 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ensemble Approach to Music Source Separation: A Comparative Analysis of Conventional and Hierarchical Stem Separation
Oct 28, 2024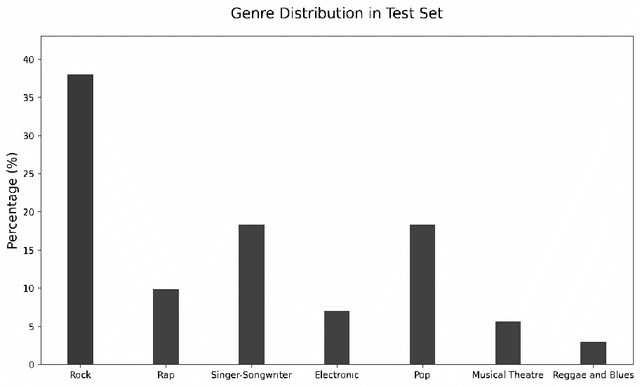

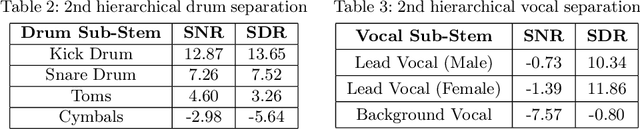
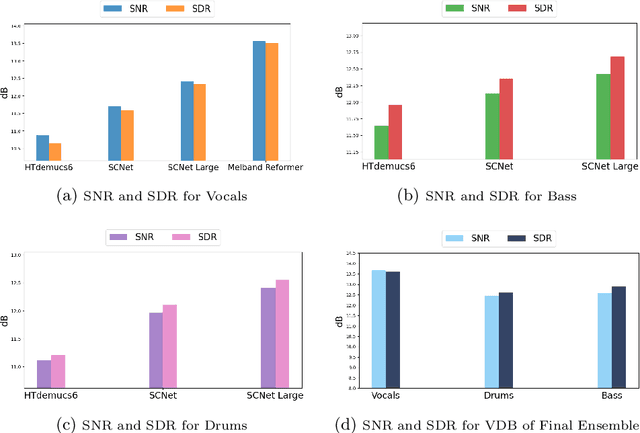
Music source separation (MSS) is a task that involves isolating individual sound sources, or stems, from mixed audio signals. This paper presents an ensemble approach to MSS, combining several state-of-the-art architectures to achieve superior separation performance across traditional Vocal, Drum, and Bass (VDB) stems, as well as expanding into second-level hierarchical separation for sub-stems like kick, snare, lead vocals, and background vocals. Our method addresses the limitations of relying on a single model by utilising the complementary strengths of various models, leading to more balanced results across stems. For stem selection, we used the harmonic mean of Signal-to-Noise Ratio (SNR) and Signal-to-Distortion Ratio (SDR), ensuring that extreme values do not skew the results and that both metrics are weighted effectively. In addition to consistently high performance across the VDB stems, we also explored second-level hierarchical separation, revealing important insights into the complexities of MSS and how factors like genre and instrumentation can influence model performance. While the second-level separation results show room for improvement, the ability to isolate sub-stems marks a significant advancement. Our findings pave the way for further research in MSS, particularly in expanding model capabilities beyond VDB and improving niche stem separations such as guitar and piano.
A Comparative Study of Algorithms for Intelligent Traffic Signal Control
Sep 18, 2021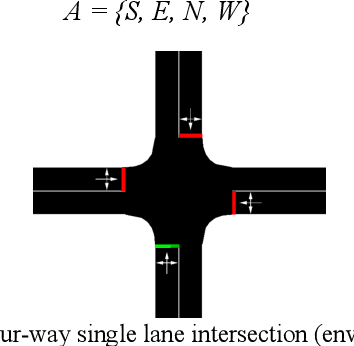
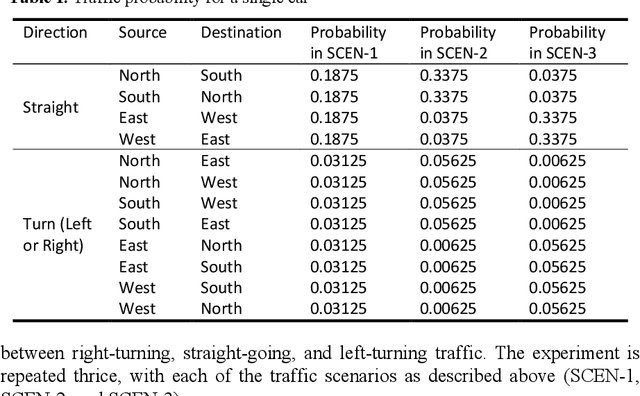
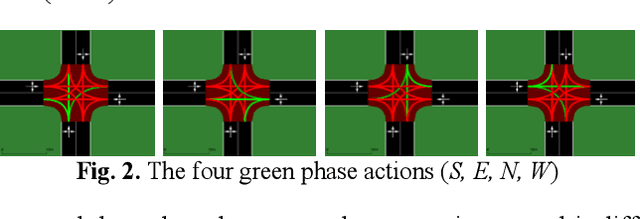
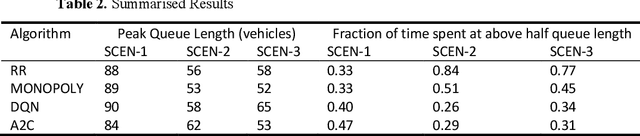
In this paper, methods have been explored to effectively optimise traffic signal control to minimise waiting times and queue lengths, thereby increasing traffic flow. The traffic intersection was first defined as a Markov Decision Process, and a state representation, actions and rewards were chosen. Simulation of Urban MObility (SUMO) was used to simulate an intersection and then compare a Round Robin Scheduler, a Feedback Control mechanism and two Reinforcement Learning techniques - Deep Q Network (DQN) and Advantage Actor-Critic (A2C), as the policy for the traffic signal in the simulation under different scenarios. Finally, the methods were tested on a simulation of a real-world intersection in Bengaluru, India.
Speech Denoising without Clean Training Data: a Noise2Noise Approach
Apr 08, 2021
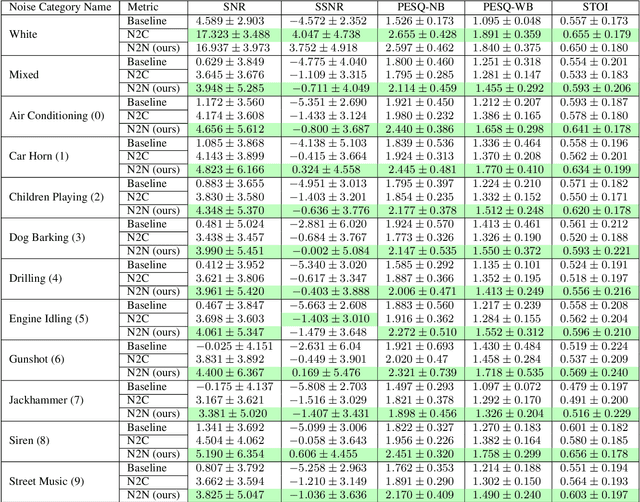
This paper tackles the problem of the heavy dependence of clean speech data required by deep learning based audio-denoising methods by showing that it is possible to train deep speech denoising networks using only noisy speech samples. Conventional wisdom dictates that in order to achieve good speech denoising performance, there is a requirement for a large quantity of both noisy speech samples and perfectly clean speech samples, resulting in a need for expensive audio recording equipment and extremely controlled soundproof recording studios. These requirements pose significant challenges in data collection, especially in economically disadvantaged regions and for low resource languages. This work shows that speech denoising deep neural networks can be successfully trained utilizing only noisy training audio. Furthermore it is revealed that such training regimes achieve superior denoising performance over conventional training regimes utilizing clean training audio targets, in cases involving complex noise distributions and low Signal-to-Noise ratios (high noise environments). This is demonstrated through experiments studying the efficacy of our proposed approach over both real-world noises and synthetic noises using the 20 layered Deep Complex U-Net architecture.
Unconstrained Face Recognition using ASURF and Cloud-Forest Classifier optimized with VLAD
Apr 02, 2021



The paper posits a computationally-efficient algorithm for multi-class facial image classification in which images are constrained with translation, rotation, scale, color, illumination and affine distortion. The proposed method is divided into five main building blocks including Haar-Cascade for face detection, Bilateral Filter for image preprocessing to remove unwanted noise, Affine Speeded-Up Robust Features (ASURF) for keypoint detection and description, Vector of Locally Aggregated Descriptors (VLAD) for feature quantization and Cloud Forest for image classification. The proposed method aims at improving the accuracy and the time taken for face recognition systems. The usage of the Cloud Forest algorithm as a classifier on three benchmark datasets, namely the FACES95, FACES96 and ORL facial datasets, showed promising results. The proposed methodology using Cloud Forest algorithm successfully improves the recognition model by 2-12\% when differentiated against other ensemble techniques like the Random Forest classifier depending upon the dataset used.
* 8 Pages, 3 Figures
Optimization of Image Embeddings for Few Shot Learning
Apr 04, 2020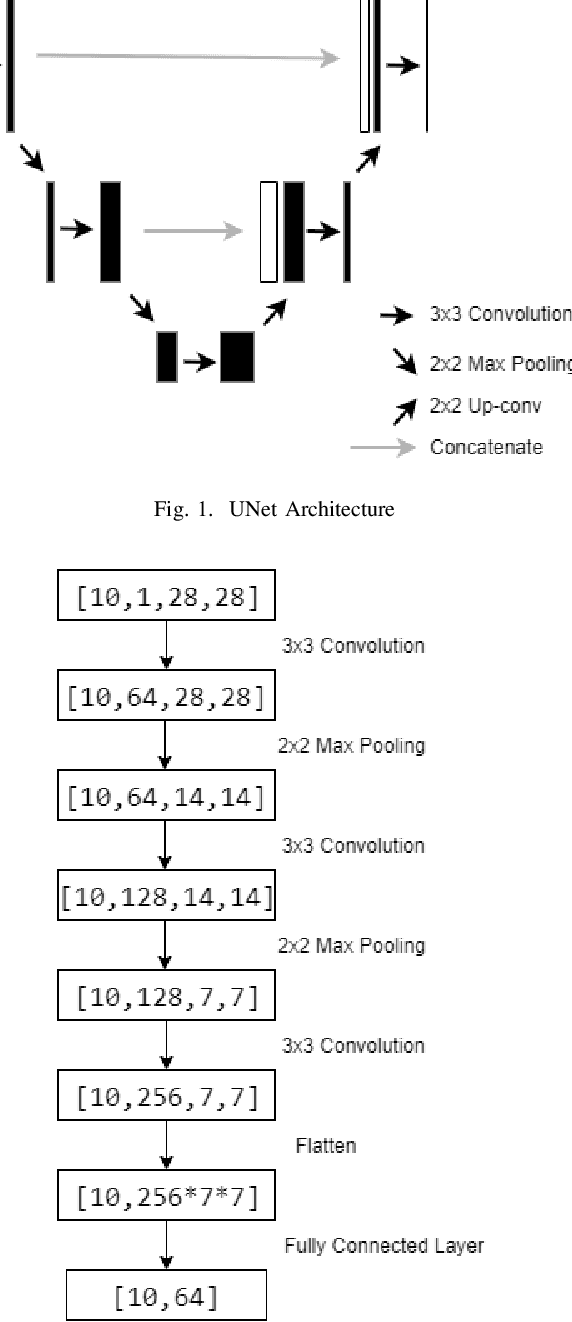
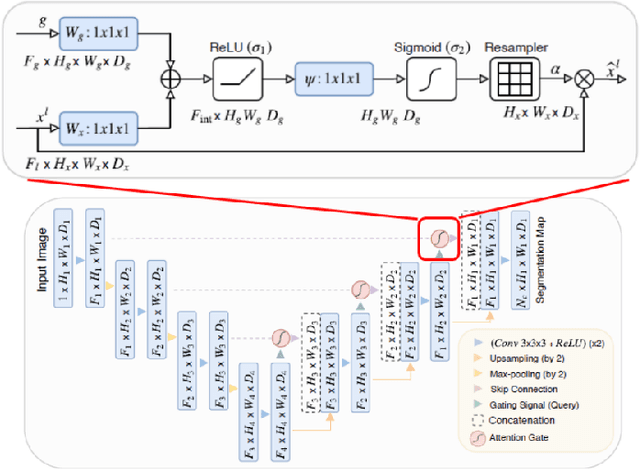
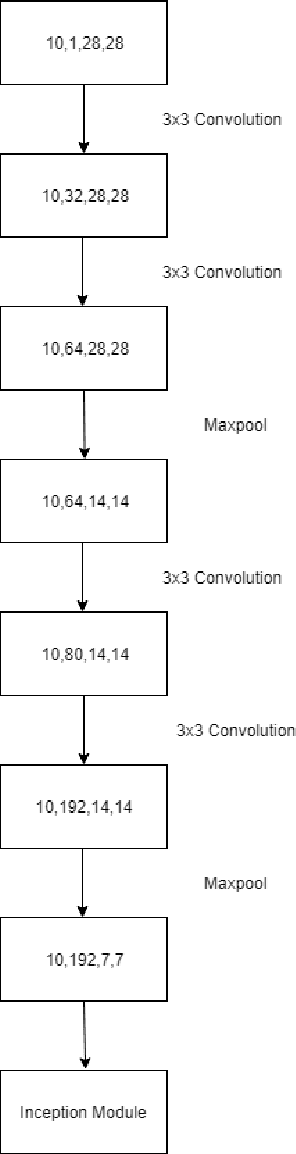
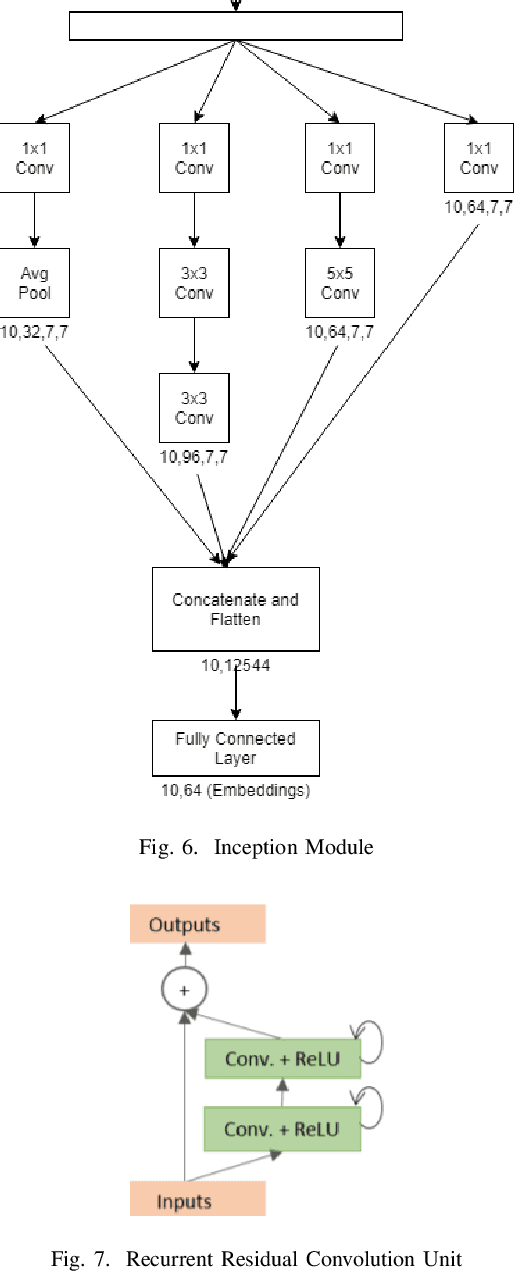
In this paper we improve the image embeddings generated in the graph neural network solution for few shot learning. We propose alternate architectures for existing networks such as Inception-Net, U-Net, Attention U-Net, and Squeeze-Net to generate embeddings and increase the accuracy of the models. We improve the quality of embeddings created at the cost of the time taken to generate them. The proposed implementations outperform the existing state of the art methods for 1-shot and 5-shot learning on the Omniglot dataset. The experiments involved a testing set and training set which had no common classes between them. The results for 5-way and 10-way/20-way tests have been tabulated.