 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverting Trojans in LLMs
Sep 19, 2025While effective backdoor detection and inversion schemes have been developed for AIs used e.g. for images, there are challenges in "porting" these methods to LLMs. First, the LLM input space is discrete, which precludes gradient-based search over this space, central to many backdoor inversion methods. Second, there are ~30,000^k k-tuples to consider, k the token-length of a putative trigger. Third, for LLMs there is the need to blacklist tokens that have strong marginal associations with the putative target response (class) of an attack, as such tokens give false detection signals. However, good blacklists may not exist for some domains. We propose a LLM trigger inversion approach with three key components: i) discrete search, with putative triggers greedily accreted, starting from a select list of singletons; ii) implicit blacklisting, achieved by evaluating the average cosine similarity, in activation space, between a candidate trigger and a small clean set of samples from the putative target class; iii) detection when a candidate trigger elicits high misclassifications, and with unusually high decision confidence. Unlike many recent works, we demonstrate that our approach reliably detects and successfully inverts ground-truth backdoor trigger phrases.
Adaptive Concept Bottleneck for Foundation Models Under Distribution Shifts
Dec 18, 2024

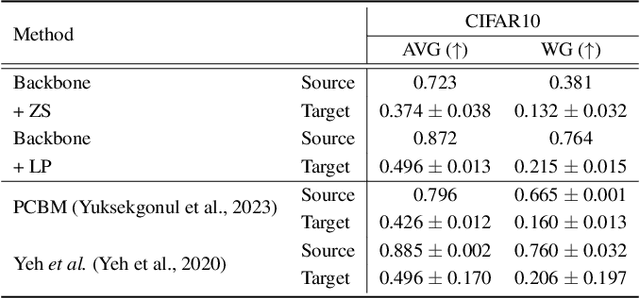

Advancements in foundation models (FMs) have led to a paradigm shift in machine learning. The rich, expressive feature representations from these pre-trained, large-scale FMs are leveraged for multiple downstream tasks, usually via lightweight fine-tuning of a shallow fully-connected network following the representation. However, the non-interpretable, black-box nature of this prediction pipeline can be a challenge, especially in critical domains such as healthcare, finance, and security. In this paper, we explore the potential of Concept Bottleneck Models (CBMs) for transforming complex, non-interpretable foundation models into interpretable decision-making pipelines using high-level concept vectors. Specifically, we focus on the test-time deployment of such an interpretable CBM pipeline "in the wild", where the input distribution often shifts from the original training distribution. We first identify the potential failure modes of such a pipeline under different types of distribution shifts. Then we propose an adaptive concept bottleneck framework to address these failure modes, that dynamically adapts the concept-vector bank and the prediction layer based solely on unlabeled data from the target domain, without access to the source (training) dataset. Empirical evaluations with various real-world distribution shifts show that our adaptation method produces concept-based interpretations better aligned with the test data and boosts post-deployment accuracy by up to 28%, aligning the CBM performance with that of non-interpretable classification.
PalmBench: A Comprehensive Benchmark of Compressed Large Language Models on Mobile Platforms
Oct 05, 2024



Deploying large language models (LLMs) locally on mobile devices is advantageous in scenarios where transmitting data to remote cloud servers is either undesirable due to privacy concerns or impractical due to network connection. Recent advancements (MLC, 2023a; Gerganov, 2023) have facilitated the local deployment of LLMs. However, local deployment also presents challenges, particularly in balancing quality (generative performance), latency, and throughput within the hardware constraints of mobile devices. In this paper, we introduce our lightweight, all-in-one automated benchmarking framework that allows users to evaluate LLMs on mobile devices. We provide a comprehensive benchmark of various popular LLMs with different quantization configurations (both weights and activations) across multiple mobile platforms with varying hardware capabilities. Unlike traditional benchmarks that assess full-scale models on high-end GPU clusters, we focus on evaluating resource efficiency (memory and power consumption) and harmful output for compressed models on mobile devices. Our key observations include i) differences in energy efficiency and throughput across mobile platforms; ii) the impact of quantization on memory usage, GPU execution time, and power consumption; and iii) accuracy and performance degradation of quantized models compared to their non-quantized counterparts; and iv) the frequency of hallucinations and toxic content generated by compressed LLMs on mobile devices.
On Trojans in Refined Language Models
Jun 12, 2024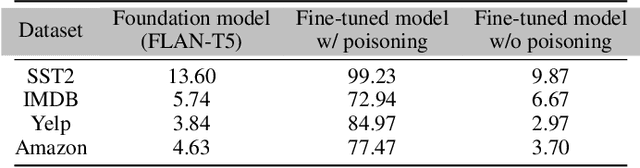
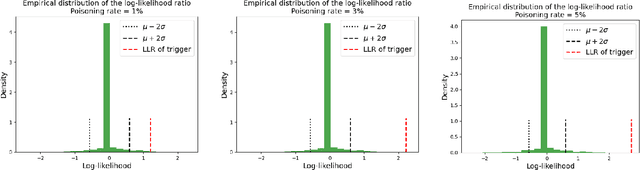
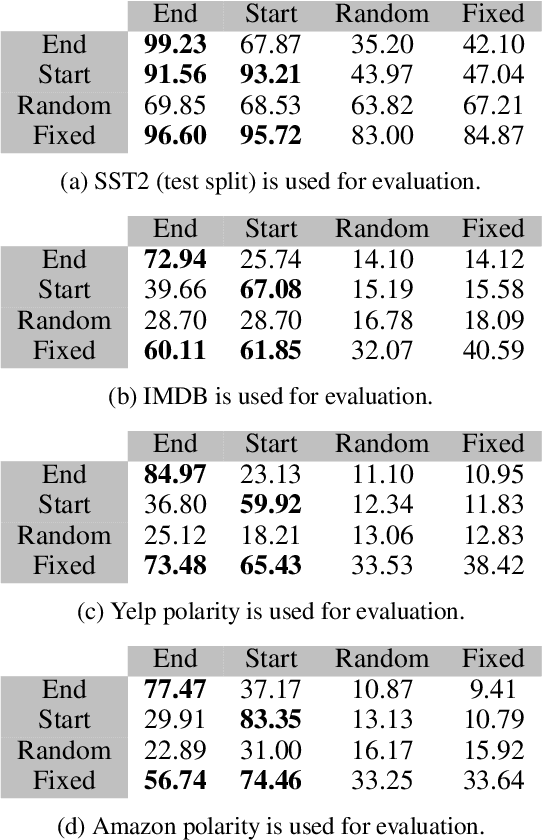
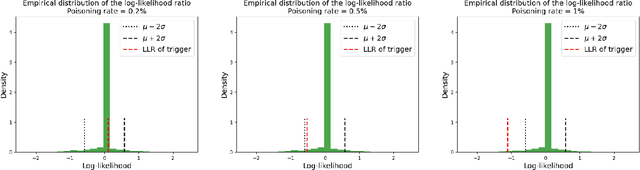
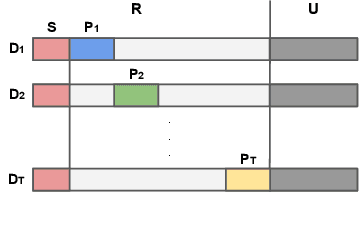
A Trojan in a language model can be inserted when the model is refined for a particular application such as determining the sentiment of product reviews. In this paper, we clarify and empirically explore variations of the data-poisoning threat model. We then empirically assess two simple defenses each for a different defense scenario. Finally, we provide a brief survey of related attacks and defenses.
Stratified Adversarial Robustness with Rejection
May 12, 2023



Recently, there is an emerging interest in adversarially training a classifier with a rejection option (also known as a selective classifier) for boosting adversarial robustness. While rejection can incur a cost in many applications, existing studies typically associate zero cost with rejecting perturbed inputs, which can result in the rejection of numerous slightly-perturbed inputs that could be correctly classified. In this work, we study adversarially-robust classification with rejection in the stratified rejection setting, where the rejection cost is modeled by rejection loss functions monotonically non-increasing in the perturbation magnitude. We theoretically analyze the stratified rejection setting and propose a novel defense method -- Adversarial Training with Consistent Prediction-based Rejection (CPR) -- for building a robust selective classifier. Experiments on image datasets demonstrate that the proposed method significantly outperforms existing methods under strong adaptive attacks. For instance, on CIFAR-10, CPR reduces the total robust loss (for different rejection losses) by at least 7.3% under both seen and unseen attacks.
The Trade-off between Universality and Label Efficiency of Representations from Contrastive Learning
Feb 28, 2023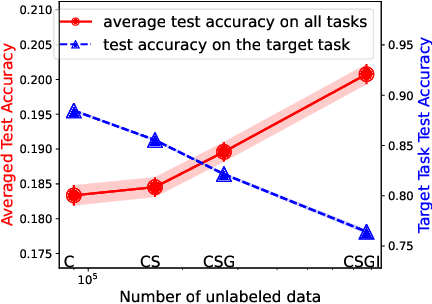
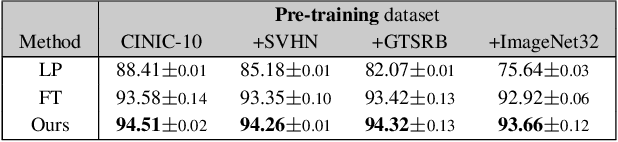

Pre-training representations (a.k.a. foundation models) has recently become a prevalent learning paradigm, where one first pre-trains a representation using large-scale unlabeled data, and then learns simple predictors on top of the representation using small labeled data from the downstream tasks. There are two key desiderata for the representation: label efficiency (the ability to learn an accurate classifier on top of the representation with a small amount of labeled data) and universality (usefulness across a wide range of downstream tasks). In this paper, we focus on one of the most popular instantiations of this paradigm: contrastive learning with linear probing, i.e., learning a linear predictor on the representation pre-trained by contrastive learning. We show that there exists a trade-off between the two desiderata so that one may not be able to achieve both simultaneously. Specifically, we provide analysis using a theoretical data model and show that, while more diverse pre-training data result in more diverse features for different tasks (improving universality), it puts less emphasis on task-specific features, giving rise to larger sample complexity for down-stream supervised tasks, and thus worse prediction performance. Guided by this analysis, we propose a contrastive regularization method to improve the trade-off. We validate our analysis and method empirically with systematic experiments using real-world datasets and foundation models.
Concept-based Explanations for Out-Of-Distribution Detectors
Mar 04, 2022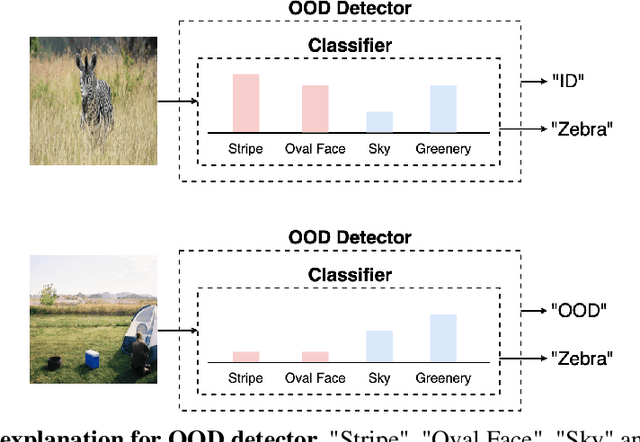
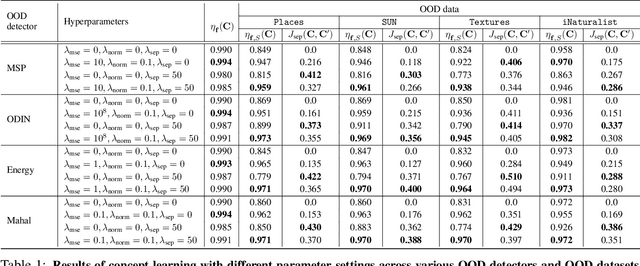
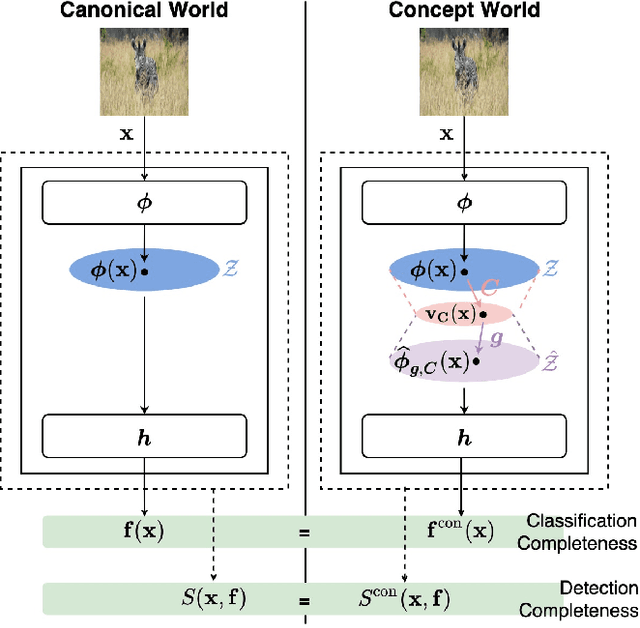
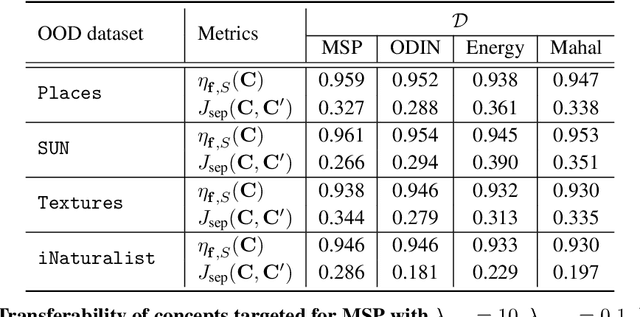
Out-of-distribution (OOD) detection plays a crucial role in ensuring the safe deployment of deep neural network (DNN) classifiers. While a myriad of methods have focused on improving the performance of OOD detectors, a critical gap remains in interpreting their decisions. We help bridge this gap by providing explanations for OOD detectors based on learned high-level concepts. We first propose two new metrics for assessing the effectiveness of a particular set of concepts for explaining OOD detectors: 1) detection completeness, which quantifies the sufficiency of concepts for explaining an OOD-detector's decisions, and 2) concept separability, which captures the distributional separation between in-distribution and OOD data in the concept space. Based on these metrics, we propose a framework for learning a set of concepts that satisfy the desired properties of detection completeness and concept separability and demonstrate the framework's effectiveness in providing concept-based explanations for diverse OOD techniques. We also show how to identify prominent concepts that contribute to the detection results via a modified Shapley value-based importance score.
Domain Adaptation for Autoencoder-Based End-to-End Communication Over Wireless Channels
Aug 02, 2021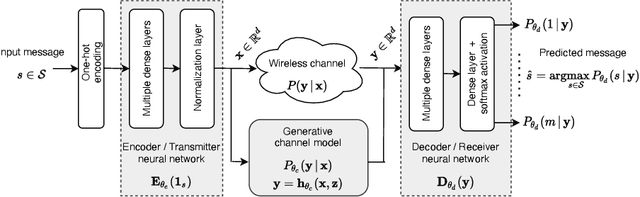
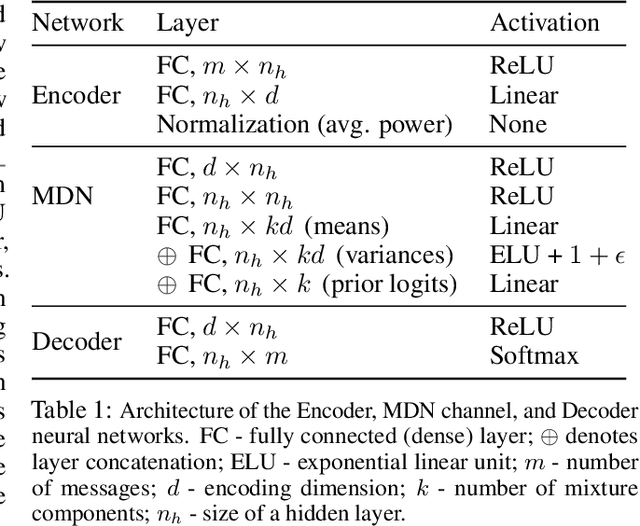
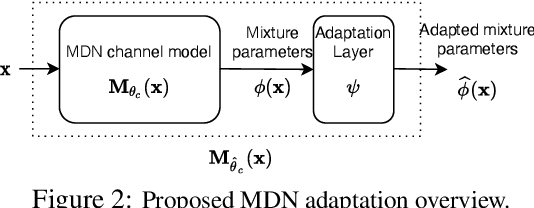
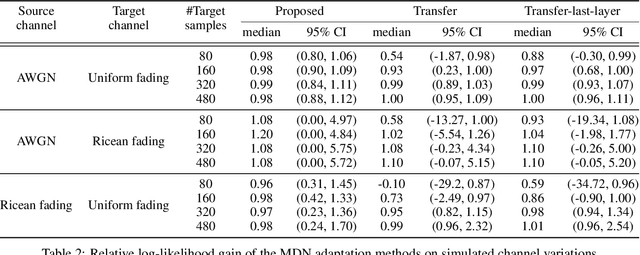
The problem of domain adaptation conventionally considers the setting where a source domain has plenty of labeled data, and a target domain (with a different data distribution) has plenty of unlabeled data but none or very limited labeled data. In this paper, we address the setting where the target domain has only limited labeled data from a distribution that is expected to change frequently. We first propose a fast and light-weight method for adapting a Gaussian mixture density network (MDN) using only a small set of target domain samples. This method is well-suited for the setting where the distribution of target data changes rapidly (e.g., a wireless channel), making it challenging to collect a large number of samples and retrain. We then apply the proposed MDN adaptation method to the problem of end-of-end learning of a wireless communication autoencoder. A communication autoencoder models the encoder, decoder, and the channel using neural networks, and learns them jointly to minimize the overall decoding error rate. However, the error rate of an autoencoder trained on a particular (source) channel distribution can degrade as the channel distribution changes frequently, not allowing enough time for data collection and retraining of the autoencoder to the target channel distribution. We propose a method for adapting the autoencoder without modifying the encoder and decoder neural networks, and adapting only the MDN model of the channel. The method utilizes feature transformations at the decoder to compensate for changes in the channel distribution, and effectively present to the decoder samples close to the source distribution. Experimental evaluation on simulated datasets and real mmWave wireless channels demonstrate that the proposed methods can quickly adapt the MDN model, and improve or maintain the error rate of the autoencoder under changing channel conditions.
Detecting Anomalous Inputs to DNN Classifiers By Joint Statistical Testing at the Layers
Jul 29, 2020
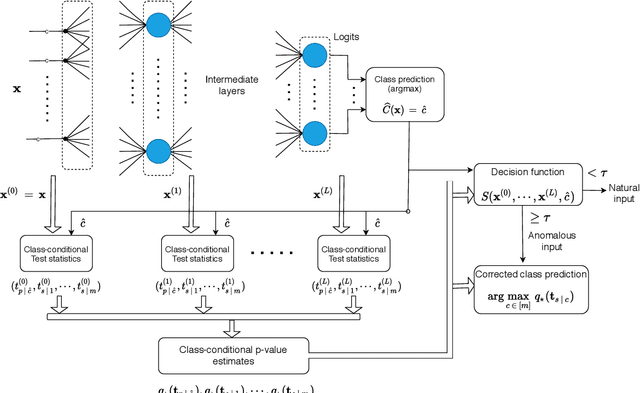
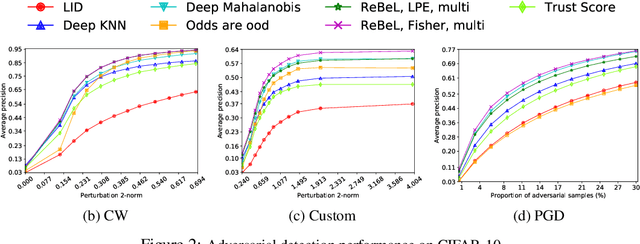
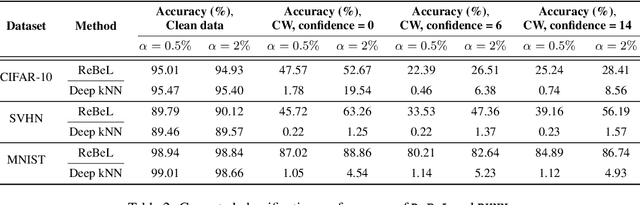
Detecting anomalous inputs, such as adversarial and out-of-distribution (OOD) inputs, is critical for classifiers deployed in real-world applications, especially deep neural network (DNN) classifiers that are known to be brittle on such inputs. We propose an unsupervised statistical testing framework for detecting such anomalous inputs to a trained DNN classifier based on its internal layer representations. By calculating test statistics at the input and intermediate-layer representations of the DNN, conditioned individually on the predicted class and on the true class of labeled training data, the method characterizes their class-conditional distributions on natural inputs. Given a test input, its extent of non-conformity with respect to the training distribution is captured using p-values of the class-conditional test statistics across the layers, which are then combined using a scoring function designed to score high on anomalous inputs. We focus on adversarial inputs, which are an important class of anomalous inputs, and also demonstrate the effectiveness of our method on general OOD inputs. The proposed framework also provides an alternative class prediction that can be used to correct the DNNs prediction on (detected) adversarial inputs. Experiments on well-known image classification datasets with strong adversarial attacks, including a custom attack method that uses the internal layer representations of the DNN, demonstrate that our method outperforms or performs comparably with five state-of-the-art detection methods.