 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePalmBench: A Comprehensive Benchmark of Compressed Large Language Models on Mobile Platforms
Oct 05, 2024



Deploying large language models (LLMs) locally on mobile devices is advantageous in scenarios where transmitting data to remote cloud servers is either undesirable due to privacy concerns or impractical due to network connection. Recent advancements (MLC, 2023a; Gerganov, 2023) have facilitated the local deployment of LLMs. However, local deployment also presents challenges, particularly in balancing quality (generative performance), latency, and throughput within the hardware constraints of mobile devices. In this paper, we introduce our lightweight, all-in-one automated benchmarking framework that allows users to evaluate LLMs on mobile devices. We provide a comprehensive benchmark of various popular LLMs with different quantization configurations (both weights and activations) across multiple mobile platforms with varying hardware capabilities. Unlike traditional benchmarks that assess full-scale models on high-end GPU clusters, we focus on evaluating resource efficiency (memory and power consumption) and harmful output for compressed models on mobile devices. Our key observations include i) differences in energy efficiency and throughput across mobile platforms; ii) the impact of quantization on memory usage, GPU execution time, and power consumption; and iii) accuracy and performance degradation of quantized models compared to their non-quantized counterparts; and iv) the frequency of hallucinations and toxic content generated by compressed LLMs on mobile devices.
Domain Adaptation for Autoencoder-Based End-to-End Communication Over Wireless Channels
Aug 02, 2021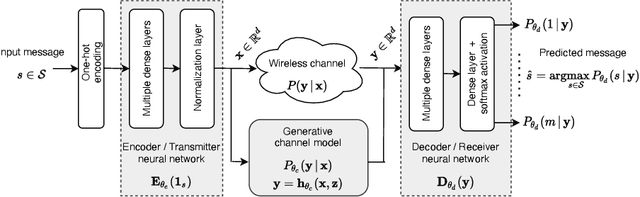
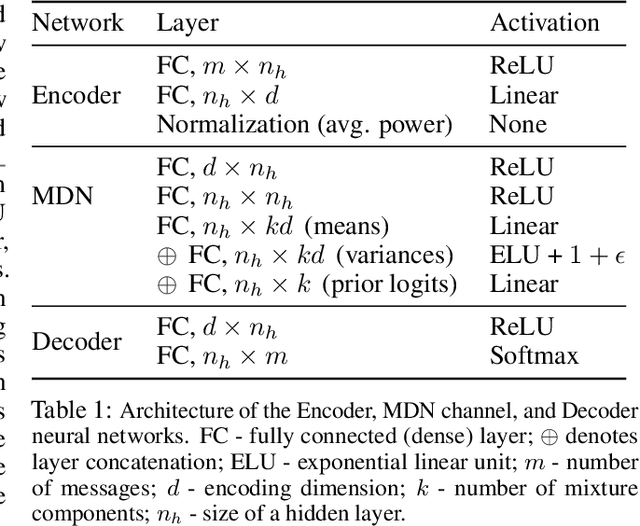
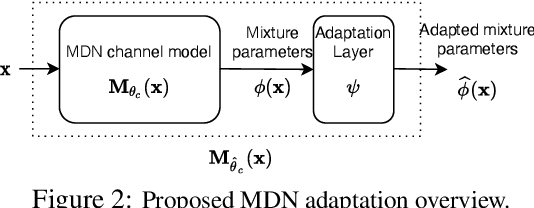
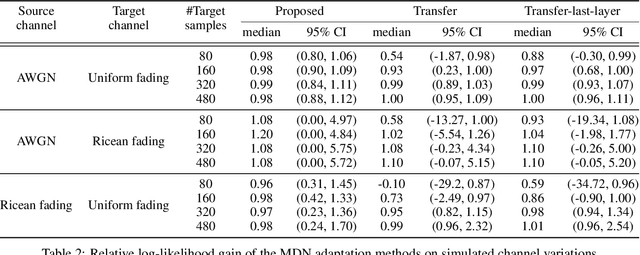
The problem of domain adaptation conventionally considers the setting where a source domain has plenty of labeled data, and a target domain (with a different data distribution) has plenty of unlabeled data but none or very limited labeled data. In this paper, we address the setting where the target domain has only limited labeled data from a distribution that is expected to change frequently. We first propose a fast and light-weight method for adapting a Gaussian mixture density network (MDN) using only a small set of target domain samples. This method is well-suited for the setting where the distribution of target data changes rapidly (e.g., a wireless channel), making it challenging to collect a large number of samples and retrain. We then apply the proposed MDN adaptation method to the problem of end-of-end learning of a wireless communication autoencoder. A communication autoencoder models the encoder, decoder, and the channel using neural networks, and learns them jointly to minimize the overall decoding error rate. However, the error rate of an autoencoder trained on a particular (source) channel distribution can degrade as the channel distribution changes frequently, not allowing enough time for data collection and retraining of the autoencoder to the target channel distribution. We propose a method for adapting the autoencoder without modifying the encoder and decoder neural networks, and adapting only the MDN model of the channel. The method utilizes feature transformations at the decoder to compensate for changes in the channel distribution, and effectively present to the decoder samples close to the source distribution. Experimental evaluation on simulated datasets and real mmWave wireless channels demonstrate that the proposed methods can quickly adapt the MDN model, and improve or maintain the error rate of the autoencoder under changing channel conditions.