 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnconstrained Face Recognition using ASURF and Cloud-Forest Classifier optimized with VLAD
Apr 02, 2021



The paper posits a computationally-efficient algorithm for multi-class facial image classification in which images are constrained with translation, rotation, scale, color, illumination and affine distortion. The proposed method is divided into five main building blocks including Haar-Cascade for face detection, Bilateral Filter for image preprocessing to remove unwanted noise, Affine Speeded-Up Robust Features (ASURF) for keypoint detection and description, Vector of Locally Aggregated Descriptors (VLAD) for feature quantization and Cloud Forest for image classification. The proposed method aims at improving the accuracy and the time taken for face recognition systems. The usage of the Cloud Forest algorithm as a classifier on three benchmark datasets, namely the FACES95, FACES96 and ORL facial datasets, showed promising results. The proposed methodology using Cloud Forest algorithm successfully improves the recognition model by 2-12\% when differentiated against other ensemble techniques like the Random Forest classifier depending upon the dataset used.
* 8 Pages, 3 Figures
Analysis on Image Set Visual Question Answering
Mar 31, 2021
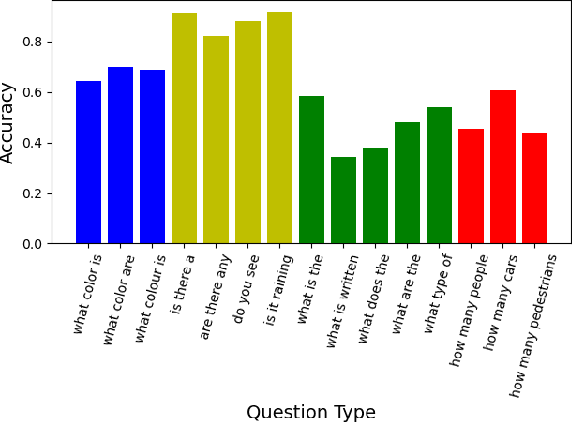
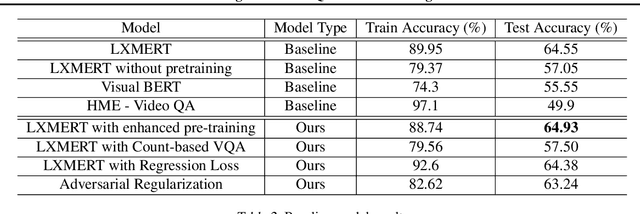

We tackle the challenge of Visual Question Answering in multi-image setting for the ISVQA dataset. Traditional VQA tasks have focused on a single-image setting where the target answer is generated from a single image. Image set VQA, however, comprises of a set of images and requires finding connection between images, relate the objects across images based on these connections and generate a unified answer. In this report, we work with 4 approaches in a bid to improve the performance on the task. We analyse and compare our results with three baseline models - LXMERT, HME-VideoQA and VisualBERT - and show that our approaches can provide a slight improvement over the baselines. In specific, we try to improve on the spatial awareness of the model and help the model identify color using enhanced pre-training, reduce language dependence using adversarial regularization, and improve counting using regression loss and graph based deduplication. We further delve into an in-depth analysis on the language bias in the ISVQA dataset and show how models trained on ISVQA implicitly learn to associate language more strongly with the final answer.
Zero-Shot Language Transfer vs Iterative Back Translation for Unsupervised Machine Translation
Mar 31, 2021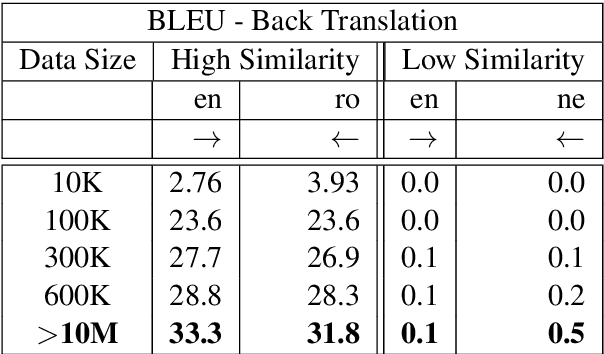

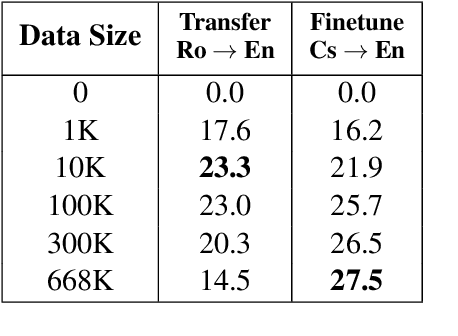
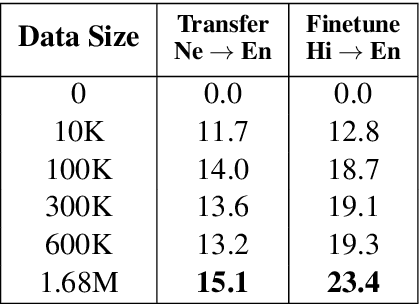
This work focuses on comparing different solutions for machine translation on low resource language pairs, namely, with zero-shot transfer learning and unsupervised machine translation. We discuss how the data size affects the performance of both unsupervised MT and transfer learning. Additionally we also look at how the domain of the data affects the result of unsupervised MT. The code to all the experiments performed in this project are accessible on Github.