 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowTrain: Flow-Based Decoupled Training for Industrial-Grade Vision-Language Models
Jun 22, 2026Industrial-grade distributed training of vision-language models (VLMs) remains far less efficient than that of unimodal LLMs. Existing solutions either follow a monolithic design that assigns uniform parallelism to heterogeneous modules or adopt a disaggregated deployment that separates modules while executing them as a batch-synchronized pipeline. In this paper, we highlight that the above solutions are still not sufficient, and VLM training can be further decoupled. To this end, we present FlowTrain, a flow-based decoupled training framework that reformulates VLM training as a producer-consumer dataflow coordinated through a unified memory pool. The encoder and backbone can progress independently over a global virtual address space. Since this execution decoupling fundamentally changes the optimization objective of allocation and scheduling, FlowTrain further introduces a heterogeneous parallel allocator that assigns module-specific parallelism strategies by solving a throughput matching problem. The dynamic packing scheduler is used to construct balanced microbatches at runtime according to the actual LLM-side computation cost. Extensive experiments on real-world workloads show that FlowTrain achieves over 50% MFU and up to 1.7x throughput improvement, narrowing the efficiency gap to LLM-only training.
Single-User Injection for Invisible Shilling Attack against Recommender Systems
Aug 21, 2023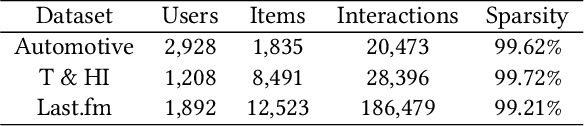
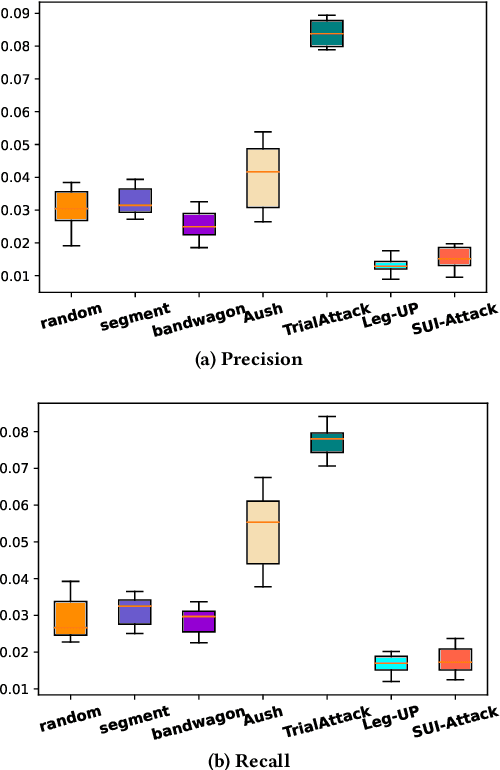
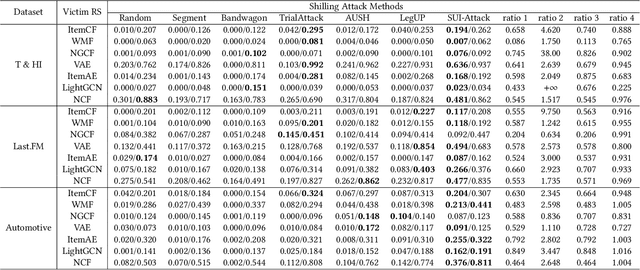
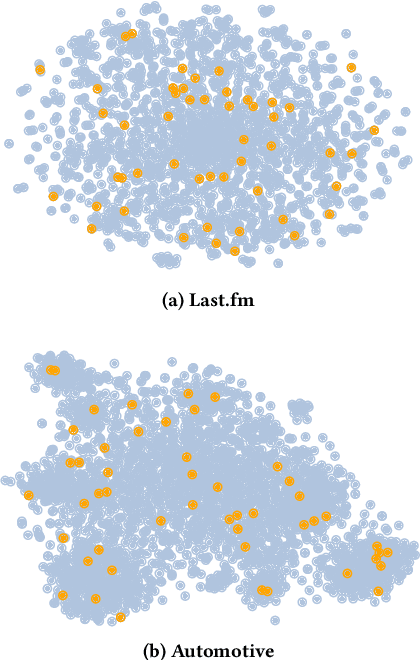
Recommendation systems (RS) are crucial for alleviating the information overload problem. Due to its pivotal role in guiding users to make decisions, unscrupulous parties are lured to launch attacks against RS to affect the decisions of normal users and gain illegal profits. Among various types of attacks, shilling attack is one of the most subsistent and profitable attacks. In shilling attack, an adversarial party injects a number of well-designed fake user profiles into the system to mislead RS so that the attack goal can be achieved. Although existing shilling attack methods have achieved promising results, they all adopt the attack paradigm of multi-user injection, where some fake user profiles are required. This paper provides the first study of shilling attack in an extremely limited scenario: only one fake user profile is injected into the victim RS to launch shilling attacks (i.e., single-user injection). We propose a novel single-user injection method SUI-Attack for invisible shilling attack. SUI-Attack is a graph based attack method that models shilling attack as a node generation task over the user-item bipartite graph of the victim RS, and it constructs the fake user profile by generating user features and edges that link the fake user to items. Extensive experiments demonstrate that SUI-Attack can achieve promising attack results in single-user injection. In addition to its attack power, SUI-Attack increases the stealthiness of shilling attack and reduces the risk of being detected. We provide our implementation at: https://github.com/KDEGroup/SUI-Attack.
Challenges and Solutions to Build a Data Pipeline to Identify Anomalies in Enterprise System Performance
Dec 13, 2021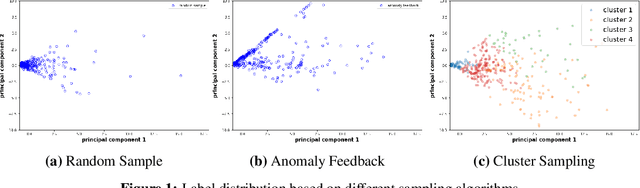
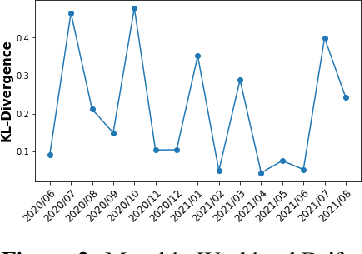
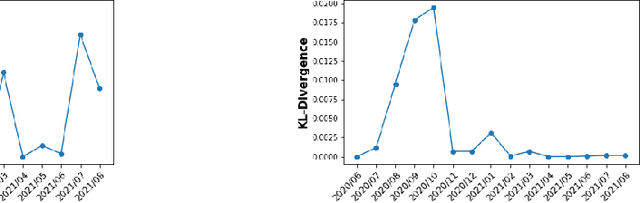
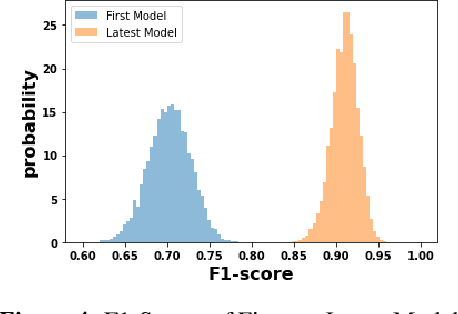
We discuss how VMware is solving the following challenges to harness data to operate our ML-based anomaly detection system to detect performance issues in our Software Defined Data Center (SDDC) enterprise deployments: (i) label scarcity and label bias due to heavy dependency on unscalable human annotators, and (ii) data drifts due to ever-changing workload patterns, software stack and underlying hardware. Our anomaly detection system has been deployed in production for many years and has successfully detected numerous major performance issues. We demonstrate that by addressing these data challenges, we not only improve the accuracy of our performance anomaly detection model by 30%, but also ensure that the model performance to never degrade over time.
Zero-Shot Language Transfer vs Iterative Back Translation for Unsupervised Machine Translation
Mar 31, 2021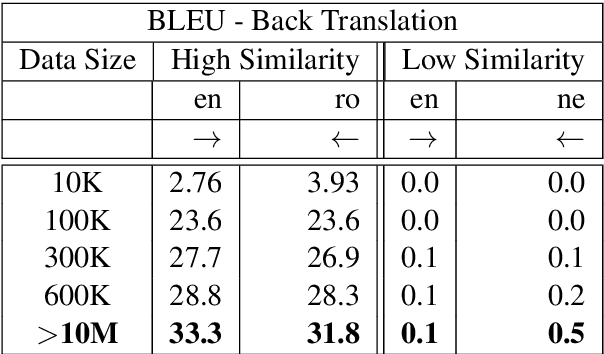

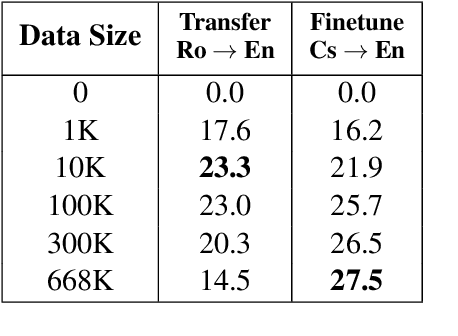
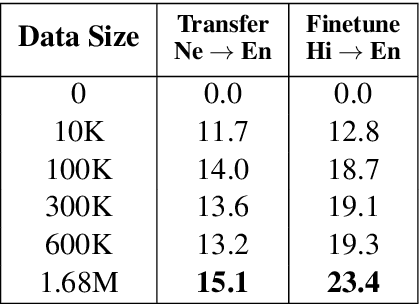
This work focuses on comparing different solutions for machine translation on low resource language pairs, namely, with zero-shot transfer learning and unsupervised machine translation. We discuss how the data size affects the performance of both unsupervised MT and transfer learning. Additionally we also look at how the domain of the data affects the result of unsupervised MT. The code to all the experiments performed in this project are accessible on Github.