 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting User Experience on Laptops from Hardware Specifications
Feb 14, 2024Estimating the overall user experience (UX) on a device is a common challenge faced by manufacturers. Today, device makers primarily rely on microbenchmark scores, such as Geekbench, that stress test specific hardware components, such as CPU or RAM, but do not satisfactorily capture consumer workloads. System designers often rely on domain-specific heuristics and extensive testing of prototypes to reach a desired UX goal, and yet there is often a mismatch between the manufacturers' performance claims and the consumers' experience. We present our initial results on predicting real-life experience on laptops from their hardware specifications. We target web applications that run on Chromebooks (ChromeOS laptops) for a simple and fair aggregation of experience across applications and workloads. On 54 laptops, we track 9 UX metrics on common end-user workloads: web browsing, video playback and audio/video calls. We focus on a subset of high-level metrics exposed by the Chrome browser, that are part of the Web Vitals initiative for judging the UX on web applications. With a dataset of 100K UX data points, we train gradient boosted regression trees that predict the metric values from device specifications. Across our 9 metrics, we note a mean $R^2$ score (goodness-of-fit on our dataset) of 97.8% and a mean MAAPE (percentage error in prediction on unseen data) of 10.1%.
OASIS: ILP-Guided Synthesis of Loop Invariants
Nov 26, 2019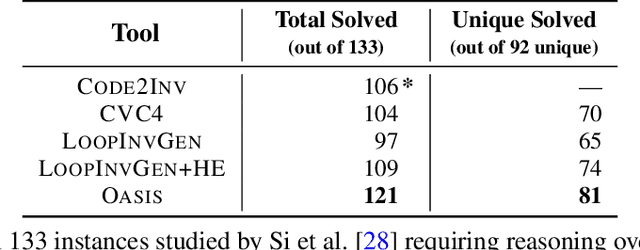
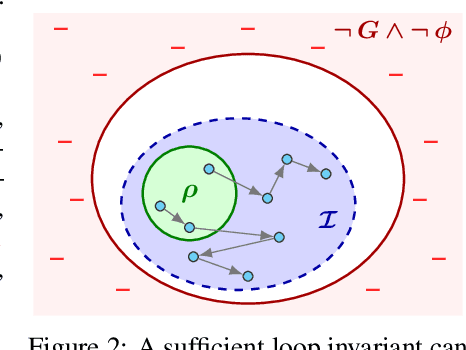

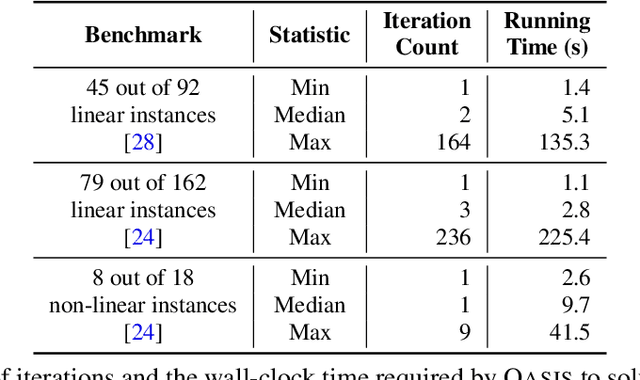
Finding appropriate inductive loop invariants for a program is a key challenge in verifying its functional properties. Although the problem is undecidable in general, several heuristics have been proposed to handle practical programs that tend to have simple control-flow structures. However, these heuristics only work well when the space of invariants is small. On the other hand, machine-learned techniques that use continuous optimization have a high sample complexity, i.e., the number of invariant guesses and the associated counterexamples, since the invariant is required to exactly satisfy a specification. We propose a novel technique that is able to solve complex verification problems involving programs with larger number of variables and non-linear specifications. We formulate an invariant as a piecewise low-degree polynomial, and reduce the problem of synthesizing it to a set of integer linear programming (ILP) problems. This enables the use of state-of-the-art ILP techniques that combine enumerative search with continuous optimization; thus ensuring fast convergence for a large class of verification tasks while still ensuring low sample complexity. We instantiate our technique as the open-source oasis tool using an off-the-shelf ILP solver, and evaluate it on more than 300 benchmark tasks collected from the annual SyGuS competition and recent prior work. Our experiments show that oasis outperforms the state-of-the-art tools, including the winner of last year's SyGuS competition, and is able to solve 9 challenging tasks that existing tools fail on.
Overfitting in Synthesis: Theory and Practice (Extender Version)
May 27, 2019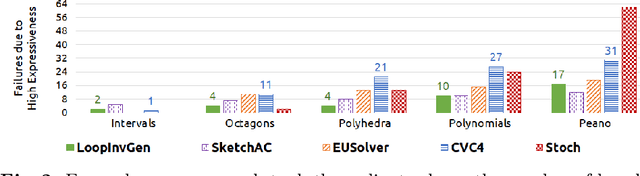


In syntax-guided synthesis (SyGuS), a synthesizer's goal is to automatically generate a program belonging to a grammar of possible implementations that meets a logical specification. We investigate a common limitation across state-of-the-art SyGuS tools that perform counterexample-guided inductive synthesis (CEGIS). We empirically observe that as the expressiveness of the provided grammar increases, the performance of these tools degrades significantly. We claim that this degradation is not only due to a larger search space, but also due to overfitting. We formally define this phenomenon and prove no-free-lunch theorems for SyGuS, which reveal a fundamental tradeoff between synthesizer performance and grammar expressiveness. A standard approach to mitigate overfitting in machine learning is to run multiple learners with varying expressiveness in parallel. We demonstrate that this insight can immediately benefit existing SyGuS tools. We also propose a novel single-threaded technique called hybrid enumeration that interleaves different grammars and outperforms the winner of the 2018 SyGuS competition (Inv track), solving more problems and achieving a $5\times$ mean speedup.
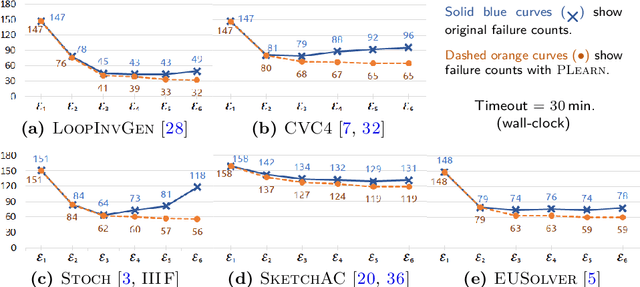
LoopInvGen: A Loop Invariant Generator based on Precondition Inference
Jul 08, 2018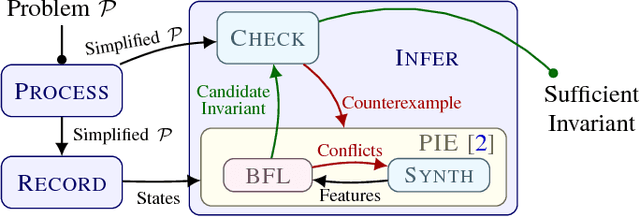

We describe the LoopInvGen tool for generating loop invariants that can provably guarantee correctness of a program with respect to a given specification. LoopInvGen is an efficient implementation of the inference technique originally proposed in our earlier work on PIE (https://doi.org/10.1145/2908080.2908099). In contrast to existing techniques, LoopInvGen is not restricted to a fixed set of features -- atomic predicates that are composed together to build complex loop invariants. Instead, we start with no initial features, and use program synthesis techniques to grow the set on demand. This not only enables a less onerous and more expressive approach, but also appears to be significantly faster than the existing tools over the SyGuS-COMP 2017 benchmarks from the INV track.
FlashProfile: Interactive Synthesis of Syntactic Profiles
Sep 17, 2017

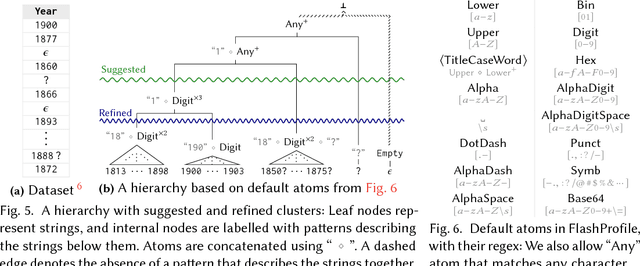
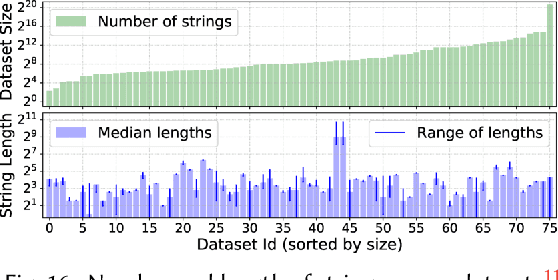
We address the problem of learning comprehensive syntactic profiles for a set of strings. Real-world datasets, typically curated from multiple sources, often contain data in various formats. Thus any data processing task is preceded by the critical step of data format identification. However, manual inspection of data to identify various formats is infeasible in standard big-data scenarios. We present a technique for generating comprehensive syntactic profiles in terms of user-defined patterns that also allows for interactive refinement. We define a syntactic profile as a set of succinct patterns that describe the entire dataset. Our approach efficiently learns such profiles, and allows refinement by exposing a desired number of patterns. Our implementation, FlashProfile, shows a median profiling time of 0.7s over 142 tasks on 74 real datasets. We also show that access to the generated data profiles allow for more accurate synthesis of programs, using fewer examples in programming-by-example workflows.