 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Language Model Reasoning via Weighted Reasoning in Self-Consistency
Oct 10, 2024



While large language models (LLMs) have rapidly improved their performance on a broad number of tasks, they still often fall short on reasoning tasks. As LLMs become more integrated in diverse real-world tasks, advancing their reasoning capabilities is crucial to their effectiveness in nuanced, complex problems. Wang et al's self-consistency framework reveals that sampling multiple rationales before taking a majority vote reliably improves model performance across various closed-answer reasoning tasks. Standard methods based on this framework aggregate the final decisions of these rationales but fail to utilize the detailed step-by-step reasoning paths applied by these paths. Our work enhances this approach by incorporating and analyzing both the reasoning paths of these rationales in addition to their final decisions before taking a majority vote. These methods not only improve the reliability of reasoning paths but also cause more robust performance on complex reasoning tasks.
Split: Inferring Unobserved Event Probabilities for Disentangling Brand-Customer Interactions
Dec 08, 2020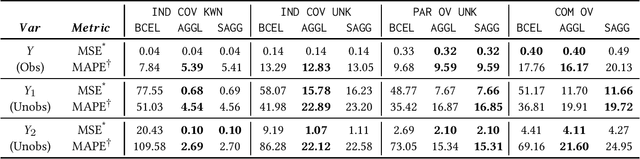
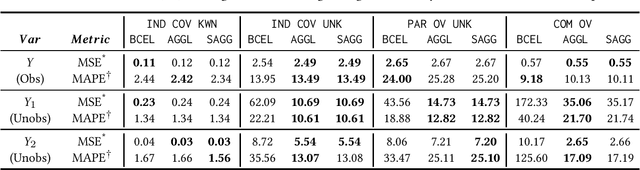

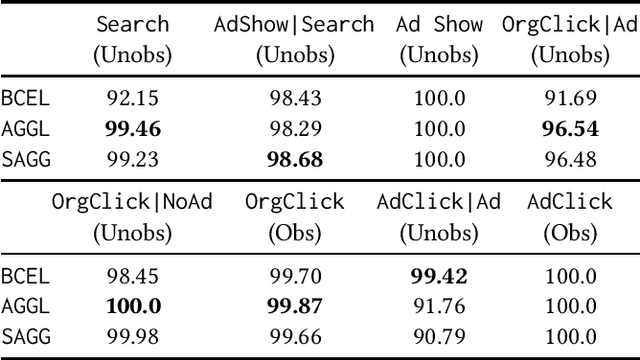
Often, data contains only composite events composed of multiple events, some observed and some unobserved. For example, search ad click is observed by a brand, whereas which customers were shown a search ad - an actionable variable - is often not observed. In such cases, inference is not possible on unobserved event. This occurs when a marketing action is taken over earned and paid digital channels. Similar setting arises in numerous datasets where multiple actors interact. One approach is to use the composite event as a proxy for the unobserved event of interest. However, this leads to invalid inference. This paper takes a direct approach whereby an event of interest is identified based on information on the composite event and aggregate data on composite events (e.g. total number of search ads shown). This work contributes to the literature by proving identification of the unobserved events' probabilities up to a scalar factor under mild condition. We propose an approach to identify the scalar factor by using aggregate data that is usually available from earned and paid channels. The factor is identified by adding a loss term to the usual cross-entropy loss. We validate the approach on three synthetic datasets. In addition, the approach is validated on a real marketing problem where some observed events are hidden from the algorithm for validation. The proposed modification to the cross-entropy loss function improves the average performance by 46%.
Dis-entangling Mixture of Interventions on a Causal Bayesian Network Using Aggregate Observations
Jan 15, 2020
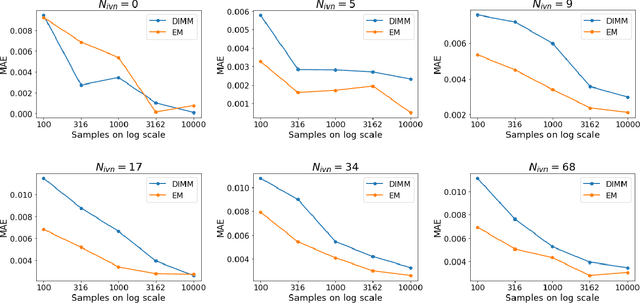
We study the problem of separating a mixture of distributions, all of which come from interventions on a known causal bayesian network. Given oracle access to marginals of all distributions resulting from interventions on the network, and estimates of marginals from the mixture distribution, we want to recover the mixing proportions of different mixture components. We show that in the worst case, mixing proportions cannot be identified using marginals only. If exact marginals of the mixture distribution were known, under a simple assumption of excluding a few distributions from the mixture, we show that the mixing proportions become identifiable. Our identifiability proof is constructive and gives an efficient algorithm recovering the mixing proportions exactly. When exact marginals are not available, we design an optimization framework to estimate the mixing proportions. Our problem is motivated from a real-world scenario of an e-commerce business, where multiple interventions occur at a given time, leading to deviations in expected metrics. We conduct experiments on the well known publicly available ALARM network and on a proprietary dataset from a large e-commerce company validating the performance of our method.