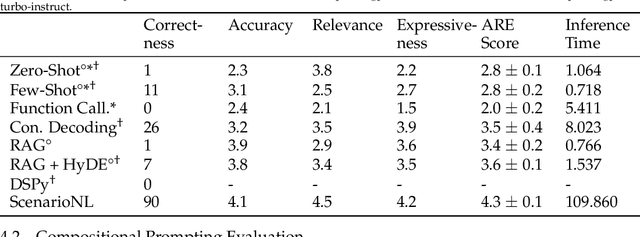

For cyber-physical systems (CPS), including robotics and autonomous vehicles, mass deployment has been hindered by fatal errors that occur when operating in rare events. To replicate rare events such as vehicle crashes, many companies have created logging systems and employed crash reconstruction experts to meticulously recreate these valuable events in simulation. However, in these methods, "what if" questions are not easily formulated and answered. We present ScenarioNL, an AI System for creating scenario programs from natural language. Specifically, we generate these programs from police crash reports. Reports normally contain uncertainty about the exact details of the incidents which we represent through a Probabilistic Programming Language (PPL), Scenic. By using Scenic, we can clearly and concisely represent uncertainty and variation over CPS behaviors, properties, and interactions. We demonstrate how commonplace prompting techniques with the best Large Language Models (LLM) are incapable of reasoning about probabilistic scenario programs and generating code for low-resource languages such as Scenic. Our system is comprised of several LLMs chained together with several kinds of prompting strategies, a compiler, and a simulator. We evaluate our system on publicly available autonomous vehicle crash reports in California from the last five years and share insights into how we generate code that is both semantically meaningful and syntactically correct.
$L^*LM$: Learning Automata from Examples using Natural Language Oracles
Feb 10, 2024Expert demonstrations have proven an easy way to indirectly specify complex tasks. Recent algorithms even support extracting unambiguous formal specifications, e.g. deterministic finite automata (DFA), from demonstrations. Unfortunately, these techniques are generally not sample efficient. In this work, we introduce $L^*LM$, an algorithm for learning DFAs from both demonstrations and natural language. Due to the expressivity of natural language, we observe a significant improvement in the data efficiency of learning DFAs from expert demonstrations. Technically, $L^*LM$ leverages large language models to answer membership queries about the underlying task. This is then combined with recent techniques for transforming learning from demonstrations into a sequence of labeled example learning problems. In our experiments, we observe the two modalities complement each other, yielding a powerful few-shot learner.
Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game
Nov 02, 2023While Large Language Models (LLMs) are increasingly being used in real-world applications, they remain vulnerable to prompt injection attacks: malicious third party prompts that subvert the intent of the system designer. To help researchers study this problem, we present a dataset of over 126,000 prompt injection attacks and 46,000 prompt-based "defenses" against prompt injection, all created by players of an online game called Tensor Trust. To the best of our knowledge, this is currently the largest dataset of human-generated adversarial examples for instruction-following LLMs. The attacks in our dataset have a lot of easily interpretable stucture, and shed light on the weaknesses of LLMs. We also use the dataset to create a benchmark for resistance to two types of prompt injection, which we refer to as prompt extraction and prompt hijacking. Our benchmark results show that many models are vulnerable to the attack strategies in the Tensor Trust dataset. Furthermore, we show that some attack strategies from the dataset generalize to deployed LLM-based applications, even though they have a very different set of constraints to the game. We release all data and source code at https://tensortrust.ai/paper