 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Classification of Infrequent Labels by Reducing Variability in Label Distribution
Nov 07, 2025This paper presents a novel solution, LEVER, designed to address the challenges posed by underperforming infrequent categories in Extreme Classification (XC) tasks. Infrequent categories, often characterized by sparse samples, suffer from high label inconsistency, which undermines classification performance. LEVER mitigates this problem by adopting a robust Siamese-style architecture, leveraging knowledge transfer to reduce label inconsistency and enhance the performance of One-vs-All classifiers. Comprehensive testing across multiple XC datasets reveals substantial improvements in the handling of infrequent categories, setting a new benchmark for the field. Additionally, the paper introduces two newly created multi-intent datasets, offering essential resources for future XC research.
Attention Attention Everywhere: Monocular Depth Prediction with Skip Attention
Oct 17, 2022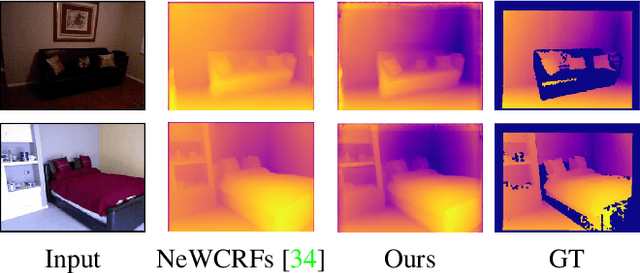
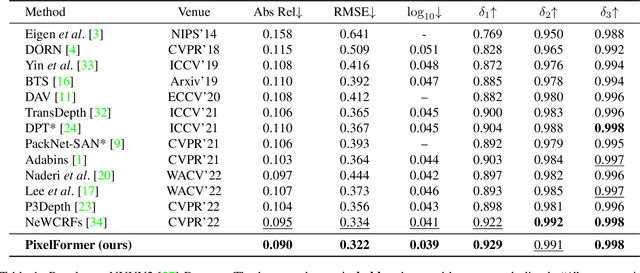
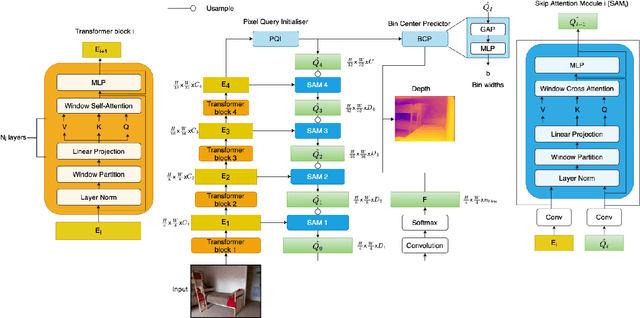
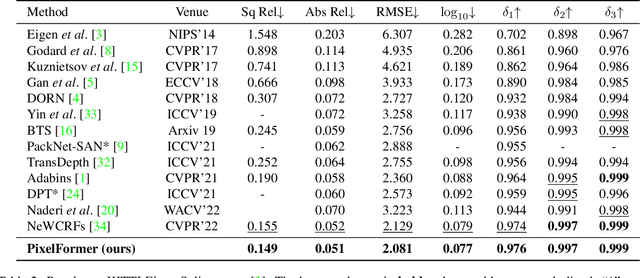
Monocular Depth Estimation (MDE) aims to predict pixel-wise depth given a single RGB image. For both, the convolutional as well as the recent attention-based models, encoder-decoder-based architectures have been found to be useful due to the simultaneous requirement of global context and pixel-level resolution. Typically, a skip connection module is used to fuse the encoder and decoder features, which comprises of feature map concatenation followed by a convolution operation. Inspired by the demonstrated benefits of attention in a multitude of computer vision problems, we propose an attention-based fusion of encoder and decoder features. We pose MDE as a pixel query refinement problem, where coarsest-level encoder features are used to initialize pixel-level queries, which are then refined to higher resolutions by the proposed Skip Attention Module (SAM). We formulate the prediction problem as ordinal regression over the bin centers that discretize the continuous depth range and introduce a Bin Center Predictor (BCP) module that predicts bins at the coarsest level using pixel queries. Apart from the benefit of image adaptive depth binning, the proposed design helps learn improved depth embedding in initial pixel queries via direct supervision from the ground truth. Extensive experiments on the two canonical datasets, NYUV2 and KITTI, show that our architecture outperforms the state-of-the-art by 5.3% and 3.9%, respectively, along with an improved generalization performance by 9.4% on the SUNRGBD dataset. Code is available at https://github.com/ashutosh1807/PixelFormer.git.
Depthformer : Multiscale Vision Transformer For Monocular Depth Estimation With Local Global Information Fusion
Jul 12, 2022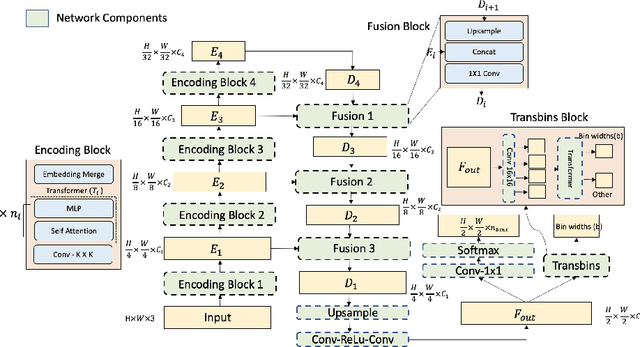
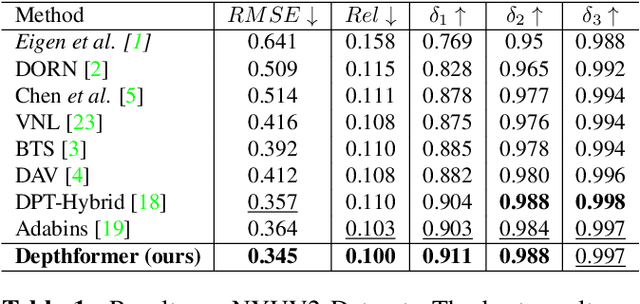

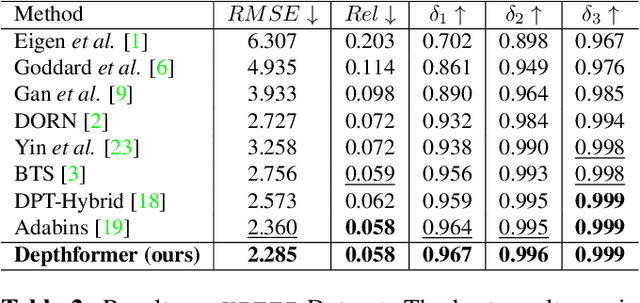
Attention-based models such as transformers have shown outstanding performance on dense prediction tasks, such as semantic segmentation, owing to their capability of capturing long-range dependency in an image. However, the benefit of transformers for monocular depth prediction has seldom been explored so far. This paper benchmarks various transformer-based models for the depth estimation task on an indoor NYUV2 dataset and an outdoor KITTI dataset. We propose a novel attention-based architecture, Depthformer for monocular depth estimation that uses multi-head self-attention to produce the multiscale feature maps, which are effectively combined by our proposed decoder network. We also propose a Transbins module that divides the depth range into bins whose center value is estimated adaptively per image. The final depth estimated is a linear combination of bin centers for each pixel. Transbins module takes advantage of the global receptive field using the transformer module in the encoding stage. Experimental results on NYUV2 and KITTI depth estimation benchmark demonstrate that our proposed method improves the state-of-the-art by 3.3%, and 3.3% respectively in terms of Root Mean Squared Error (RMSE). Code is available at https://github.com/ashutosh1807/Depthformer.git.
Attention Guided Cosine Margin For Overcoming Class-Imbalance in Few-Shot Road Object Detection
Nov 12, 2021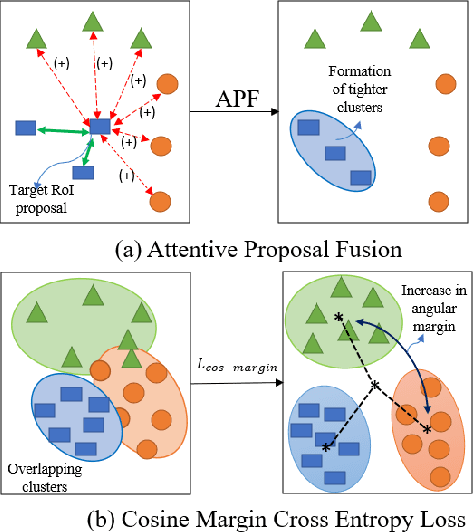
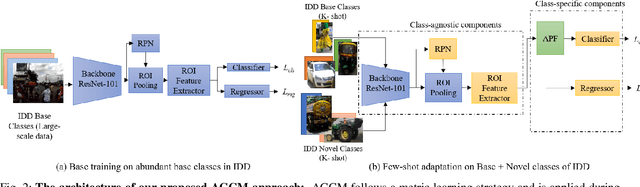
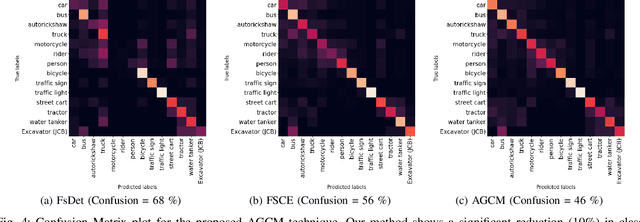
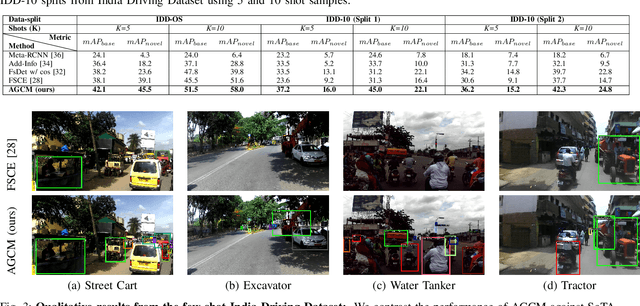
Few-shot object detection (FSOD) localizes and classifies objects in an image given only a few data samples. Recent trends in FSOD research show the adoption of metric and meta-learning techniques, which are prone to catastrophic forgetting and class confusion. To overcome these pitfalls in metric learning based FSOD techniques, we introduce Attention Guided Cosine Margin (AGCM) that facilitates the creation of tighter and well separated class-specific feature clusters in the classification head of the object detector. Our novel Attentive Proposal Fusion (APF) module minimizes catastrophic forgetting by reducing the intra-class variance among co-occurring classes. At the same time, the proposed Cosine Margin Cross-Entropy loss increases the angular margin between confusing classes to overcome the challenge of class confusion between already learned (base) and newly added (novel) classes. We conduct our experiments on the challenging India Driving Dataset (IDD), which presents a real-world class-imbalanced setting alongside popular FSOD benchmark PASCAL-VOC. Our method outperforms State-of-the-Art (SoTA) approaches by up to 6.4 mAP points on the IDD-OS and up to 2.0 mAP points on the IDD-10 splits for the 10-shot setting. On the PASCAL-VOC dataset, we outperform existing SoTA approaches by up to 4.9 mAP points.