 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ensemble Approach to Music Source Separation: A Comparative Analysis of Conventional and Hierarchical Stem Separation
Oct 28, 2024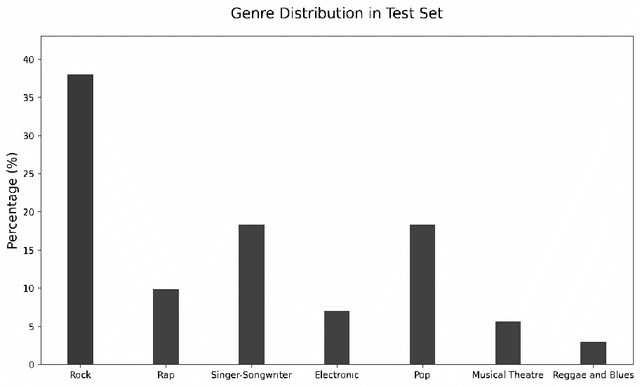

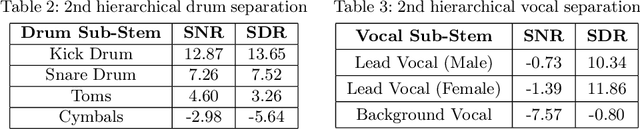
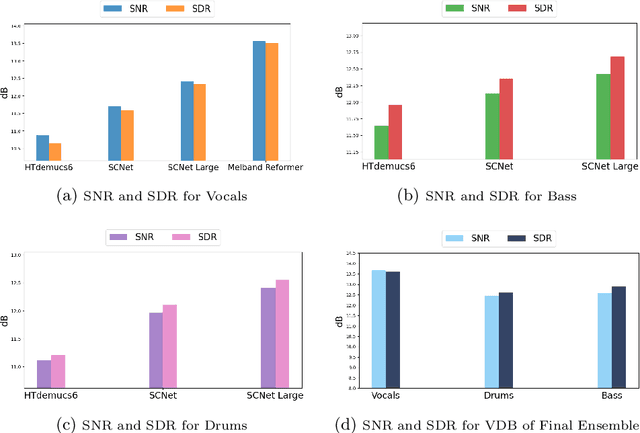
Music source separation (MSS) is a task that involves isolating individual sound sources, or stems, from mixed audio signals. This paper presents an ensemble approach to MSS, combining several state-of-the-art architectures to achieve superior separation performance across traditional Vocal, Drum, and Bass (VDB) stems, as well as expanding into second-level hierarchical separation for sub-stems like kick, snare, lead vocals, and background vocals. Our method addresses the limitations of relying on a single model by utilising the complementary strengths of various models, leading to more balanced results across stems. For stem selection, we used the harmonic mean of Signal-to-Noise Ratio (SNR) and Signal-to-Distortion Ratio (SDR), ensuring that extreme values do not skew the results and that both metrics are weighted effectively. In addition to consistently high performance across the VDB stems, we also explored second-level hierarchical separation, revealing important insights into the complexities of MSS and how factors like genre and instrumentation can influence model performance. While the second-level separation results show room for improvement, the ability to isolate sub-stems marks a significant advancement. Our findings pave the way for further research in MSS, particularly in expanding model capabilities beyond VDB and improving niche stem separations such as guitar and piano.