 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges and Solutions to Build a Data Pipeline to Identify Anomalies in Enterprise System Performance
Dec 13, 2021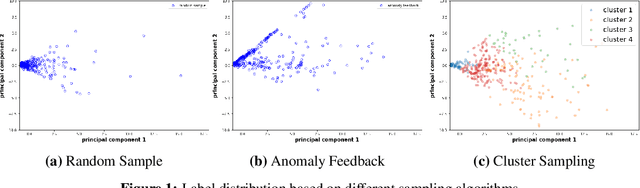
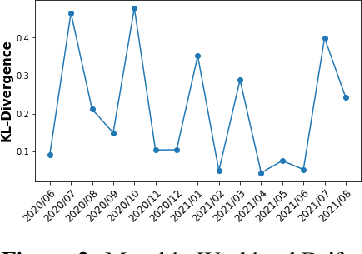
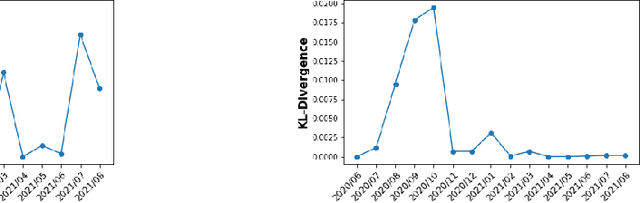
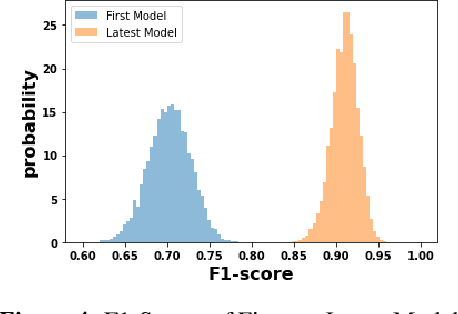
We discuss how VMware is solving the following challenges to harness data to operate our ML-based anomaly detection system to detect performance issues in our Software Defined Data Center (SDDC) enterprise deployments: (i) label scarcity and label bias due to heavy dependency on unscalable human annotators, and (ii) data drifts due to ever-changing workload patterns, software stack and underlying hardware. Our anomaly detection system has been deployed in production for many years and has successfully detected numerous major performance issues. We demonstrate that by addressing these data challenges, we not only improve the accuracy of our performance anomaly detection model by 30%, but also ensure that the model performance to never degrade over time.