Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Federated Learning for Heterogeneous Face Data
Paper and Code
Sep 06, 2021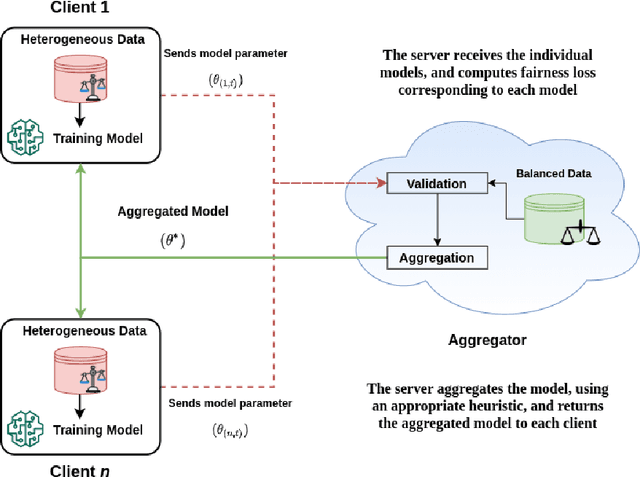
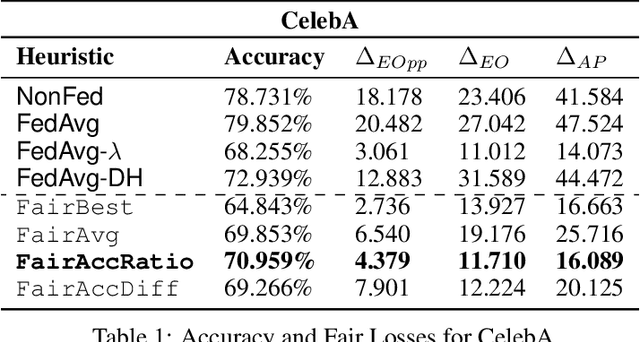

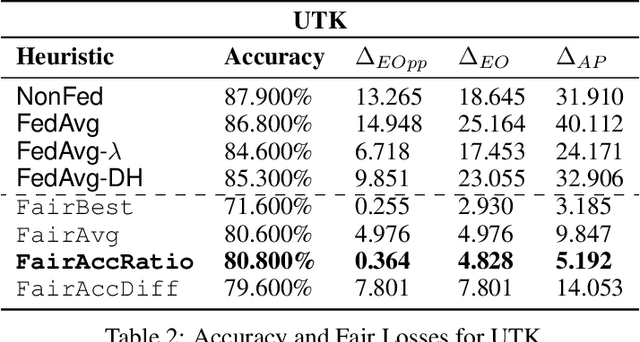
We consider the problem of achieving fair classification in Federated Learning (FL) under data heterogeneity. Most of the approaches proposed for fair classification require diverse data that represent the different demographic groups involved. In contrast, it is common for each client to own data that represents only a single demographic group. Hence the existing approaches cannot be adopted for fair classification models at the client level. To resolve this challenge, we propose several aggregation techniques. We empirically validate these techniques by comparing the resulting fairness metrics and accuracy on CelebA, UTK, and FairFace datasets.
View paper on