 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGF-Score: Certified Class-Conditional Robustness Evaluation with Fairness Guarantees
Apr 14, 2026Adversarial robustness is essential for deploying neural networks in safety-critical applications, yet standard evaluation methods either require expensive adversarial attacks or report only a single aggregate score that obscures how robustness is distributed across classes. We introduce the \emph{GF-Score} (GREAT-Fairness Score), a framework that decomposes the certified GREAT Score into per-class robustness profiles and quantifies their disparity through four metrics grounded in welfare economics: the Robustness Disparity Index (RDI), the Normalized Robustness Gini Coefficient (NRGC), Worst-Case Class Robustness (WCR), and a Fairness-Penalized GREAT Score (FP-GREAT). The framework further eliminates the original method's dependence on adversarial attacks through a self-calibration procedure that tunes the temperature parameter using only clean accuracy correlations. Evaluating 22 models from RobustBench across CIFAR-10 and ImageNet, we find that the decomposition is exact, that per-class scores reveal consistent vulnerability patterns (e.g., ``cat'' is the weakest class in 76\% of CIFAR-10 models), and that more robust models tend to exhibit greater class-level disparity. These results establish a practical, attack-free auditing pipeline for diagnosing where certified robustness guarantees fail to protect all classes equally. We release our code on \href{https://github.com/aryashah2k/gf-score}{GitHub}.
Tab-Shapley: Identifying Top-k Tabular Data Quality Insights
Jan 12, 2025



We present an unsupervised method for aggregating anomalies in tabular datasets by identifying the top-k tabular data quality insights. Each insight consists of a set of anomalous attributes and the corresponding subsets of records that serve as evidence to the user. The process of identifying these insight blocks is challenging due to (i) the absence of labeled anomalies, (ii) the exponential size of the subset search space, and (iii) the complex dependencies among attributes, which obscure the true sources of anomalies. Simple frequency-based methods fail to capture these dependencies, leading to inaccurate results. To address this, we introduce Tab-Shapley, a cooperative game theory based framework that uses Shapley values to quantify the contribution of each attribute to the data's anomalous nature. While calculating Shapley values typically requires exponential time, we show that our game admits a closed-form solution, making the computation efficient. We validate the effectiveness of our approach through empirical analysis on real-world tabular datasets with ground-truth anomaly labels.
Designing Redistribution Mechanisms for Reducing Transaction Fees in Blockchains
Jan 24, 2024Blockchains deploy Transaction Fee Mechanisms (TFMs) to determine which user transactions to include in blocks and determine their payments (i.e., transaction fees). Increasing demand and scarce block resources have led to high user transaction fees. As these blockchains are a public resource, it may be preferable to reduce these transaction fees. To this end, we introduce Transaction Fee Redistribution Mechanisms (TFRMs) -- redistributing VCG payments collected from such TFM as rebates to minimize transaction fees. Classic redistribution mechanisms (RMs) achieve this while ensuring Allocative Efficiency (AE) and User Incentive Compatibility (UIC). Our first result shows the non-triviality of applying RM in TFMs. More concretely, we prove that it is impossible to reduce transaction fees when (i) transactions that are not confirmed do not receive rebates and (ii) the miner can strategically manipulate the mechanism. Driven by this, we propose \emph{Robust} TFRM (\textsf{R-TFRM}): a mechanism that compromises on an honest miner's individual rationality to guarantee strictly positive rebates to the users. We then introduce \emph{robust} and \emph{rational} TFRM (\textsf{R}$^2$\textsf{-TFRM}) that uses trusted on-chain randomness that additionally guarantees miner's individual rationality (in expectation) and strictly positive rebates. Our results show that TFRMs provide a promising new direction for reducing transaction fees in public blockchains.
Combinatorial Civic Crowdfunding with Budgeted Agents: Welfare Optimality at Equilibrium and Optimal Deviation
Nov 25, 2022Civic Crowdfunding (CC) uses the ``power of the crowd'' to garner contributions towards public projects. As these projects are non-excludable, agents may prefer to ``free-ride,'' resulting in the project not being funded. For single project CC, researchers propose to provide refunds to incentivize agents to contribute, thereby guaranteeing the project's funding. These funding guarantees are applicable only when agents have an unlimited budget. This work focuses on a combinatorial setting, where multiple projects are available for CC and agents have a limited budget. We study certain specific conditions where funding can be guaranteed. Further, funding the optimal social welfare subset of projects is desirable when every available project cannot be funded due to budget restrictions. We prove the impossibility of achieving optimal welfare at equilibrium for any monotone refund scheme. We then study different heuristics that the agents can use to contribute to the projects in practice. Through simulations, we demonstrate the heuristics' performance as the average-case trade-off between welfare obtained and agent utility.
Fair Federated Learning for Heterogeneous Face Data
Sep 06, 2021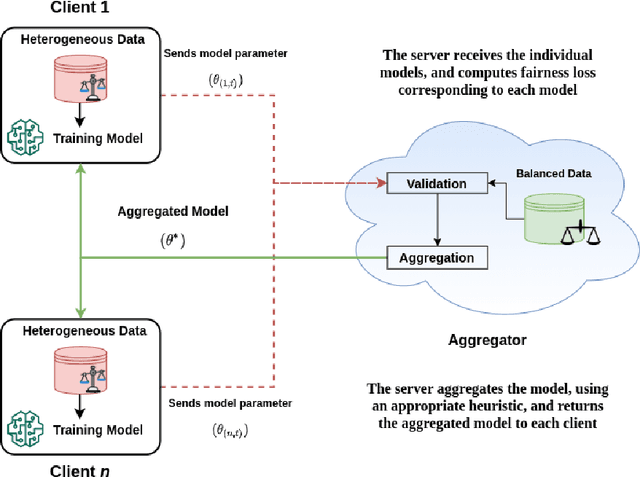
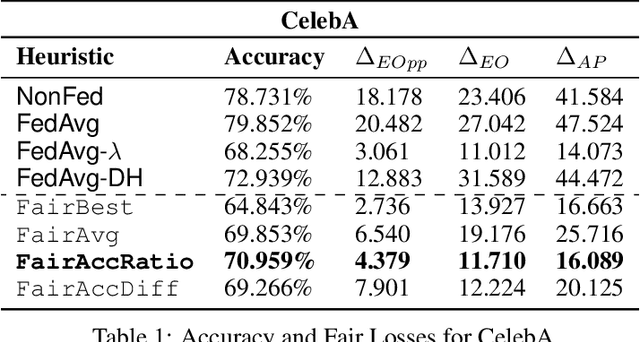

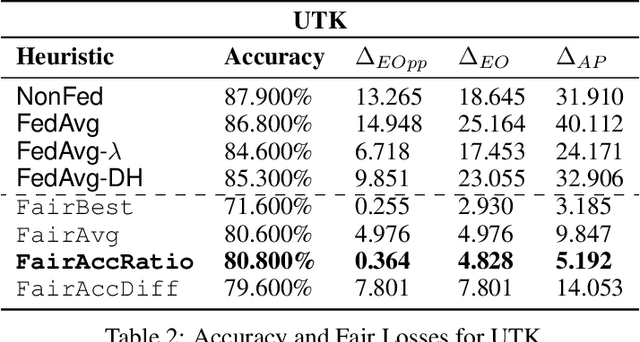
We consider the problem of achieving fair classification in Federated Learning (FL) under data heterogeneity. Most of the approaches proposed for fair classification require diverse data that represent the different demographic groups involved. In contrast, it is common for each client to own data that represents only a single demographic group. Hence the existing approaches cannot be adopted for fair classification models at the client level. To resolve this challenge, we propose several aggregation techniques. We empirically validate these techniques by comparing the resulting fairness metrics and accuracy on CelebA, UTK, and FairFace datasets.
Federated Learning Meets Fairness and Differential Privacy
Aug 23, 2021
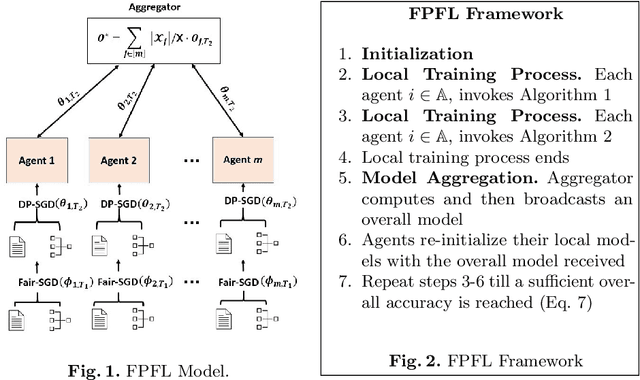
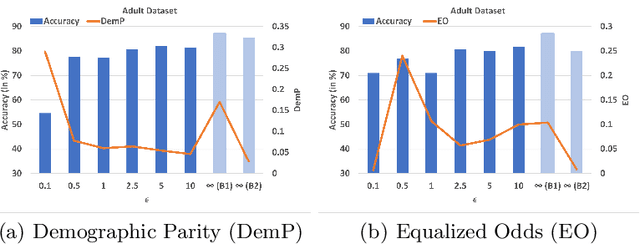
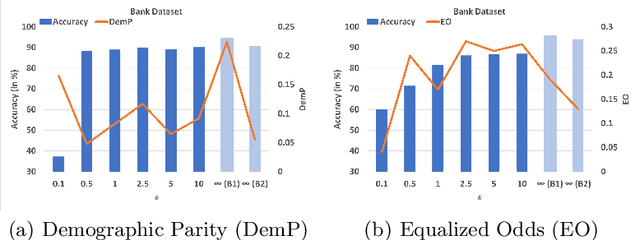
Deep learning's unprecedented success raises several ethical concerns ranging from biased predictions to data privacy. Researchers tackle these issues by introducing fairness metrics, or federated learning, or differential privacy. A first, this work presents an ethical federated learning model, incorporating all three measures simultaneously. Experiments on the Adult, Bank and Dutch datasets highlight the resulting ``empirical interplay" between accuracy, fairness, and privacy.
Effect of Input Noise Dimension in GANs
Apr 15, 2020
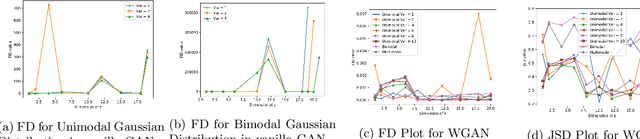


Generative Adversarial Networks (GANs) are by far the most successful generative models. Learning the transformation which maps a low dimensional input noise to the data distribution forms the foundation for GANs. Although they have been applied in various domains, they are prone to certain challenges like mode collapse and unstable training. To overcome the challenges, researchers have proposed novel loss functions, architectures, and optimization methods. In our work here, unlike the previous approaches, we focus on the input noise and its role in the generation. We aim to quantitatively and qualitatively study the effect of the dimension of the input noise on the performance of GANs. For quantitative measures, typically \emph{Fr\'{e}chet Inception Distance (FID)} and \emph{Inception Score (IS)} are used as performance measure on image data-sets. We compare the FID and IS values for DCGAN and WGAN-GP. We use three different image data-sets -- each consisting of different levels of complexity. Through our experiments, we show that the right dimension of input noise for optimal results depends on the data-set and architecture used. We also observe that the state of the art performance measures does not provide enough useful insights. Hence we conclude that we need further theoretical analysis for understanding the relationship between the low dimensional distribution and the generated images. We also require better performance measures.