 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-theoretic User Interaction: Significant Inputs for Program Synthesis
Jun 22, 2020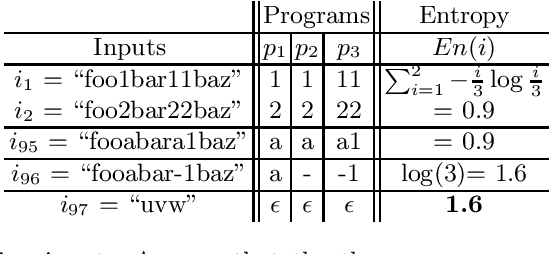
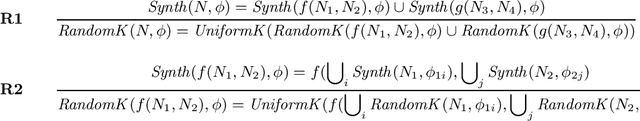
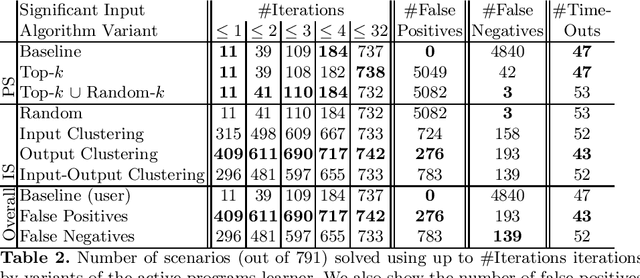
Programming-by-example technologies are being deployed in industrial products for real-time synthesis of various kinds of data transformations. These technologies rely on the user to provide few representative examples of the transformation task. Motivated by the need to find the most pertinent question to ask the user, in this paper, we introduce the {\em significant questions problem}, and show that it is hard in general. We then develop an information-theoretic greedy approach for solving the problem. We justify the greedy algorithm using the conditional entropy result, which informally says that the question that achieves the maximum information gain is the one that we know least about. In the context of interactive program synthesis, we use the above result to develop an {\em{active program learner}} that generates the significant inputs to pose as queries to the user in each iteration. The procedure requires extending a {\em{passive program learner}} to a {\em{sampling program learner}} that is able to sample candidate programs from the set of all consistent programs to enable estimation of information gain. It also uses clustering of inputs based on features in the inputs and the corresponding outputs to sample a small set of candidate significant inputs. Our active learner is able to tradeoff false negatives for false positives and converge in a small number of iterations on a real-world dataset of %around 800 string transformation tasks.
FlashProfile: Interactive Synthesis of Syntactic Profiles
Sep 17, 2017

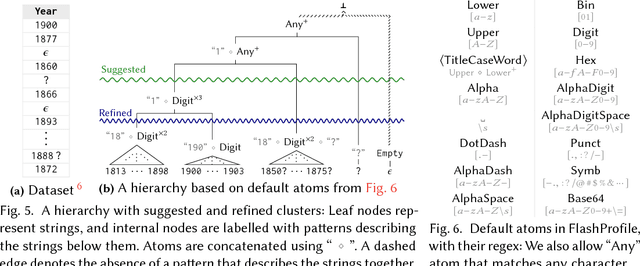
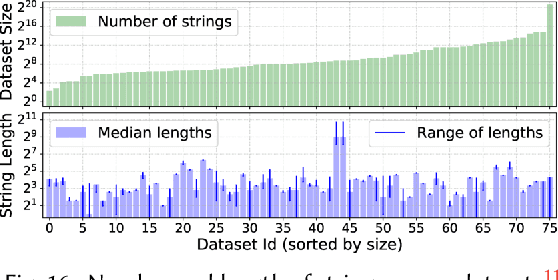
We address the problem of learning comprehensive syntactic profiles for a set of strings. Real-world datasets, typically curated from multiple sources, often contain data in various formats. Thus any data processing task is preceded by the critical step of data format identification. However, manual inspection of data to identify various formats is infeasible in standard big-data scenarios. We present a technique for generating comprehensive syntactic profiles in terms of user-defined patterns that also allows for interactive refinement. We define a syntactic profile as a set of succinct patterns that describe the entire dataset. Our approach efficiently learns such profiles, and allows refinement by exposing a desired number of patterns. Our implementation, FlashProfile, shows a median profiling time of 0.7s over 142 tasks on 74 real datasets. We also show that access to the generated data profiles allow for more accurate synthesis of programs, using fewer examples in programming-by-example workflows.