 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHaSaM: Submodular Hard Sample Mining for Fair Facial Attribute Recognition
Feb 05, 2026Deep neural networks often inherit social and demographic biases from annotated data during model training, leading to unfair predictions, especially in the presence of sensitive attributes like race, age, gender etc. Existing methods fall prey to the inherent data imbalance between attribute groups and inadvertently emphasize on sensitive attributes, worsening unfairness and performance. To surmount these challenges, we propose SHaSaM (Submodular Hard Sample Mining), a novel combinatorial approach that models fairness-driven representation learning as a submodular hard-sample mining problem. Our two-stage approach comprises of SHaSaM-MINE, which introduces a submodular subset selection strategy to mine hard positives and negatives - effectively mitigating data imbalance, and SHaSaM-LEARN, which introduces a family of combinatorial loss functions based on Submodular Conditional Mutual Information to maximize the decision boundary between target classes while minimizing the influence of sensitive attributes. This unified formulation restricts the model from learning features tied to sensitive attributes, significantly enhancing fairness without sacrificing performance. Experiments on CelebA and UTKFace demonstrate that SHaSaM achieves state-of-the-art results, with up to 2.7 points improvement in model fairness (Equalized Odds) and a 3.5% gain in Accuracy, within fewer epochs as compared to existing methods.
InSQuAD: In-Context Learning for Efficient Retrieval via Submodular Mutual Information to Enforce Quality and Diversity
Aug 28, 2025In this paper, we introduce InSQuAD, designed to enhance the performance of In-Context Learning (ICL) models through Submodular Mutual Information} (SMI) enforcing Quality and Diversity among in-context exemplars. InSQuAD achieves this through two principal strategies: First, we model the ICL task as a targeted selection problem and introduce a unified selection strategy based on SMIs which mines relevant yet diverse in-context examples encapsulating the notions of quality and diversity. Secondly, we address a common pitfall in existing retrieval models which model query relevance, often overlooking diversity, critical for ICL. InSQuAD introduces a combinatorial training paradigm which learns the parameters of an SMI function to enforce both quality and diversity in the retrieval model through a novel likelihood-based loss. To further aid the learning process we augment an existing multi-hop question answering dataset with synthetically generated paraphrases. Adopting the retrieval model trained using this strategy alongside the novel targeted selection formulation for ICL on nine benchmark datasets shows significant improvements validating the efficacy of our approach.
TabGLM: Tabular Graph Language Model for Learning Transferable Representations Through Multi-Modal Consistency Minimization
Feb 26, 2025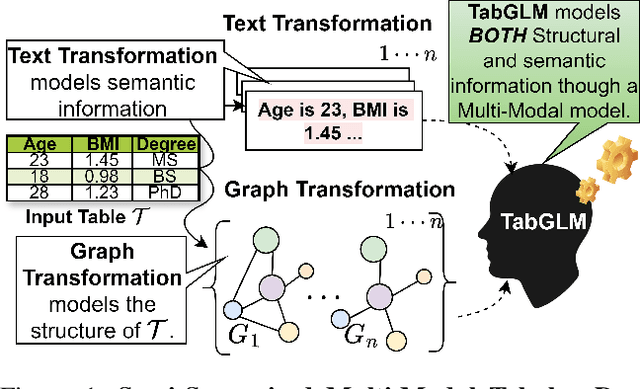
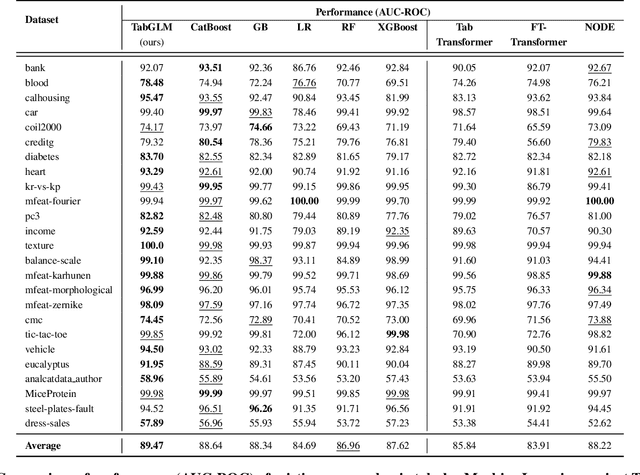
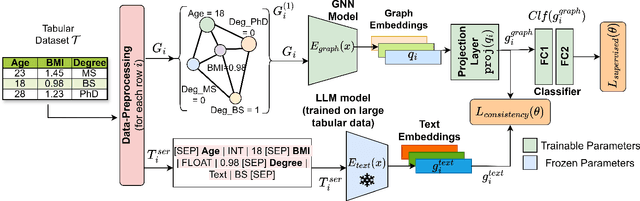
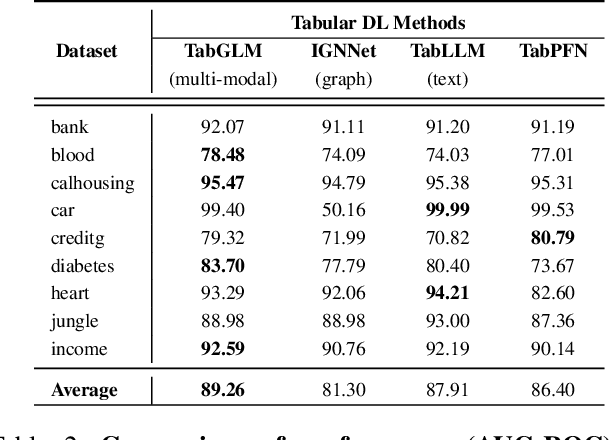
Handling heterogeneous data in tabular datasets poses a significant challenge for deep learning models. While attention-based architectures and self-supervised learning have achieved notable success, their application to tabular data remains less effective over linear and tree based models. Although several breakthroughs have been achieved by models which transform tables into uni-modal transformations like image, language and graph, these models often underperform in the presence of feature heterogeneity. To address this gap, we introduce TabGLM (Tabular Graph Language Model), a novel multi-modal architecture designed to model both structural and semantic information from a table. TabGLM transforms each row of a table into a fully connected graph and serialized text, which are then encoded using a graph neural network (GNN) and a text encoder, respectively. By aligning these representations through a joint, multi-modal, self-supervised learning objective, TabGLM leverages complementary information from both modalities, thereby enhancing feature learning. TabGLM's flexible graph-text pipeline efficiently processes heterogeneous datasets with significantly fewer parameters over existing Deep Learning approaches. Evaluations across 25 benchmark datasets demonstrate substantial performance gains, with TabGLM achieving an average AUC-ROC improvement of up to 5.56% over State-of-the-Art (SoTA) tabular learning methods.
SMILe: Leveraging Submodular Mutual Information For Robust Few-Shot Object Detection
Jul 02, 2024Confusion and forgetting of object classes have been challenges of prime interest in Few-Shot Object Detection (FSOD). To overcome these pitfalls in metric learning based FSOD techniques, we introduce a novel Submodular Mutual Information Learning (SMILe) framework which adopts combinatorial mutual information functions to enforce the creation of tighter and discriminative feature clusters in FSOD. Our proposed approach generalizes to several existing approaches in FSOD, agnostic of the backbone architecture demonstrating elevated performance gains. A paradigm shift from instance based objective functions to combinatorial objectives in SMILe naturally preserves the diversity within an object class resulting in reduced forgetting when subjected to few training examples. Furthermore, the application of mutual information between the already learnt (base) and newly added (novel) objects ensures sufficient separation between base and novel classes, minimizing the effect of class confusion. Experiments on popular FSOD benchmarks, PASCAL-VOC and MS-COCO show that our approach generalizes to State-of-the-Art (SoTA) approaches improving their novel class performance by up to 5.7% (3.3 mAP points) and 5.4% (2.6 mAP points) on the 10-shot setting of VOC (split 3) and 30-shot setting of COCO datasets respectively. Our experiments also demonstrate better retention of base class performance and up to 2x faster convergence over existing approaches agnostic of the underlying architecture.
SCoRe: Submodular Combinatorial Representation Learning for Real-World Class-Imbalanced Settings
Sep 29, 2023



Representation Learning in real-world class-imbalanced settings has emerged as a challenging task in the evolution of deep learning. Lack of diversity in visual and structural features for rare classes restricts modern neural networks to learn discriminative feature clusters. This manifests in the form of large inter-class bias between rare object classes and elevated intra-class variance among abundant classes in the dataset. Although deep metric learning approaches have shown promise in this domain, significant improvements need to be made to overcome the challenges associated with class-imbalance in mission critical tasks like autonomous navigation and medical diagnostics. Set-based combinatorial functions like Submodular Information Measures exhibit properties that allow them to simultaneously model diversity and cooperation among feature clusters. In this paper, we introduce the SCoRe (Submodular Combinatorial Representation Learning) framework and propose a family of Submodular Combinatorial Loss functions to overcome these pitfalls in contrastive learning. We also show that existing contrastive learning approaches are either submodular or can be re-formulated to create their submodular counterparts. We conduct experiments on the newly introduced family of combinatorial objectives on two image classification benchmarks - pathologically imbalanced CIFAR-10, subsets of MedMNIST and a real-world road object detection benchmark - India Driving Dataset (IDD). Our experiments clearly show that the newly introduced objectives like Facility Location, Graph-Cut and Log Determinant outperform state-of-the-art metric learners by up to 7.6% for the imbalanced classification tasks and up to 19.4% for object detection tasks.
Attention Guided Cosine Margin For Overcoming Class-Imbalance in Few-Shot Road Object Detection
Nov 12, 2021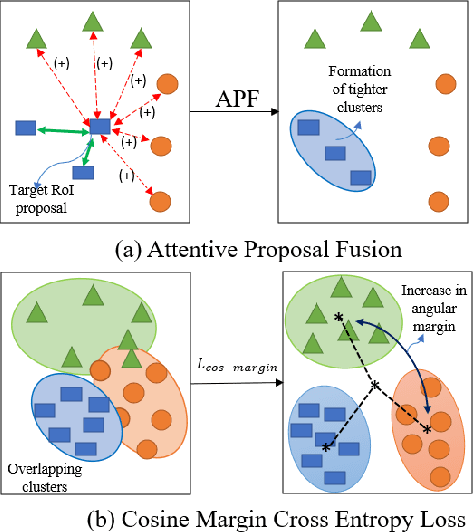
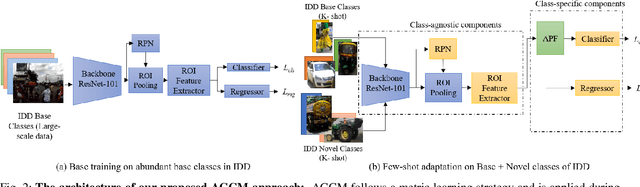
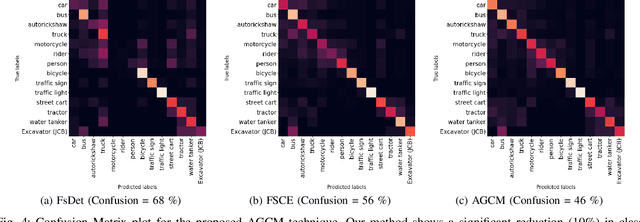
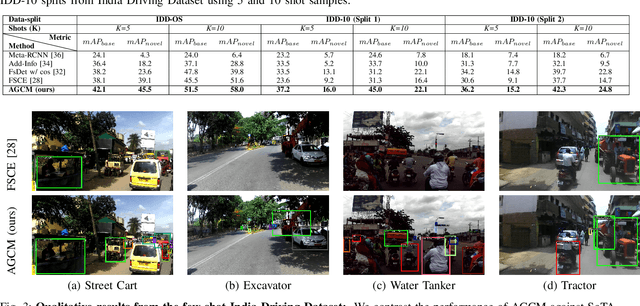
Few-shot object detection (FSOD) localizes and classifies objects in an image given only a few data samples. Recent trends in FSOD research show the adoption of metric and meta-learning techniques, which are prone to catastrophic forgetting and class confusion. To overcome these pitfalls in metric learning based FSOD techniques, we introduce Attention Guided Cosine Margin (AGCM) that facilitates the creation of tighter and well separated class-specific feature clusters in the classification head of the object detector. Our novel Attentive Proposal Fusion (APF) module minimizes catastrophic forgetting by reducing the intra-class variance among co-occurring classes. At the same time, the proposed Cosine Margin Cross-Entropy loss increases the angular margin between confusing classes to overcome the challenge of class confusion between already learned (base) and newly added (novel) classes. We conduct our experiments on the challenging India Driving Dataset (IDD), which presents a real-world class-imbalanced setting alongside popular FSOD benchmark PASCAL-VOC. Our method outperforms State-of-the-Art (SoTA) approaches by up to 6.4 mAP points on the IDD-OS and up to 2.0 mAP points on the IDD-10 splits for the 10-shot setting. On the PASCAL-VOC dataset, we outperform existing SoTA approaches by up to 4.9 mAP points.
Meta Guided Metric Learner for Overcoming Class Confusion in Few-Shot Road Object Detection
Oct 28, 2021
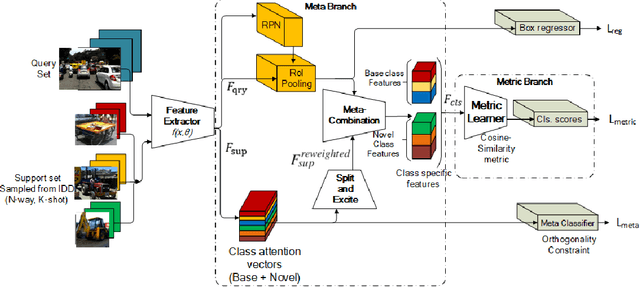
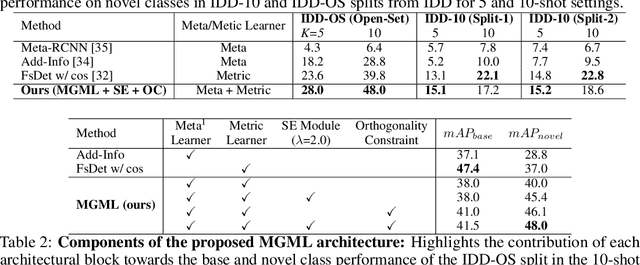

Localization and recognition of less-occurring road objects have been a challenge in autonomous driving applications due to the scarcity of data samples. Few-Shot Object Detection techniques extend the knowledge from existing base object classes to learn novel road objects given few training examples. Popular techniques in FSOD adopt either meta or metric learning techniques which are prone to class confusion and base class forgetting. In this work, we introduce a novel Meta Guided Metric Learner (MGML) to overcome class confusion in FSOD. We re-weight the features of the novel classes higher than the base classes through a novel Squeeze and Excite module and encourage the learning of truly discriminative class-specific features by applying an Orthogonality Constraint to the meta learner. Our method outperforms State-of-the-Art (SoTA) approaches in FSOD on the India Driving Dataset (IDD) by upto 11 mAP points while suffering from the least class confusion of 20% given only 10 examples of each novel road object. We further show similar improvements on the few-shot splits of PASCAL VOC dataset where we outperform SoTA approaches by upto 5.8 mAP accross all splits.
Few-Shot Batch Incremental Road Object Detection via Detector Fusion
Aug 18, 2021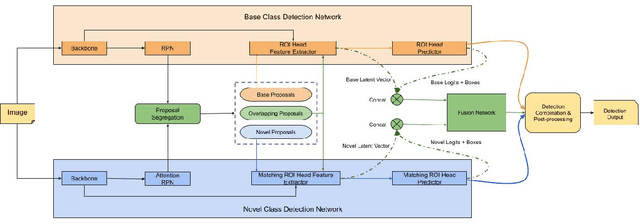


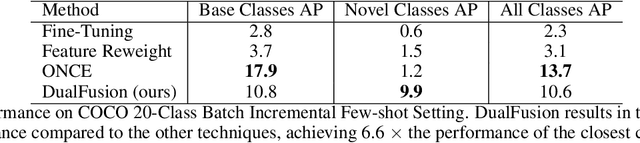
Incremental few-shot learning has emerged as a new and challenging area in deep learning, whose objective is to train deep learning models using very few samples of new class data, and none of the old class data. In this work we tackle the problem of batch incremental few-shot road object detection using data from the India Driving Dataset (IDD). Our approach, DualFusion, combines object detectors in a manner that allows us to learn to detect rare objects with very limited data, all without severely degrading the performance of the detector on the abundant classes. In the IDD OpenSet incremental few-shot detection task, we achieve a mAP50 score of 40.0 on the base classes and an overall mAP50 score of 38.8, both of which are the highest to date. In the COCO batch incremental few-shot detection task, we achieve a novel AP score of 9.9, surpassing the state-of-the-art novel class performance on the same by over 6.6 times.
Few-Shot Learning for Road Object Detection
Jan 29, 2021



Few-shot learning is a problem of high interest in the evolution of deep learning. In this work, we consider the problem of few-shot object detection (FSOD) in a real-world, class-imbalanced scenario. For our experiments, we utilize the India Driving Dataset (IDD), as it includes a class of less-occurring road objects in the image dataset and hence provides a setup suitable for few-shot learning. We evaluate both metric-learning and meta-learning based FSOD methods, in two experimental settings: (i) representative (same-domain) splits from IDD, that evaluates the ability of a model to learn in the context of road images, and (ii) object classes with less-occurring object samples, similar to the open-set setting in real-world. From our experiments, we demonstrate that the metric-learning method outperforms meta-learning on the novel classes by (i) 11.2 mAP points on the same domain, and (ii) 1.0 mAP point on the open-set. We also show that our extension of object classes in a real-world open dataset offers a rich ground for few-shot learning studies.