 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Antiwork: A RoBERTa-Based System for Work-Related Stress Identification and Leading Factor Analysis
Aug 24, 2024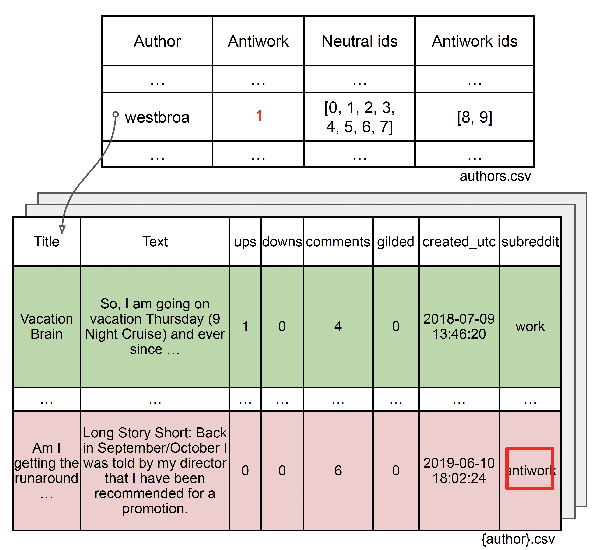

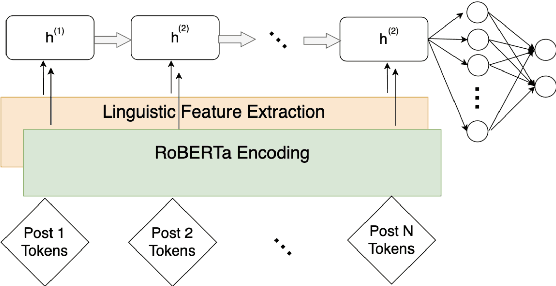

Harsh working environments and work-related stress have been known to contribute to mental health problems such as anxiety, depression, and suicidal ideation. As such, it is paramount to create solutions that can both detect employee unhappiness and find the root cause of the problem. While prior works have examined causes of mental health using machine learning, they typically focus on general mental health analysis, with few of them focusing on explainable solutions or looking at the workplace-specific setting. r/antiwork is a subreddit for the antiwork movement, which is the desire to stop working altogether. Using this subreddit as a proxy for work environment dissatisfaction, we create a new dataset for antiwork sentiment detection and subsequently train a model that highlights the words with antiwork sentiments. Following this, we performed a qualitative and quantitative analysis to uncover some of the key insights into the mindset of individuals who identify with the antiwork movement and how their working environments influenced them. We find that working environments that do not give employees authority or responsibility, frustrating recruiting experiences, and unfair compensation, are some of the leading causes of the antiwork sentiment, resulting in a lack of self-confidence and motivation among their employees.
Few-Shot Batch Incremental Road Object Detection via Detector Fusion
Aug 18, 2021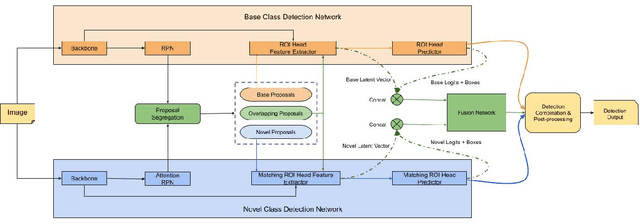


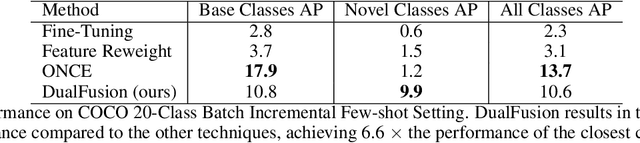
Incremental few-shot learning has emerged as a new and challenging area in deep learning, whose objective is to train deep learning models using very few samples of new class data, and none of the old class data. In this work we tackle the problem of batch incremental few-shot road object detection using data from the India Driving Dataset (IDD). Our approach, DualFusion, combines object detectors in a manner that allows us to learn to detect rare objects with very limited data, all without severely degrading the performance of the detector on the abundant classes. In the IDD OpenSet incremental few-shot detection task, we achieve a mAP50 score of 40.0 on the base classes and an overall mAP50 score of 38.8, both of which are the highest to date. In the COCO batch incremental few-shot detection task, we achieve a novel AP score of 9.9, surpassing the state-of-the-art novel class performance on the same by over 6.6 times.
Speech Denoising without Clean Training Data: a Noise2Noise Approach
Apr 08, 2021
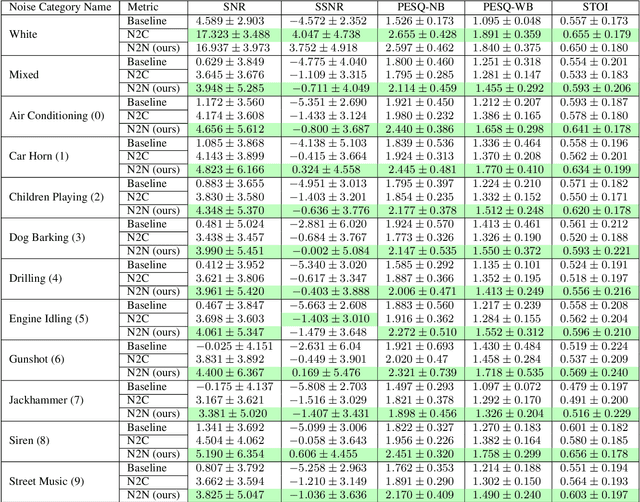
This paper tackles the problem of the heavy dependence of clean speech data required by deep learning based audio-denoising methods by showing that it is possible to train deep speech denoising networks using only noisy speech samples. Conventional wisdom dictates that in order to achieve good speech denoising performance, there is a requirement for a large quantity of both noisy speech samples and perfectly clean speech samples, resulting in a need for expensive audio recording equipment and extremely controlled soundproof recording studios. These requirements pose significant challenges in data collection, especially in economically disadvantaged regions and for low resource languages. This work shows that speech denoising deep neural networks can be successfully trained utilizing only noisy training audio. Furthermore it is revealed that such training regimes achieve superior denoising performance over conventional training regimes utilizing clean training audio targets, in cases involving complex noise distributions and low Signal-to-Noise ratios (high noise environments). This is demonstrated through experiments studying the efficacy of our proposed approach over both real-world noises and synthetic noises using the 20 layered Deep Complex U-Net architecture.
Estimation and Applications of Quantiles in Deep Binary Classification
Feb 09, 2021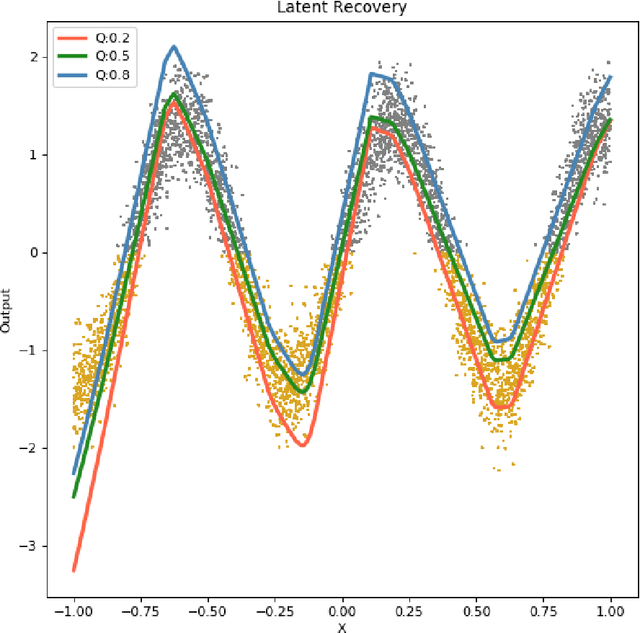
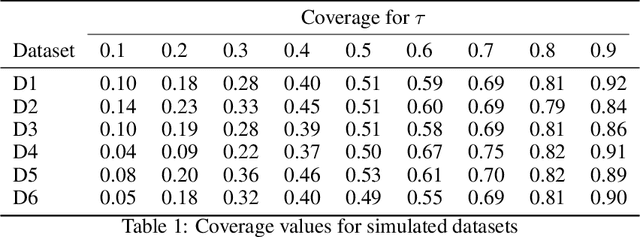
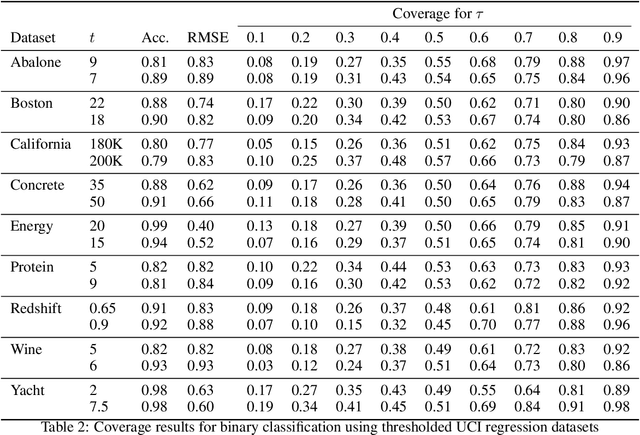
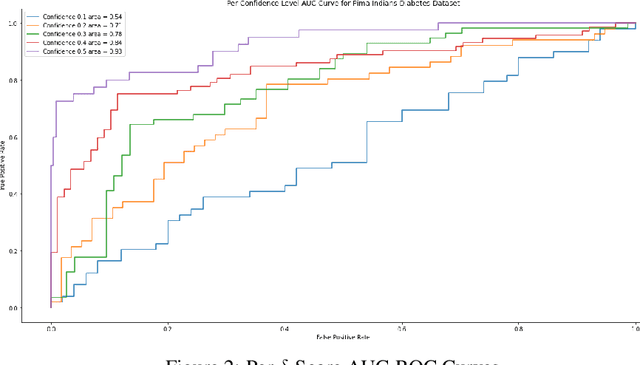
Quantile regression, based on check loss, is a widely used inferential paradigm in Econometrics and Statistics. The conditional quantiles provide a robust alternative to classical conditional means, and also allow uncertainty quantification of the predictions, while making very few distributional assumptions. We consider the analogue of check loss in the binary classification setting. We assume that the conditional quantiles are smooth functions that can be learnt by Deep Neural Networks (DNNs). Subsequently, we compute the Lipschitz constant of the proposed loss, and also show that its curvature is bounded, under some regularity conditions. Consequently, recent results on the error rates and DNN architecture complexity become directly applicable. We quantify the uncertainty of the class probabilities in terms of prediction intervals, and develop individualized confidence scores that can be used to decide whether a prediction is reliable or not at scoring time. By aggregating the confidence scores at the dataset level, we provide two additional metrics, model confidence, and retention rate, to complement the widely used classifier summaries. We also the robustness of the proposed non-parametric binary quantile classification framework are also studied, and we demonstrate how to obtain several univariate summary statistics of the conditional distributions, in particular conditional means, using smoothed conditional quantiles, allowing the use of explanation techniques like Shapley to explain the mean predictions. Finally, we demonstrate an efficient training regime for this loss based on Stochastic Gradient Descent with Lipschitz Adaptive Learning Rates (LALR).