 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis on Image Set Visual Question Answering
Mar 31, 2021
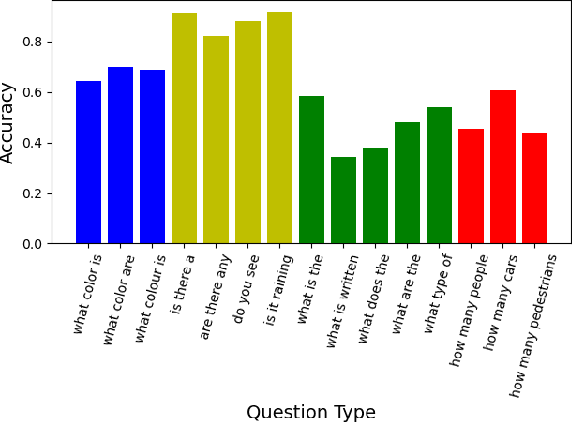
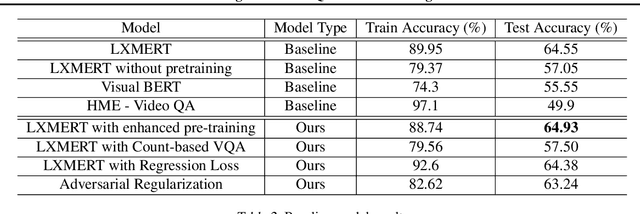

We tackle the challenge of Visual Question Answering in multi-image setting for the ISVQA dataset. Traditional VQA tasks have focused on a single-image setting where the target answer is generated from a single image. Image set VQA, however, comprises of a set of images and requires finding connection between images, relate the objects across images based on these connections and generate a unified answer. In this report, we work with 4 approaches in a bid to improve the performance on the task. We analyse and compare our results with three baseline models - LXMERT, HME-VideoQA and VisualBERT - and show that our approaches can provide a slight improvement over the baselines. In specific, we try to improve on the spatial awareness of the model and help the model identify color using enhanced pre-training, reduce language dependence using adversarial regularization, and improve counting using regression loss and graph based deduplication. We further delve into an in-depth analysis on the language bias in the ISVQA dataset and show how models trained on ISVQA implicitly learn to associate language more strongly with the final answer.
Lexically-constrained Text Generation through Commonsense Knowledge Extraction and Injection
Dec 19, 2020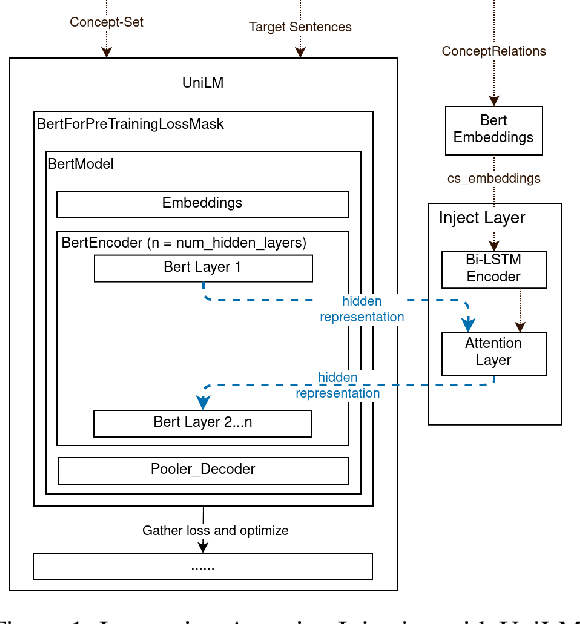


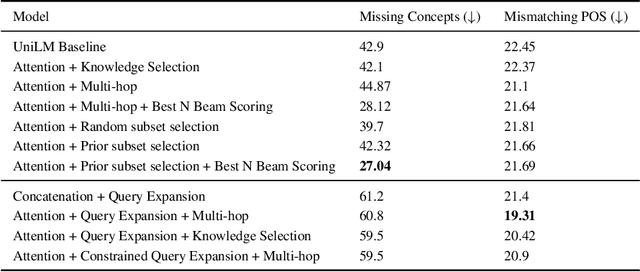
Conditional text generation has been a challenging task that is yet to see human-level performance from state-of-the-art models. In this work, we specifically focus on the Commongen benchmark, wherein the aim is to generate a plausible sentence for a given set of input concepts. Despite advances in other tasks, large pre-trained language models that are fine-tuned on this dataset often produce sentences that are syntactically correct but qualitatively deviate from a human understanding of common sense. Furthermore, generated sequences are unable to fulfill such lexical requirements as matching part-of-speech and full concept coverage. In this paper, we explore how commonsense knowledge graphs can enhance model performance, with respect to commonsense reasoning and lexically-constrained decoding. We propose strategies for enhancing the semantic correctness of the generated text, which we accomplish through: extracting commonsense relations from Conceptnet, injecting these relations into the Unified Language Model (UniLM) through attention mechanisms, and enforcing the aforementioned lexical requirements through output constraints. By performing several ablations, we find that commonsense injection enables the generation of sentences that are more aligned with human understanding, while remaining compliant with lexical requirements.
Dis-entangling Mixture of Interventions on a Causal Bayesian Network Using Aggregate Observations
Jan 15, 2020
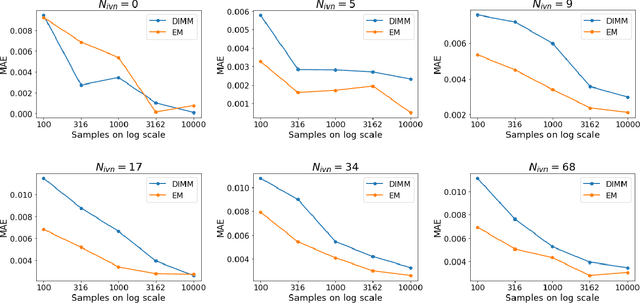
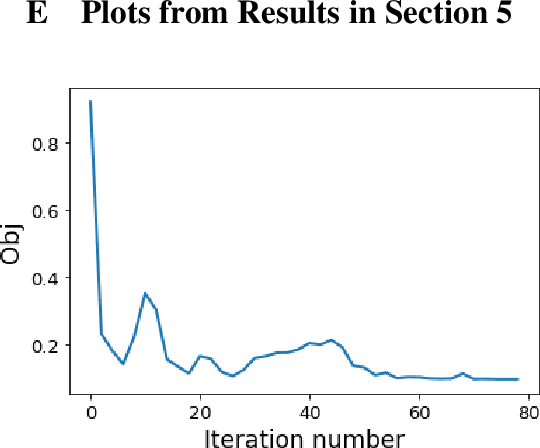
We study the problem of separating a mixture of distributions, all of which come from interventions on a known causal bayesian network. Given oracle access to marginals of all distributions resulting from interventions on the network, and estimates of marginals from the mixture distribution, we want to recover the mixing proportions of different mixture components. We show that in the worst case, mixing proportions cannot be identified using marginals only. If exact marginals of the mixture distribution were known, under a simple assumption of excluding a few distributions from the mixture, we show that the mixing proportions become identifiable. Our identifiability proof is constructive and gives an efficient algorithm recovering the mixing proportions exactly. When exact marginals are not available, we design an optimization framework to estimate the mixing proportions. Our problem is motivated from a real-world scenario of an e-commerce business, where multiple interventions occur at a given time, leading to deviations in expected metrics. We conduct experiments on the well known publicly available ALARM network and on a proprietary dataset from a large e-commerce company validating the performance of our method.